1 原文作者
Yaqing Wang(State University of New York at Buffalo, New York, USA), Weifeng Yang(Data Quality Team, WeChat, Tencent Inc., China), Fenglong Ma(Pennsylvania State University, Pennsylvania, USA), Jin Xu(Data Quality Team, WeChat, Tencent Inc., China), Bin Zhong(Data Quality Team, WeChat, Tencent Inc., China), Qiang Deng(Data Quality Team, WeChat, Tencent Inc., China), Jing Gao(State University of New York at Buffalo, New York, USA)
2 论文来源
AAAI Conference on Artificial Intelligence(2020)
3 论文地址
https://ojs.aaai.org/index.php/AAAI/article/view/5389/5245
4 论文简介
(1)研究背景:社交媒体已成为新闻的主要来源。通过社交媒体平台,虚假新闻以前所未有的速度传播到全球受众,并使用户和社区面临巨大风险。因此尽早识别出虚假新闻非常重要。和传统方法相比,深度学习方法由于其能自动为新闻学习到信息丰富的表示形式而获得了很大的效果提升。但是却需要大量已标记样本,而对于虚假识别任务还存在一个问题——时效性。因此,如何获得新鲜且高质量的标记样本是将深度学习模型用于虚假新闻检测的主要挑战。
(2)研究内容:网络媒体中的假新闻自动化检测问题。
(3)研究结论:开展了基于弱监督的假新闻检测研究提出了一种新颖的框架,可以利用用户报告作为假新闻检测的弱监督依据,取得了很好的效果。
5 解决问题
(1)试图解决的问题:深度学习方法缺少大量高质量的假新闻标注数据。
(2)假新闻检测的深度学习方法:
- 基于社交上下文特征的检测方法:社交环境特征是指社交媒体上的用户参与情况,包括粉丝数量,标签,网络结构等。但是,社交环境特征只能在经过一段累积的时间后才能提取,因此不能用于及时发现新出现的虚假新闻。
- 基于内容特征的检测方法:新闻内容特征是从新闻文本内容中提取的统计或语义特征。 已有学者分别基于新闻文本和多模式数据识别假新闻提出了深度学习模型。这些模型已经在检测性能上得到显著提高,但是由于缺少新鲜的高质量训练样本,深度学习模型的功能尚未完全释放。
- 引入众包信号的方法:通常的做法为基于预测概率建立选择器,存在的不足为新闻文章的分布会随着时间变化,从而预测概率的分布是多变的。
6 本文贡献
- 创新性地提出了一种基于用户报告的弱监督假新闻检测方法。
- 提出了一个全新的检测框架WeFEND,能够自动标注数据,扩大数据规模。
- 引入强化学习,提出了一种基于效果的选择器构建方法。
7 论文方法
- 标注器
标注器可以看作是在有标签的新闻上的预训练模型。基于预训练模型,可以为未标记的样本分配弱标记。由于一篇新闻文章可能有来自多个用户的报道,因此对同一个样本要汇总其不同报道中获得的信息。由于来自多个用户的关于一条新闻的报告消息是次序无关的,因此聚合单元由与次序无关的聚合函数和完全连接层组成。聚合函数可以是求和,均值和最大池化。
- 选择器
