阅读笔记作者:杨菲
原文作者
Xiang Li (School of Data Science and Engineering, East China Normal University)
Danhao Ding (Department of Computer Science, The University of Hong Kong)
Ben Kao (Department of Computer Science, The University of Hong Kong)
Yizhou Sun (Department of Computer Science, University of California)
Nikos Mamoulis (Department of Computer Science and Engineering, University of Ioannina)
2 论文来源
ICDE(2021)
3 论文地址
4 论文简介
研究背景:一个异构信息网络(HIN)有不同类型的顶点和顶点之间的关系,这些顶点和顶点关系各自都有不同的类型。在HIN中对物体进行分类的问题研究中,大多数现有的方法在给定稀缺的标记对象作为训练集时表现很差,而在这种情况下提高分类精度的方法往往计算成本很高。
研究内容:为了解决这些问题,作者提出了ConCH,一个图神经网络模型。ConCH将分类问题表述为一个多任务学习问题,将半监督学习和自监督学习结合起来,从有标签和无标签的数据中学习。ConCH采用了元路径来捕捉物体之间的语义关系,通过图卷积共同推导出对象嵌入和语境嵌入。ConCH还使用注意力机制来融合这些嵌入。
研究结论:作者进行了广泛的实验来评估ConCH与其他15种分类方法的性能。结果表明,ConCH是一种有效的、高效的HIN分类方法。
5 解决问题
HINs中现有的GCN模型存在两个主要问题。一方面,虽然目前的大多数研究方法已经被证明是有效的,但相关研究都是在大型训练集上进行的。当标注的对象很少时,这些方法的性能就会下降(如原文中表1所示)。另一方面,一些方法通过牺牲效率来提高分类精度。例如,增加一个聚合器来结合一个对象的多类型邻居的信息。但这种聚合器的架构引入了更多的可学习参数,增加了训练难度,对模型的效率产生了不利影响。
6 本文贡献
- 提出了ConCH,一种利用基于元路径的上下文来有效且高效地对HINs中的对象进行分类的模型,并可以使用给定对象为稀缺标记对象的数据集来作为训练集。
- 将HINs中的分类问题表述为一个多任务学习问题,结合了半监督学习和自监督学习。特别是,当标记对象稀少时,有着从未标记的数据中学习的自我监督有助于提高模型的性能。
- 通过一种过滤策略来提高模型的效率,该策略基于路径的邻居来选择最有信息量的对象。可以从选定的邻居那里汇总信息来计算一个对象的嵌入。
- 进行了广泛的实验来评估ConCH与其他15个模型的对比。结果表明,ConCH是非常有效的,也是高效的。
7 论文方法
对于HIN中的一个对象x,ConCH首先根据一组表达各种语义关系的元路径来确定x的一组基于路径的邻居(步骤1)。这些基于元路径的关系将HIN中的对象与路径实例联系起来,这些实例被视为mp-context(步骤2)。然后,ConCH为每个给定的元路径P构建一个二分图(步骤3)。二分图表示对象和与之相关的mp语境,它有助于更新对象和语境的嵌入(步骤4)。之后,由各种元路径产生的对象嵌入被融合,以获得对象的最终嵌入(步骤5),然后将其送入两层MLP进行标签预测(步骤6)。为了更好地利用未标记的数据,ConCH还使用了自监督学习。对于每个元路径,除了在步骤3中构建的二分图外,ConCH还进一步生成了一个 “负 “二分图(步骤7)。从这两个图中,构建了一个正样本集和一个负样本集。之后,ConCH使用一个判别器D来区分这两个集合(步骤8)。最后,目标函数被表述为一个多任务学习问题,即结合监督损失和自监督损失。
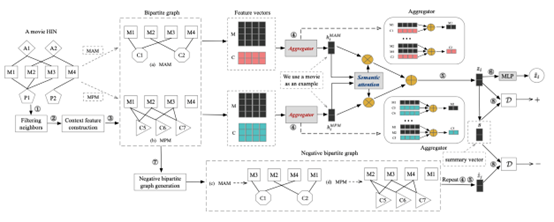
