阅读笔记作者:金地
1 原文作者
Xiao-Kun Wu (School of Journalism & Communication, South China University of Technology, China),
Tian-Fang Zhao (School of Journalism & Communication, Jinan University, China),
Lu Lu (School of Computer Science and Engineering, South China University of Technology, China),
Wei-Neng Chen (School of Computer Science and Engineering, South China University of Technology, China),
2 论文来源
IPM 2022 (CCF-B)
3 论文地址
4 论文简介
- 研究背景
- COVID-19期间,社交媒体记录了全球大流行期间的在线事件和公众仇恨言论;
- 在复杂的情绪中,最主要、最具破坏性的是仇恨情绪,它导致了社会不平等、地域歧视、种族偏见等的加剧;
- 作为一种抽象存在,仇恨情绪很容易被感知,但却不容易被准确度量。
- 研究动机
现有的对社交媒体中仇恨言论的分析可以大致分为两类:
- 分析语义、语境、仇恨言论的符号,并结合社会学理论进行解释。
这类研究具有良好的社会学意义,但研究成果的拓展和积累相对薄弱。研究结论和结果不能直接转移到其他案例。
- 对仇恨言论进行检测、识别和预测
这类研究更加注重方法,但对研究成果的解读相对简单,缺乏深入探讨。
跨学科研究可以突破上述两类研究瓶颈。
社会科学角度——全面收集和分析社会数据,发现信息传播规律,得出社会学结论【全面分析COVID中的仇恨情绪】
计算科学角度——将研究成果的规律和结论转化为可重用的模型和方法【进行自动化的形势分析和规律揭示,有助于预防社会危机】
5 解决问题
社会科学角度——全面收集和分析社会数据,发现信息传播规律,得出社会学结论【全面分析COVID中的仇恨情绪】
计算科学角度——将研究成果的规律和结论转化为可重用的模型和方法【进行自动化的形势分析和规律揭示,有助于预防社会危机】
6 本文贡献
- 对COVID中的仇恨言论进行系统分析:发现仇恨言论的意见领袖和事件趋势,并总结出仇恨言论演变的基本时空特征。
- 构建了一个数据驱动的仇恨言论趋势预测模型:根据观察到的规律,建立了一个预测舆论趋势的高斯时空混合模型,以便将观察到的规律转化为方法。
- 在数据集中验证了所提模型的效果:在COVID-Hate数据集上对模型进行测试,结果显示模型能够很好地拟合客观民意的趋势。
7 论文方法
本文提出高斯时空混合模型GSTM,共分为时间原理、空间原理、混合部分三个部分。
- GSTM模型的时间原理
时间测量主要是用来估计曝光峰和情绪峰之间的平均时间。在X轴上考虑了两个时间序列:由T_1=[t_1,1,t_1,2,…,t_(1,m)]构成的曝光峰,以及由T_2=[t_2,1,t_2,2,…,t_(2,m)]构成的每个曝光峰后的相应推文高峰(m>=1),各高峰之间的时间间隔为:
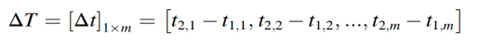
根据前期的分析,间隔时间的数值围绕一个固定点波动,符合高斯分布。因此,曝光峰和鸣叫峰之间的时间间隔的概率分布由以下公式表示。
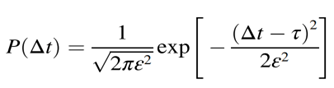
每个参与者在其阶段影响波峰。设t时间的曝光量表示为F(t),在随后的周期中继续引起波峰的增加或减少,∆t(0≤∆t≤μ)日曝光的推文数量表示为N(t+∆t),则可用公式计算:
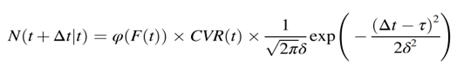
对于某一个t,前几天的曝光会持续影响这一天的推文数量。
空间原理描述的是一天的曝光量对后面几天的推文浪潮的影响,而模型的混合部分则是根据之前的曝光量和推文数量来计算特定一天的推文数量。
混合部分是进行预测的关键。N ̂(t)代表第t天的预测推文数量,其计算方法是:
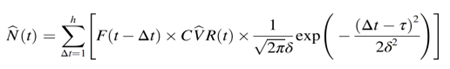
1) 数据集
COVID-HATE数据集(公开数据集):2.06亿tweets-id及对应的标签(仇恨/中立/反仇恨)
从中选出6,548,325个tweets-id及其地理标签形成GEO-COVOD-HATE数据集,其中包括64,749条仇恨言论,6,448,977条中立言论,34,605条反仇恨言论,并通过Twitter-API进一步收集推文及其发布者的信息。
2) 评价指标
残差RES
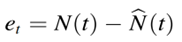
残差平均值Mean
均方根误差RMSE
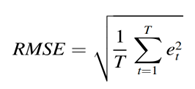
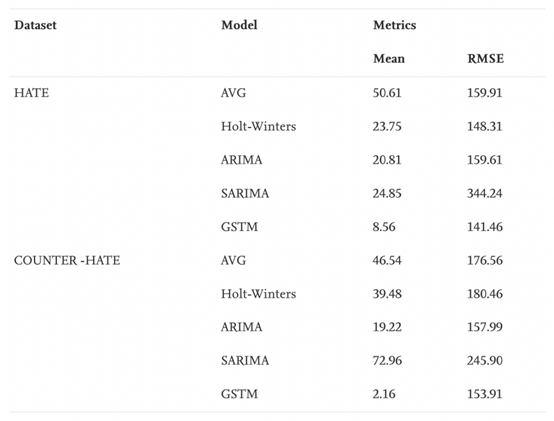
1) 模型对比
Averaging Model (AVG) 平均模型
Holt-Winters Model 一种经典的指数平滑算法
ARIMA 差分自回归滑动平均模型
SARIMA 季节性差分自回归滑动平均模型,ARIMA的扩展版本
在所有的实验中,只保留7天(即一周)的观测数据来预测第2天的趋势。
时间规律在集体行动预测和情绪趋势预测中具有一些共性。GSTM也可以预测社交媒体上出现的其他重要情绪。
在仇恨言论检测中,应注意用户关注者的情况。
10 代码和数据集地址
无