阅读笔记作者:杨菲
1 原文作者
Yingrui Xu (Institute of Information Engineering, Chinese Academy of Sciences、the School of Cyber Security, University of Chinese Academy of Sciences)
Hao Liu (Institute of Information Engineering, Chinese Academy of Sciences、the School of Cyber Security, University of Chinese Academy of Sciences)
Jingguo Ge (Institute of Information Engineering, Chinese Academy of Sciences、the School of Cyber Security, University of Chinese Academy of Sciences)
Xiaodan Zhang (Institute of Information Engineering, Chinese Academy of Sciences)
Jingyuan Hu (Institute of Information Engineering, Chinese Academy of Sciences)
Yulei Wu (the Department of Computer Science, Faculty of Envi- ronment, Science and Economy, University of Exeter)
2 论文来源
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING (2022)
3 论文地址
4 论文简介
研究背景:一在线评论通过提供产品购买者反馈的信息,在其他消费者的购买决策中发挥着重要作用。为了误导消费者,虚假评论发送者被雇佣撰写虚假评论,以增加或降低特定产品的销量,以获取不正当利益。
作者举例,三星被指控雇佣学生对竞争对手的手机发表负面评论。虚假评论的出现导致欺骗性信息大量涌入点评网站,严重影响了电子商务的运行。
研究内容:提出了一种新的弱-强统一网络(WSUN)来检测垃圾邮件。为了揭示垃圾邮件发送者的异常行为模式,构建多层次弱关系图,利用图卷积网络聚合强关系语义,利用关系级注意机制提取综合评论表示。此外,设计了一种基于图的过采样方法,以减轻类分布不平衡的影响。
研究结论:在真实数据集上的大量实验结果表明,该模型比最先进的方法更有效。
5 解决问题
关于虚假评论检测现阶段存在两个主要问题:
现有研究主要通过用户-评论-产品之间固有的强关系,自动学习评论语义。但未能在内容、情感和时间层面上捕捉到评论之间的弱关系。
虚假评论检测问题中的数据集分布不平衡。在现实世界中,虚假评论发送者的数量远远少于真实用户的数量。
6 本文贡献
- 提出了一种利用异常行为模式构建多层次弱关系图的新方法,该方法在内容、情感和时间层面捕捉各种语义信息。
- 设计了一种新的基于图的过采样方法来增强类不平衡图表示学习。
- 开发了一种关系层面的注意力机制,将内容、情感和时间层面的信息融合在一起以了解不同特征的重要性,获得一个全面的评论表示。
- 在五个真实世界的数据集上进行了广泛的实验。实验结果表明,该模型优于现有方法。
7 论文方法 作者提出了一种新型的意见虚假评论检测模型WSUN,它由三个部分组成:图构造层、过采样层和特征融合层。首先,从内容、情感和时间三个层面挖掘评论之间的潜在关系,构建多层次弱关系图;在此基础上,提出了一种基于图的抽样方法,通过平衡倾斜的类分布来减小多数类的域效应。最后,将评论信息及其强关联信息联合编码到GCNs中学习评论嵌入,然后应用关系级注意机制在获得的嵌入中捕获最有效的特征。
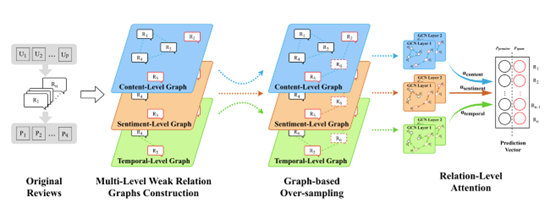
1.内容级图:
由于虚假评论发送者通常在短时间内发布大量评论,评论内容往往高度相似,内容相似度由文本向量之间的余弦函数定义:
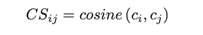
定义σc为内容相似度阈值。当评论i和j为同一用户或对同一产品发表的评论,且CSij>σc时,在弱关系图中将它们连接起来。
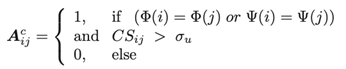