- 邻居过滤
给定HIN中的一个对象x,我们的目标是识别网络中与x相似的其他对象,并使用它们的标签来推断x的标签。称这些其他对象为相关邻居。请注意,这些邻居可能离x有好几跳的距离,特别是如果它们通过表达对象之间重要语义关系的某些给定元路径的实例与x相关。一个有趣的问题是如何有效和高效地获得相关的邻居。如果元路径很多(比如那些通过自动方法获得的路径),而且很长,那么从这些路径中得到的邻居可能会覆盖网络的很大范围。直接聚合大量邻居的信息会使模型的构建效率降低。 所以第一步是过滤邻居,选择一个物体的最相关的邻居。给定一个元路径P,ConCH通过PathSim测量两个相同类型的对象xu和xv在关系P上的相似度。
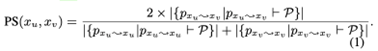
PathSim已被证明在HINs的各种数据挖掘任务中非常有效。给定一个对象x和元路径P,ConCH收集一组邻居NxP,其中包含PathSim得分最高的前k个实例,这些物体与x的关系是P。此外,它还可以去除不太相关的对象,从而有助于减少噪音。这进一步提高了分类的有效性和效率。
- 上下文特征构建
回顾一下,给定两个对象x1和xl,以及一个元路径P,mp-context(元路径上下文) cP1l是x1和xl之间P的路径实例的集合。通过将其视为可学习参数来从头学习上下文嵌入是非常昂贵的。为了减少参数的数量,我们为每个上下文构建一个特征向量。具体来说,应用传统的HIN嵌入方法,如metapath2vec,以获得初始对象嵌入。然后,通过聚合路径实例中所有对象的嵌入向量来生成路径实例的嵌入。
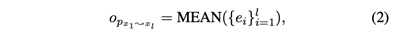
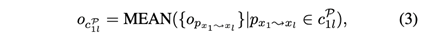
作为上下文cP1l的特征向量。【我认为这里有点类似于HAN中更新计算连接到中间向量的初始向量】
- 基于元路径的二分图
在前面的步骤中,我们得到了一组选定的基于路径的对象的邻居和mp-context。接下来通过一个相互更新的过程来更新它们的嵌入。请注意,两个对象之间基于元路径的关系受到连接这两个对象的元路径实例(即上下文)的影响;同时,上下文也受到组成元路径实例的对象的影响。因此,我们将对象嵌入和上下文嵌入一起更新。为了促进这种更新,我们首先为每个元路径P构建二分图GP=(X,VPC,EPOC),其中X是待分类对象的集合,VPC是来自P的元路径上下文的集合,EPOC是边的集合,即 eij连接了X中的对象xi和VPC中的上下文cj,如果cj中的路径cj中的实例从xi开始或在xi结束。请注意,我们的邻居过滤方案为每个对象推导出顶k邻居。因此,任何对象x在二分图中的程度最多只有k。
框架图中显示了从电影HIN中得出的二分图的例子。对于元路径Movie-Actor-Movie(MAM),M1和M3由路径实例M1→A1→M3连接,M2和M4由M2→A2→M4连接。MAM的二分图如图所示,其中上下文C1={M1→A1→M3},C2={M2→A2→M4}。 我们将对象嵌入(用hPx表示)和上下文嵌入(用hPc表示)相互更新。对于每个与GP中的两个对象xu和xv相联系的上下文cj,我们在第(t+1)个时间段通过汇总xu和xv的信息来更新其嵌入向量hPcj。
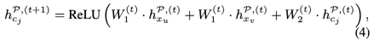
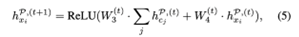
(对应图中得到hiMAM hiMPM)
- 语义聚合
下一步是将来自不同元路径的对象嵌入融合在一起。由于不同的元路径代表不同的语义关系,它们在分类任务中的贡献程度不同。我们使用注意力机制来学习元路径的重要性。给定一个元路径P和一个对象xi的嵌入向量hPxi,我们将hPxi送入一个两层MLP,然后得到:
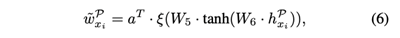
