1 原文作者
Yuwei Cao (University of Illinois at Chicago)
Hao Peng (Beihang University)
Jia Wu (Macquarie University)
Yingtong Dou (University of Illinois at Chicago)
Jianxin Li (Beihang University)
Philip S. Yu (University of Illinois at Chicago)
2 论文来源
2021 International World Wide Web Conference(WWW ’21, April 19–23, 2021, Ljubljana, Slovenia)
3 论文地址
4 论文简介
社会事件能够反映出群体的社会行为和公众的广泛关注,因此在产品推荐和危机管理等领域有许多应用。社会信息的复杂性和流式特性使得社会事件检测问题在增量学习的场景下更易解决,其中获取、保存和扩展知识是主要的研究关注点。现有的大多数方法,包括基于增量聚类和社区检测的方法,由于忽略了社会数据中包含的丰富的语义和结构信息,所以学习的知识量有限。此外,它们不能记忆以前学习的知识。在本文中,作者提出了一种新的基于异构GNN进行知识保存的增量社会事件检测的模型(KPGNN),用于增量社会事件检测。为了获得更多的知识,KPGNN将复杂的社会信息建模为统一的社会图,以促进数据的利用,并探索GNNs在知识提取方面的表达能力。为了不断适应传入的数据,KPGNN采用对比性的损失函数,以应对不断变化的事件类别数量。此外,KPGNN还利用GNN的归纳学习能力来有效地检测事件,并从以前未见过的数据中扩展其知识。为了处理大量的社会数据流,KPGNN采用分批子图采样策略进行可扩展的训练,并定期删除过时的数据以保持动态的嵌入空间。KPGNN不需要特征工程,也没有太多需要调整的参数。大量的实验结果表明,KPGNN比各种基线更有优势。
5 解决问题
本文主要试图解决增量学习场景下的社会事件检测问题。
社会事件检测的任务可以被建模为从社会流(即社会媒体信息的序列)中提取共同相关的信息集群来代表事件。与传统的新闻和文章相比,社交流(如Twitter流)更加复杂,原因如下:它们是按顺序产生的,数量巨大;它们包含各种类型的元素,包括文本、时间、标签和隐含的社交网络结构;它们的内容很短,经常包含字典中没有的缩写;它们元素的语义变化很快。这些特点使社会事件检测成为一项具有挑战性的任务。
现有的社会事件检测方法识别事件时使用统计学特征,如词频和共现性来识别事件,而忽略了社交数据流中丰富的语义和结构信息。此外,这些方法在其模型中的参数非常少。因此,它们不能记忆以前学到的信息,也就是说他们会忘记他们所学到的东西。
在本文中,作者从知识保存的角度来解决增量社会事件检测问题,也就是说,作者设计的模型在检测即将到来的社会信息中的事件时,会不断地扩展其知识。然而,这种保留知识的增量社会事件检测带来了巨大的挑战,将其总结为以下几点。首先,该模型应该具有获取、保存和扩展知识的能力。这就要求模型有效地组织和处理社会流中的各种元素,以便充分利用,并有效地解释这些元素以发现有助于事件检测的潜在知识。此外,当新消息到来时,模型需要有效地更新其知识。有鉴于此,使用新信息的持续训练比从头开始训练更有优势。其次,该模型需要处理不断变化的未知事件(类)的数量。在离线情况下,类的总数是预先知道的和固定的,而在在线情况下,新的事件不断出现。很明显,使用softmax交叉熵损失的分类技术不能直接应用。第三,该模型需要扩展到大型社会流。随着新信息的到来,该模型需要不时地删除过时的社会信息,以保持一个动态的输出空间。另外,与批量训练相比,迷你批量训练更为可取,因为它不需要将整个训练数据集放在内存中。
6 本文贡献
本文在公开的大规模Twitter语料库和MAVEN事件检测语料库上进行了广泛的实验。实证结果表明,KPGNN通过有效地保留面向事件检测的知识,实现了比各种基线更好的性能。本文在Github网站上公开了代码和预处理数据。
本文主要贡献及创新点在于:
- 将社会事件检测的任务建模为一个增量学习环境下的任务;
- 设计了一个新颖的基于异构GNN的知识保留的增量社会事件检测模型,即KPGNN。KPGNN能够持续检测来自社会流的事件,同时拥有解释复杂的社会数据以积累知识的能力。本文是第一个在增量社会事件检测中使用GNN的研究;
- 通过大量实验证明了所提出的KPGNN模型的有效性;
论文方法
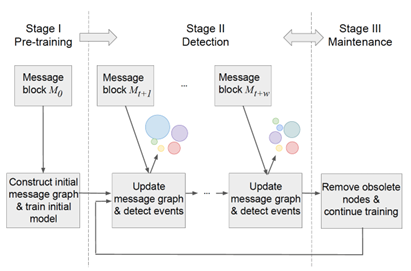
第一阶段预训练一个初始的KPGNN模型。在第二阶段,预训练的KPGNN模型直接用于检测未见过的信息中的社会事件。在第三阶段,KPGNN模型通过使用在第二阶段到达的新信息继续训练来维护。维护好的KPGNN模型就可以用于下一个检测阶段。𝑀0, 𝑀𝑡+1, 𝑀𝑡+𝑤表示输入信息块,𝑤是维护模型的窗口大小。彩色的气泡代表信息的集群,即社会事件。