2.情感级图:
为了误导消费者,虚假评论发送者倾向于给出极端的评级。因此,这些评论可能会偏离评级共识。定义评论i的评级偏差如下:
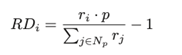
设σs为情感偏差阈值。RDi>σs的评论放入正集,RDi<σs的评论放入负集。同理,计算情绪得分,得到消极集和积极集。在弱关系图中将同集合连接起来:
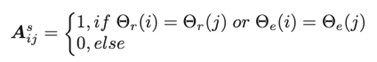
3.时间级图:
虚假评论在时间模式中呈现多样性。虚假评论发送者倾向于在短时间间隔内发布评论。计算发布时间偏差:
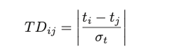
其中,σt为时间级别阈值。当同一用户或产品对应的评论间的TDij<1时,在弱关系图中将它们连接起来:
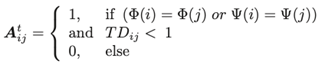
基于图的过采样
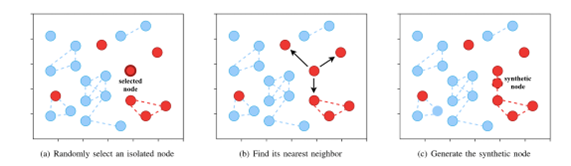
- 找到没有邻居的少数类节点。由于孤立节点不提供结构信息,优先进行过采样,以降低图的稀疏性
- 随机选取一个孤立节点作为样本,寻找其同类的最近邻居。然后将其与其最近的邻居连接起来
- 在它们的连接线上随机取一个点作为合成节点。
重复这一过程,直到所有孤立的节点都被采样,或者少数节点的数量达到与多数节点相同。如果对所有孤立节点进行过采样后,两个类的数量不相同,则对其他少数节点进行随机采样。在节点生成和边缘构造完成后,得到三个相对平衡的图
特征融合
评论表示:采用FastText对评论进行编码,通过聚合评论来学习用户与产品相关的特征。
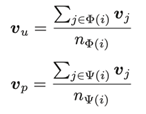
然后,将用户、产品和评论的特征进行拼接并进行线性变换,得到评论i的表示:
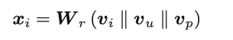
特征传播:得到评论表示后,通过GCN进行特征传播。
关系级注意机制:融合内容级、情感级和时间级的嵌入,以获得更全面的表示。
8 实验结果
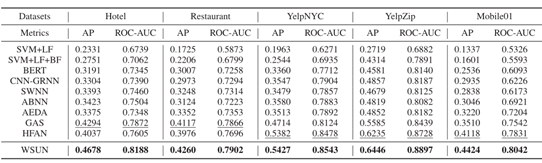
- 数据集:
使用五个真实世界的数据集进行了实验,包括Hotel, restaurrant, YelpNYC, YelpZip和Mobile01(繁体中文)。

2.对比实验
基于特征的方法:SVM+LF、SVM+LF+BF
深度学习模型:BERT、CNN- GRNN、SWNN、ABNN、AEDA
利用固有用户-评论-产品关系信息:GAS、HFAN
指标:平均精度(AP)和曲线下面积(AUC)。
3.消融实验:
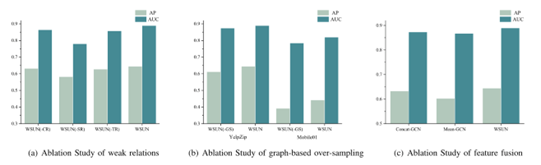
从三个方面验证了模型:1)弱关系的有效性;2)基于图的过采样的有效性;3)关系级注意对特征融合的有效性。
4.注意力权重学习
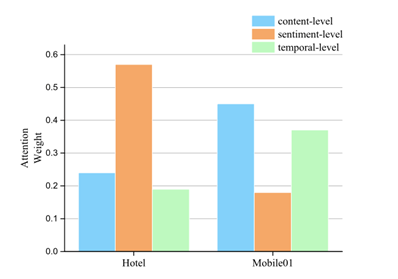
- 关系级注意机制能够通过学习每个关系的重要性来衡量不同的特征。为了证明所提方法的可解释性,作者选取了Hotel和Mobile01数据集上的学习到的注意力权重来说明问题。
- Hotel中情感级特征权重最大,Mobile01中内容级特征权重最大。Hotel的结果表明,虚假评论发送者倾向于通过强烈的情绪和偏离评级来误导消费者。这与消融实验中结果一致。
5.参数分析
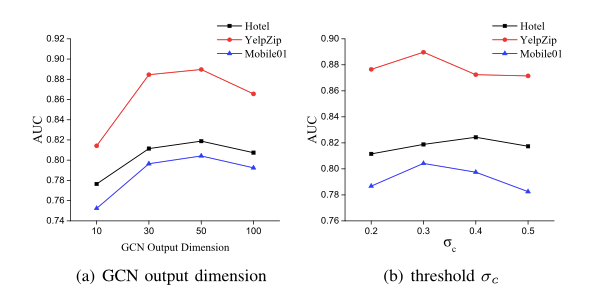
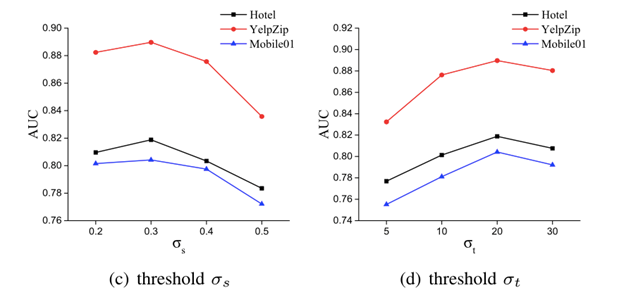
讨论参数选择对WSUN的影响,包括GCN的输出特征维数和图构造层面的阈值选择。
在维数达到50时性能最好。这表明,在一定范围内,不断增长的维度提供了更全面的特征。在此之后,由于更大维度带来的冗余信息,性能开始下降。
当σc选择为0.3时,模型最为有效。随着内容相似度阈值的增大,能够捕捉到的相似评论越来越少。另一方面,当σc变小时,评价不再具有鉴别性,从而导致模型的性能下降。
σs = 0.3的结果最令人满意,因为情绪偏差较大,大多数评论被划分为中立集。当偏差减小时,更多的真实评论被添加到正面和负面集合中。
当时间偏差为20天时,模型表现最佳。原因是较小的时间偏差会使模型难以捕获足够数量的评论,而较大的时间偏差会带来过多的冗余信息