其中,a是权重向量,ξ是leaky_ReLU函数。而W5和W6是两个线性变换矩阵。通过softmax函数对公式6结果进行正则化,并通过以下方式计算元路径P的注意权重wPxi
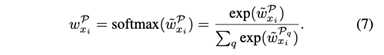
最后,我们通过元路径聚合嵌入向量,并通过以下方式生成xi的最终嵌入向量zi:
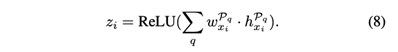
- ConCH 模型
在语义聚合之后,指导参数学习的一个标准方法是使用训练集中的标签信息。具体来说,我们首先将公式8中的zi送入一个两层MLP,以输出一个长度为r(r为标签数量)的标签向量,如公式9所示。
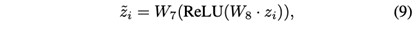
其中W7和W8是可学习的权重矩阵。z~i中最大值的条目所对应的标签被作为xi的预测标签。然后,我们最小化交叉熵损失函数。
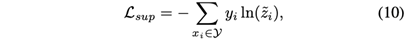
其中,Y是标记对象的训练集,yi是对象xi的one-hot encoded真实标签向量。虽然公式10中的有监督损失是有用的,但当标记对象的数量有限时,模型的性能可能会受到不利影响。此外,自监督学习在利用无标签数据方面显示出巨大的潜力。因此,我们将自监督学习纳入学习过程,以利用已标记和未标记的对象。
在得出一个物体的最终嵌入向量后(在公式8中),我们计算一个摘要向量s作为全局表示编码器,它保留了所有要分类的物体类型的信息。我们简单地采取平均运算,得到。
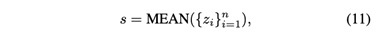
其中n是要分类的对象的数量。然后,我们将节点嵌入和全局表示之间的相互信息最大化,这将鼓励每个单一对象获得其他对象的信息。我们使用一个带有标准二元交叉熵损失的噪声对比型目标函数。
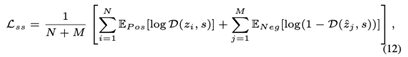
其中D是一个判别器,用于区分正样本集和负样本集。当对象x属于原图时,样本(zi , s)为真;当对象xj是生成的假图时,样本(zˆj , s)为假。D(zi,s)代表分配给输入node-summary的概率分数,它被定义为
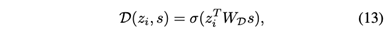
其中σ是sigmoid函数,WD是可学习权重矩阵。为了生成负样本,对于每个基于元路径的二分图,我们固定邻接矩阵不变,随机刷新初始对象特征矩阵的行,这就生成了一个 “负 “二分图。例如,上图(a)和上图(c)分别显示了原始的二分图(我们称其为 “正”,以便比较)和由元路径MAM导出的 “负 “图。负二分图中电影的特征向量与正向图中的特征向量进行了洗牌。对于构建的负二分图,我们重复步骤4和5(在第IV-C和IV-D节),为每个对象xj得到zˆj,并进一步构建Neg.
最后,为了从有标签和无标签的数据中学习,我们将问题表述为一个多任务学习问题,将Lsup和Lss结合起来,得到一个损失函数。
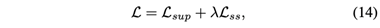
其中λ控制了两个项的相对重要性。在这里,自监督损失作为一个正则器,从未标记的数据中学习。当标记对象的数量有限时,学习到的数据驱动的先验知识可以为训练集提供补充信息。这进一步增强了模型的能力。损失函数可以通过随机梯度下降进行操作。为了防止过度拟合,我们进一步对公式4到公式13中提到的所有权重矩阵Wj进行正则化(优化L以更新权重矩阵Wj’s)。
ConCH的主要计算成本来自于对象和上下文嵌入的更新。设n为待分类对象的数量。在每个二分图中,最多只有n个上下文。由于每个对象的度数最多为k,一个上下文的度数最多为2,嵌入更新的总时间复杂度为O(3knd1d2),其中d1和d2分别为MLP转换矩阵的最大行数和列数。此外,对于每个元路径,我们生成一个 “正 “的双方图和一个 “负 “的双方图。因此,嵌入更新的总时间复杂性是O(6knd1d2|PS|),其中|PS|是元路径的数量。由于每个二分图的计算都是独立于其他二分图的,所以ConCH很容易被并行化。
