1.论文来源
AAAI (2020)(CCF-A类会议)
2.论文题目
Neural Simile Recognition with Cyclic Multitask Learning and Local Attention
基于循环多任务学习和局部注意力的明喻识别
3.论文作者
Jiali Zeng:Xiamen University, Xiamen, China
Linfeng Song:TencentAI Lab, Bellevue, USA
Jun Xie:Mobile Internet Group, Tencent Technology
Wei Song:Capital Normal University, Beijing, China
Jiebo Luo:University of Rochester, Rochester NY, USA
4.论文地址
5.论文简介
明喻识别是对明喻句进行检测,并提取明喻成分,即喻体和喻体。它包括两个子任务:明喻句子分类和明喻成分提取。近年来的研究表明,标准多任务学习对于中文明喻识别是有效的,但简单的参数共享是否能很好地捕捉子任务之间的相互影响仍不确定。该文提出了一种新的循环多任务学习框架,用于神经明喻识别,该框架将子任务堆叠起来,并通过连接最后一个和第一个任务使它们成为一个循环。它迭代地执行每一个子任务,将前一个子任务的输出作为当前子任务的额外输入,以便更好地探索子任务之间的相互依赖关系。大量的实验表明,该文的框架明显优于当前最先进的模型和其他的基线,并且使用BERT的收益仍然是显著的.
6.解决问题
1.明喻句子具有与正常句子的非常相似的句法和语义结构,阻碍了传统的自然语言理解技术的可行性,如句法和语义解析。
2.虽然比较词(比如、就像,好像)可以提供一些提示,但它们也经常被用于字面比较,这给这个任务带来了很大的模糊性。
7.本文贡献
1.提出了一种新的循环多任务学习框架用于明喻识别。与标准多任务学习相比较,该框架较好地建模了其子任务之间的相互关联。
2.引入了用于明喻性分类的局部注意机制。
3.框架显示出优于传统的基线模型,无论是否使用预先训练模型BERT进行词向量编码。
8.论文方法
1.由于在明喻句子分类任务中,潜在的明喻成分通常得到较高的注意力权重,所以利用明喻句子分类器中与潜在本体和载体(注意力分布)相关的信息,明喻成分提取器可以更加精确。
2.使用全局注意力机制可能会出现注意力错误,因为它同时考虑了一个句子中的所有单词,但是本体和喻体通常都很接近比较词。在标准标注的明喻数据集统计中,发现从本体到比较词和从喻体到比较词的平均距离分别为3.0和4.3。
基于此,提出一种新的基于局部注意力的循环多任务学习框架(MTL-Cyc)。
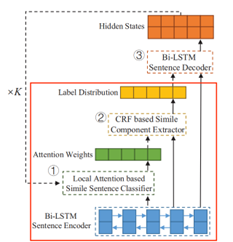
1.通过Bi-LSTM对输入的句子进行编码,并产生词嵌入的序列,作为句子编码输入句子分类器进行有监督学习。
2.句子分类器将局部注意力应用于比较词的周围词,生成带有局部注意力的上下文向量。
3.将通过局部注意力生成的注意力权重和句子编码(词向量序列)连接起来,输入到CRF层,提取明喻成分(利用了局部注意力的提示信息)。
4.将标注标签分布和词向量序列连接起来,作为句子解码器的输入,重建原始句子。
5.将解码器状态和词向量序列求和,最后的结果再次作为明喻分类器的输入。
当K=1时,①-②-③-①
令K=K+1,循环进行模型训练。
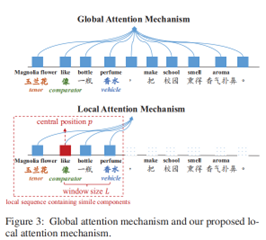
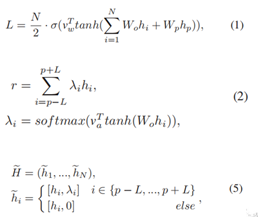
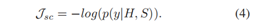
在循环框架的明喻句子分类有两种情况下:在第一种情况下,只有单词表示H用于产生局部注意力权重,然后输入明喻成分提取器,而在另一种情况下,H和和Bi-LSTM解码器状态同时输入。我们直接取H和S的和作为H,即H = H + S,以进行明喻分类。为了统一定义,将明喻句子分类的损失函数定义为4式。
直观上,S包含了明喻成分提取器和句子解码器的有用信息,可以通过将S直接传播到明喻句子分类器中。用公式2生成的注意权重来增加单词表示H。
9.实验结果
9.1实验准备
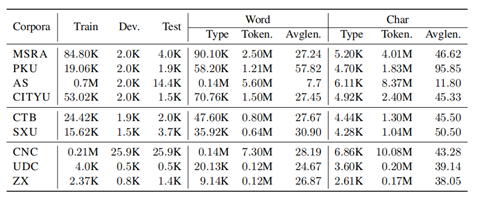
1.采用一个标准的中文明喻识别基准数据集(Liu et al. 2018)
2.其中每个句子包含一个明喻或者不包含明喻,表1显示了该数据集的基本统计数据。
采用5倍交叉验证的方式进行训练:首先将数据集等分为5倍。
每次使用4份作为训练和验证集(80%用于训练,20%用于验证)
最后1份数用于测试,共进行五次。
对于明喻提取,明喻成分的标记方法采用IOBES方案(Ratinov和Roth 2009)。
实验基线:
ME:最大熵模型
MTL(Liu et al. 2018):
句子分类器(双向LSTM+注意力机制)+成分提取器(CRF)+额外监督信号
MTL-OP(Liu et al. 2018):对原来模型的训练步骤的优化。
MTL:作者的模型,但是用全局注意力机制替换局部注意力。
MTL-Pip:作者的模型,但是不采用循环连接结构。
MTL-Cyc:作者的模型。
实验一:K参数的测试
评估指标:F1分数
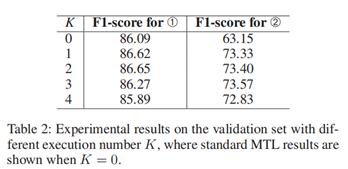
实验结果说明,当K从0增加到1时,明喻句子分类(任务➀)和明喻成分识别(任务➁)都有很大的改进.