数据选择器的目的是自动从注释者获得的带有弱标签的样本中选择高质量的样本。选择的依据是添加所选样本是否可以提高假新闻检测性能。根据此标准,文中使用增强学习机制设计了一种性能驱动的数据选择方法(称为增强数据选择器)。
文章认为使用多个小袋样本可以向选择器提供更多反馈,使得强化学习的训练过程更加有效。
在数据选择过程中,将一个袋子中的样本依次送入设计的增强型数据选择器中。对于每个样本,增强数据选择器选择保留或删除。由于数据选择的目的是提高虚假新闻检测的性能,因此直接使用虚假新闻检测的性能变化作为加强选择器的奖励。性能通过准确性进行评估。对于此决策过程,奖励将被延迟,因为只有在做出所有决策后才能获得奖励。为了解决延迟奖励问题,文中采用了基于策略的强化学习机制。由于增强型选择器需要使用虚假新闻检测器的性能变化作为奖励,因此先介绍虚假新闻检测器。
- 检测器
虚假新闻检测模型是一个神经网络,由文本特征提取器和具有相应激活功能的完全连接的层组成。假新闻检测器的输入是新闻内容,输出是给定新闻是假的概率。
- 状态
由于每次选择的动作都是基于当前样本和已选样本进行的,因此状态向量由两个部分组成:当前样本的表示和所选样本的平均表示。
当前样本的表示与数据质量和多样性有关。文中用注释器和伪造新闻检测器的输出概率来衡量数据的质量;计算当前样本与所有选定样本之间的余弦相似度表示数据多样性。为了平衡类的分布,当前样本的弱标签也用作表示的一部分。因此,当前状态向量包含四个元素:1)注释者的输出概率; 2)假新闻检测器的输出概率;3)当前样本和所选样本的余弦相似度;4)当前样本的弱标签。
按照上述方法,将已选样本表示为所有已选样本的平均。将当前样本和已选样本的表示拼接,得到最终的状态向量。
8 实验结果
实验使用的数据集从微信官方账户中收集。由于标题可以看作是新闻内容的摘要,因此在手动注释过程中,专家仅查看标题进行标记。同样,仅使用标题代替全文输入到文本特征提取器中。
- 实验结果1
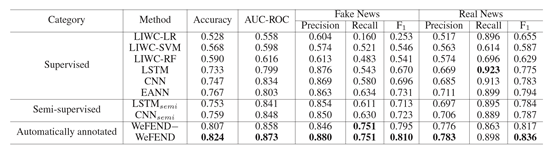
结论:
- 深度学习模型表现比机器学习好。
- EANN表现比LSTM和CNN好,因为它能学习到与事件无关的新闻特征。
- 在半监督模型中,作者加入了不带标签的数据。结果表明,这种方式能够扩大训练集的数据规模,并提升效果。
- 弱监督的标签不可避免地会带来噪音,所以引入数据选择器的wefend框架表现更好。
- 实验结果2

结论:
- 在实验中比较了不同时间窗口下的特征表示不同以及模型性能的不同,证明了新闻的分布具有动态性,因此说明了应该及时标注和新出现事件相关的新闻。
- 实验证明了用户反馈信息的有效性,使用这一信息,标注器在相同和不同时间窗口对应的数据上,有着相似的表现。并且用户反馈信息的特征不具有随时间变化的动态性。
- 训练集和测试集的数据在时间上并不相交,因此可以验证模型对新鲜数据进行分类的效果。
- 实验结果3
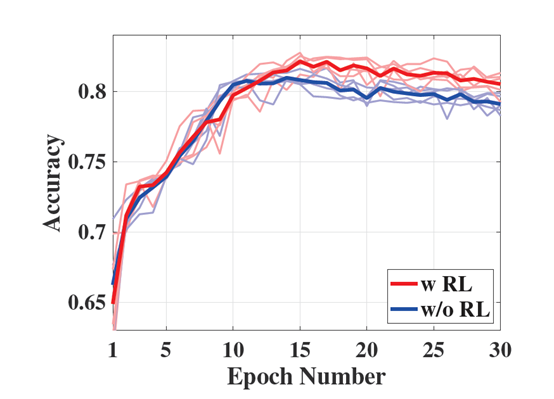
结论:设计的增强型选择器可以有效提高假新闻检测的性能。本文不足
- 本文不足:
- 在人工标注时仅根据标题(headline)信息,因此模型中也是仅使用标题作为输入数据,而没有考虑新闻文章具体内容。
(2)可改进方面:
- 标注器部分对同一篇新闻的所有用户评论信息进行了聚合,作者使用的是平均操作作为无序的聚合函数。可以考虑在聚合时使用注意力机制。
10 代码和数据集地址
https://github.com/yaqingwang/WeFEND- AAAI20