8 实验结果
- 数据集:
DBLP:4057个作者(A),14376篇论文(P)和20个会议(C);元路径集{APA, APAPA, APCPA};作者按照研究领域进行分类:数据库(DB)、数据挖掘(DM)、机器学习(ML)和信息检索(IR)
Yelp:2,614家企业(B),33,360条评论(R),1,286名用户(U)和82个食品相关的关键词(K);元路径{BRURB, BRKRB};餐厅按照提供的食物类型进行分类:快餐,寿司店和美国新食品
Freebase:包含3492部电影(M),33401个演员(A),2502个导演(D)和4459个制片人(P);元路径{MAM, MDM, MPM};电影按类型进行分类:动作片、喜剧片和戏剧。
- 对比模型:
基于网络嵌入的方法:node2vec、mp2vec
基于图-神经网络的方法:GCN、 GAT、 MVGRL、 HAN、 HetGNN、 MAGNN、 HGT 、 HDGI、 HGCN
注:HAN, HetGNN, MAGNN, HGT, HDGI和HGCN是最先进的异质神经网络模型。请注意,HAN、MAGNN和HDGI利用了元路径,而其他的没有。特别是,HDGI使用HAN作为基础神经网络模型。对于MVGRL、Het- GNN和HDGI来说,由于它们是无监督的,学习到的对象嵌入被送入一个逻辑回归分类器来预测对象的标签。
- 对比实验
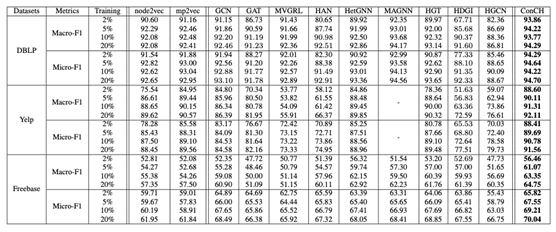
上表总结了对比实验结果。在两个评价指标下的三个数据集上评估了这些方法。此外,为了比较标记对象稀少时的方法,作者将训练集的大小从非常小的(2%和5%)到中等的(10%和20%)。因此,在比较研究中,总共有3×2×4=24场 “比赛”。表中的每一行都对应着一个竞赛。对于每场比赛,我们用黑体字标出获胜者的分数。从表中,我们可以看出以下几点。
(1) 随着训练集大小的减少,许多基线方法的性能急剧下降。例如,在DBLP上,HDGI的Micro-F1得分是0.9233,有20%的标签对象,这与冠军的得分接近。然而,在只有2%的标签对象时,HDGI的得分下降到0.7733,而最佳得分(ConCH)是0.9429。
(2) 对于两种基于网络嵌入的方法,mp2vec在DBLP和Yelp上的表现更好,而node2vec在Freebase上领先。尽管mp2vec是一种使用元路径的HINs嵌入方法,但它只能接受一条元路径作为输入,这影响了它的性能。
(3) ConCH优于图神经网络模型GCN和GAT。这是因为这两种方法都是为豪迈的网络设计的,没有考虑对象和链接的异质性。虽然MVGRL利用了自我监督,但它忽略了异质性,因此ConCH表现更好。
(4) 尽管HAN是为HINs设计的,而且它使用元路径,但HAN省略了mp-context,这降低了它的有效性。例如,它在Yelp上的Macro-F1得分是0.6637,明显低于ConCH的得分。这显示了mp-context的重要性。此外,由于HDGI将HAN作为基础神经网络模型,它的性能也会因为对mp上下文的忽视而受到负面影响。MAGNN考虑了mp-contextts,它在DBLP上表现良好。然而,MAGNN在计算上是昂贵的。此外,MAGNN需要对每个元路径实例进行预处理和维护信息,这需要大量的存储。例如,Yelp任务中的元路径处理产生了大量的对象之间的路径实例,这导致了内存不足的错误。因此,在该项实验中,MAGNN未能在Yelp上运行。
(5) HetGNN和HGT在所有三个数据集上都能取得良好的总体性能。然而,当标记对象的数量有限时,它们也容易受到影响。例如,在2%的标注对象中,Het-GNN和HGT在Yelp上的Macro-F1得分分别为0.8486和0.7836,而赢家的得分是0.8860。HGCN通过聚合一个对象的邻居的标签信息为其构建关系特征。然而,构建的关系特征和对象的原始特征可能处于不同的特征空间,这限制了模型的有效性。