实验二:明喻句子分类对比实验
评估指标:精确率,召回率,F1分数
实验结果说明,MTL-Cyc的性能优于其他基线方法,能够比MTL更好地利用子任务之间的相互依赖性。①句子分类②成分提取③句子重建
MTL-Pip:不采用循环连接结构的MTL-Cyc。MTL:全局注意力。
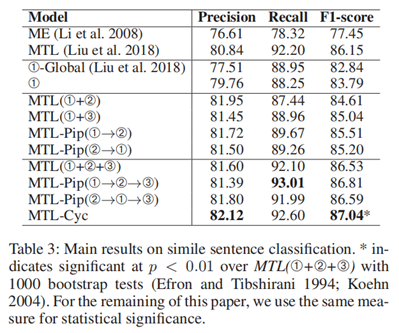
实验结果:
1.总的来说,MTL-Cyc表现出最好的表现,优于之前的模型效果。此外,局部注意效应如图(行4- 5)所示,当用局部注意取代传统的全局注意时,明喻句子分类器的性能提高了约1点。这证实了关注比较器的局部上下文更适合检测明喻句子的假设。
2.联合建模两个子任务,即MTL(➀+➁)、MTL(➀+➂)、MTL-pip(➀→➁)和MTL-pip(➁→➀),其性能都显著优于单一任务模型➀。这说明明喻识别的子任务之间存在着强烈的相互依赖关系。
3.其次,MTL-Pip(➀→➁)和MTL-Pip(➁→➀)的性能都远远优于MTL(➀+➁),这表明MTL-cyc的框架能够比MTL更好地利用子任务之间的相互依赖性。这是由于这两个任务之间利用了双向交互:前一个任务为后续任务提供了有用的信息,同时,后续任务的反向传播也会对前一个任务产生积极的影响
4.此外,MTLPip(➀→➁)的性能优于MTL-Pip(➁→➀)。因此,联合建模子任务的方向对MTL-cyc框架有重要的影响。第三,无论使用哪个框架(MTL-Pip或MTL),联合建模所有三个子任务(表3中的最后一组)都比建模两个任务(表3中的最后一组)更好。这一结果表明,任何子任务都可以为其他子任务提供有用的信息。
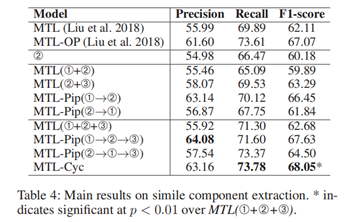
实验三:明喻成分提取实验
评估指标:f1分数
下图为比喻成分提取的比较结果。与Task 1的实验结果相似,MTL-Cyc和MTL-Pip仍然击败了其他模型。特别是,MTL-Pip(➀→➁→➂)表现优于MTL-OP(Liu et al. 2018),显示了训练过程中子任务之间信息共享的有效性。
实验四:词间距和句子长度的影响
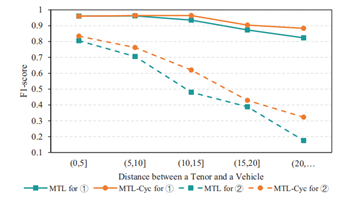
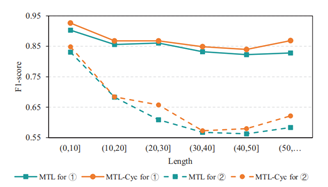
实验五:注意力窗口长度分布实验
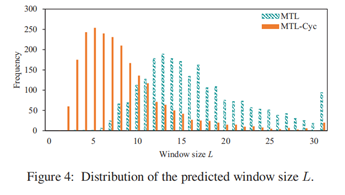
上图显示了预测的窗口大小L (Eq。1)为了我们对测试集的关注。MTLCyc预测的窗口大小往往比MTL预测的要小得多。潜在的原因是,MTL-Cyc允许其局部注意模块被其他任务的输出和损失信号增强和更好地调整。
相关思考
优点:
1.对于研究的明喻本身的定义以及检测、识别任务的目标都是清晰明确的。
2.考虑到词间距在明喻检测中的不同之处,采用了局部注意力替换全局注意力,并且结合多任务学习和循环连接提升模型效果,研究选择的切入点非常合理。
3.对比实验非常充分,既对模型不同模块的效果进行了充分的对比实验,又对提出的假设进行了验证,对实验的选择有借鉴意义。
不足:
1.模型采用的方法比较常见。
2.需要进行大量的人工标注工作。
3.一些实验上,模型的提升效果不是很显著。
一些补充:
提示学习——论文名:
[1] Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
[2] Language Models as Knowledge Bases?
[3] Universal Adversarial Triggers for Attacking and Analyzing NLP
[4] Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
[5] AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
[6] Universal Adversarial Triggers for Attacking and Analyzing NLP