(6) ConCH在所有24种情况下都取得了最佳性能。ConCH使用一个简单的邻居过滤方案来移除对象的不相关的邻居。此外,ConCH基于元路径,利用mp-contextts来提高分类性能。我们进一步观察到,与其他方法相比,在标注对象很少的情况下,ConCH取得了优异的性能。例如,在2%的标注对象中,ConCH在Yelp上的Micro-F1得分是0.8841,而亚军的得分只有0.8558。这是因为从未标记的数据中学习到的自我监督提供了额外的信息,有助于对对象进行分类。
- 消融实验:
对ConCH进行了消融研究,以了解其主要组成部分的特点。
ConCH_nc:通过直接聚合由元路径指定的多跳邻居的信息来更新对象的嵌入,而不考虑来自路径实例的上下文。这有助于我们理解在对象分类中包括mp上下文的重要性。
ConCH_rd:从一个给定的对象中随机选择k个基于元路径的邻居作为相关的邻居。这与ConCH相反,ConCH是根据PathSim的得分选择前k个最相似的基于路径的邻居来选择相关的邻居。这有助于我们评估我们的邻居过滤策略的有效性。
ConCH_su:为了显示自监督正则化的重要性,我们只用Lsup来训练模型。
ConCH_ft:虽然我们将问题表述为一个多任务学习目标,但我们也可以通过预训练和微调策略来训练模型。具体来说,我们首先通过只使用Lss来训练模型,然后将学到的参数作为只使用Lsup的模型的初始化。这个变体可以用来展示多任务学习框架的优势。
ConCH_ew:该变体在没有注意力机制的情况下为元路径分配相等的权重。
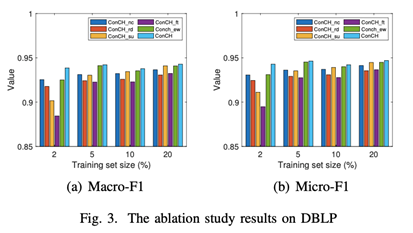
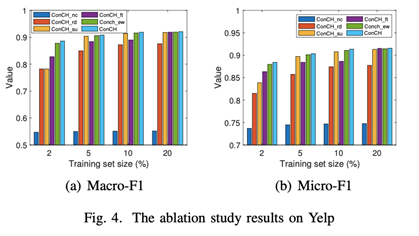
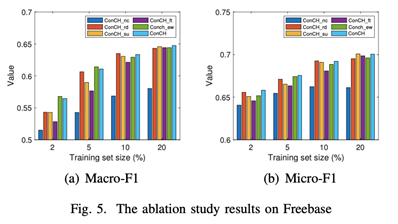
在三个数据集上的四种训练集规模下,用Macro-F1和Micro-F1的衡量标准来比较ConCH和这些变体。结果见上图。从这些图中,我们观察到。
(1) ConCH在所有24种情况下都战胜了ConCH_nc。特别是,ConCH在Yelp和Freebase上明显优于ConCH_nc。这表明,mp-context信息对于具有对象类型和链接类型的异质性的HINs特别重要。当使用元路径时,包含mp-context是有效分类的关键。
(2) ConCH比ConCH_rd取得了更好的性能。由于ConCH_rd为一个对象随机选择k个基于路径的邻居,ConCH和ConCH_rd之间的性能差距表明,ConCH的top-k邻居过滤策略在选择更有影响力的基于路径的邻居以提高分类精度方面非常有效。
(3) 鉴于20%的标记对象,ConCH_su取得了与ConCH相似的性能。然而,随着训练集大小的减少,ConCH和ConCH_su之间的性能差距越来越大。这进一步说明了利用自我监督学习来弥补标记对象的不足的重要性。
(4)ConCH在三个数据集上的表现明显优于ConCH_ft。ConCH_ft在预训练时将目标函数从Lss切换到微调时的Lsup,解决了两个优化问题。然而,ConCH将这两个损失函数统一为一个目标,更容易被优化,并能更好地利用有标签和无标签的对象。
(5) ConCH在22种情况下比ConCH_ew表现得更好。这进一步说明了注意力机制在学习元路径权重中的重要性。
注意力权重学习:
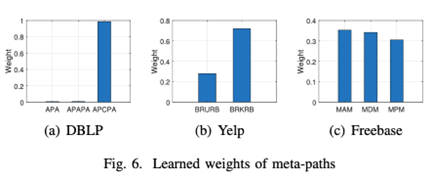
上图(a)显示了DBLP数据集的元路径的学习权重。回顾一下,分类任务是按照作者的研究领域进行分类。从图中我们可以看到,元路径APCPA(在同一地点发表论文的作者)的权重几乎为1,而元路径APA(共同作者)和APAPA(有共同合作作者的作者)的权重非常接近0。之所以给APA这么低的权重,是因为它是一种稀疏的关系。一个作者通常只与社区中的少数几个人合著。此外,一个作者通过APCPA(会议共同出席者关系)与其他大量的作者有关系。此外,与APA相关的作者也与APCPA相关,因此,前者被后者所包含。在这个例子中,我们看到ConCH正确地选择了相关的元路径APCPA而不是APA和APAPA。
上图(b)显示了Yelp数据集的元路径学习权重。回顾一下,我们的任务是按照食物的类别对餐馆进行分类。我们看到,元路径BRKRB(评论中包含相同食物关键词的餐馆)被赋予了比BRURB(被同一个顾客访问过的餐馆)大得多的权重。这是合理的,因为评论中的食物关键词直接表明食物类别。另一方面,一个顾客可以访问提供不同类别食物的餐馆。
Freebase的任务是按类型对电影进行分类。上图(c)显示,这三个元路径都很有用。元路径MAM(电影共享同一个演员)和MDM(电影由同一个导演拍摄)的权重比MPM(电影由同一个制片人制作)的权重大一些。从我们的讨论中,我们看到ConCH的元路径权重学习策略是非常有效的。
效率研究:
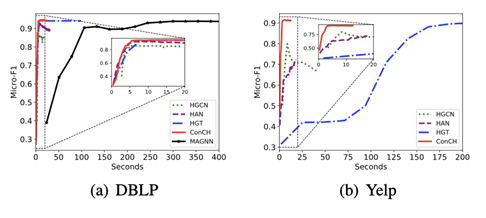
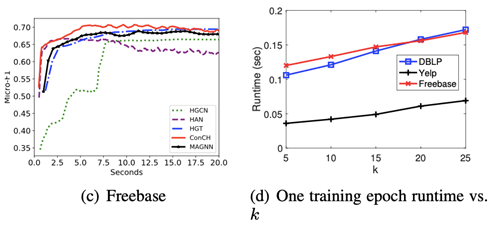
该实验比较了ConCH、HAN、MAGNN、HGT和HGCN的训练时间,因为它们都是HINs中的半监督分类方法。对于所有这些方法,使用相同的训练/验证集,并运行300个epochs的实验。我们把20%的标记对象作为训练集来说明。重复所有的实验三次,并在上图中显示了这些方法的平均训练时间与验证集上的Micro-F1得分。请注意,在Yelp上不能运行MAGNN。
回顾一下这些方法的主要区别。ConCH、HAN和MAGNN是基于元路径的。然而,ConCH根据一个过滤方案为一个对象选择k个最有信息量的基于路径的邻居。HAN使用所有基于元路径的邻居(即没有过滤),它通过虚构的注意力机制学习邻居的相对重要性。HAN也不使用mp-contextts。与ConCH不同的是,MAGNN使用mp-contextts来构建具有特征的高级语境对象,它通过独立考虑所有元路径实例,以细粒度的方式利用mp-contextts。它学习元路径实例的重要性,并进一步聚合这些路径实例的信息来生成对象嵌入。HGT采用了一个基于Transformer的聚合器来聚合一个对象的多类型邻居的信息,而HGCN则利用了使用不同卷积滤波器的多个内核。
从上图(a)-(c),可以看到ConCH在所有三个数据集上都能快速收敛到最佳结果。MAGNN和HGT也能达到很高的性能分数,然而,它们需要更长的时间来收敛。特别是MAGNN,当元路径的长度较长时,路径实例的数量可能很多,这对模型的效率有不利影响。例如,ConCH在DBLP上比MAGNN快50倍;ConCH在Yelp上比HGT实现了近40倍的速度。虽然HAN和HGCN比MAGNN和HGT快,但它们的性能很差。结果表明,我们的方法ConCH是非常高效的,也是非常有效的。
最后,ConCH的运行时间取决于一个物体的相关邻居的数量k。上图(d)显示了ConCH的一个训练周期的运行时间是如何随k变化的。从图中我们可以看出,运行时间随着k的增加而相当线性地增加。
参数分析:
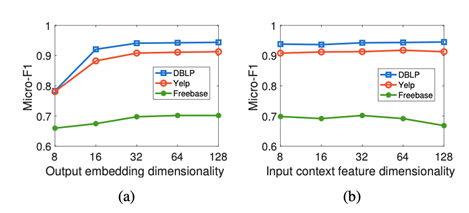
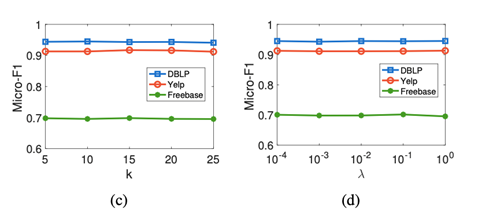
(1) 随着输出嵌入维数的增加,ConCH取得了更好的性能。这是因为当维数较小时,节点嵌入不能捕捉到足够的信息来对物体进行分类。
(2) 当输入上下文特征维数为128时,Freebase的性能下降。这表明,大维度的初始情境嵌入向量可能包含噪音,对分类精度产生不利影响。
(3) 对于其他两个超参数,ConCH在很大的参数值范围内给出了非常稳定的表现。这进一步表明,ConCH是解决HINs分类问题的有效方法。
9 代码和数据集地址
https://github.com/dingdanhao110/Conch.