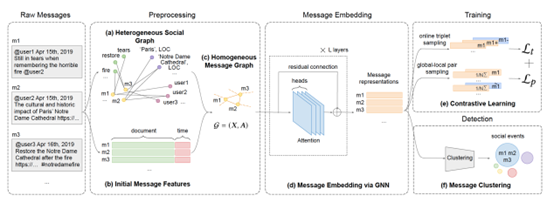
在预处理阶段,为了充分利用社会数据,从信息中提取不同类型的信息元素,以及以统一的方式组织提取的元素,以方便进一步处理,作者首先利用异质信息网络(HINs)将社会信息建模为异质社会图。由于KPGNN侧重于学习信息之间的相关性,因此将异质社会图映射为同质信息图,来保持信息的相关性。随后,使用document中所有单词嵌入的平均值来构建包含自然语言语义和时间信息的初始消息特征向量。
在消息嵌入阶段,采用GNN来学习消息嵌入。模型采用了图注意力机制,因为它不假定固定的图结构,这使得KPGNN能够增量学习。KPGNN保留了知识:学习到的消息嵌入中编码了语义、时间和结构信息;模型参数保留了模型对社会数据性质的认知。作者设计了一个GNN encoder来进行消息嵌入,其中Extractor从相邻信息嵌入中提取有用的信息,而Aggregator则是对相邻信息嵌入的聚合,采用图注意力机制使得模型的𝐸𝑥𝑡𝑟𝑎𝑐𝑡𝑜𝑟(·)和𝐴𝑔𝑔𝑟𝑒𝑔𝑎𝑡𝑜𝑟 (·)并不像传统方法一样假定一个固定的图结构,而是考虑源信息和其相邻信息的表征之间的相似性,这样模型才能做增量学习并嵌入以前未见过的信息。
在训练阶段,随着新信息的不断到来,可能会有一些新的事件是模型以前没有见过的。交叉熵损失函数虽然被各种GNN广泛采用,但在本场景中已不再适用。作者转而构建一个对比性的三联体损失,使KPGNN能够区分事件而不限制其总数。Triplet loss在嵌入空间中把来自同一类的消息推近,把来自不同类的消息推远,而Global-local pair loss通过最大化局部信息表征和全局图表征之间的互信息,帮助更好地学习图结构信息。此外,为了适应大型社交图,模型在训练过程中采用了小批量的子图采样,并且模型定期恢复训练以保持模型的知识更新。
在检测阶段,模型根据所学到的信息表征对信息进行聚类。聚类算法有基于距离的聚类算法,如K-Means和基于密度的算法,如DBSCAN。其中, DBSCAN不需要指定类的总数,因此适合于增量检测的需要。
8 实验结果
实验准备:
实验环境:64 core Intel Xeon CPU E5-2680 v4@2.40GHz with 512GB RAM and NVIDIA Tesla P100-PICE GPU.
数据集:
Ø Twitter数据集(http://mir.dcs.gla.ac.uk/resources/),包含68,841条手动标记的推文,与503个社会事件类别相关,分布在四周的时间内。
Ø MAVEN数据集(https://github.com/THU-KEG/MAVEN-dataset),包含10,242条信息(维基百科文档中的句子),与154个事件类别相关。
评估指标:
主要是衡量检测到的消息集群与真实集群之间的相似性。
Ø 标准化互信息,Normalized mutual information(NMI)
Ø 调整互信息,Adjusted mutual information (AMI)
Ø 调整兰德系数,Adjusted rand index (ARI).
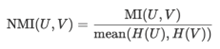
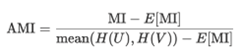
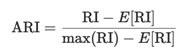
离线社会事件检测实验:
实验结果:作者随机抽取70%、20%和10%的数据进行训练、测试和验证,并在离线情况下比较这些模型。KPGNN在两个数据集的所有指标中得分最高或第二高。
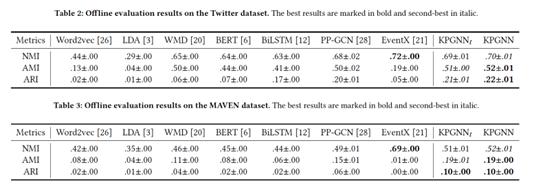
增量检测实验:
实验结果:在实验中将Twitter数据集按日期分成信息块(M1,M2,…,M21)来构建一个社会流,并在增量检测的情况下比较各种模型。第一周的信息组成一个初始信息块𝑀0,用其余每一天的信息组成余下的信息块。KPGNN效果明显且持续地超过了基线模型。例如,与EventX相比,它在NMI方面取得了高达27%(平均16%)的相对性能提升,与BERT相比,高达19%(平均7%),与PP-GCN相比,高达67%(平均47%)。
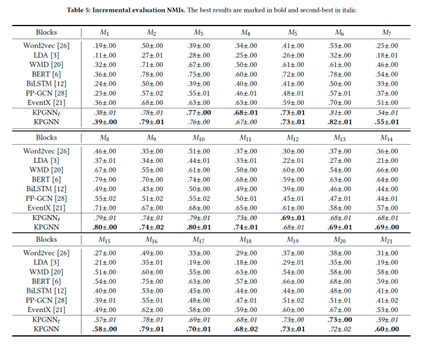
不同更新维护策略实验:
实验结果:采用不同更新维护策略的KPGNN。(a)、(b)和(c)显示了采用不同更新维护策略时KPGNN的NMI、AMI和ARI性能。在(d)和(e)中,我们对KPGNN在维护阶段的一个小批次进行训练,并测量时间和内存消耗。(d)显示了训练KPGNN的时间(秒),用于一个小批量。(e)显示了整个训练过程中使用的GPU%。对不同的维护策略的研究表明,总是使用最新的信息来重建图(在检测阶段)和恢复训练(在维护阶段)会得到最高的性能和最低的时间和内存消耗。
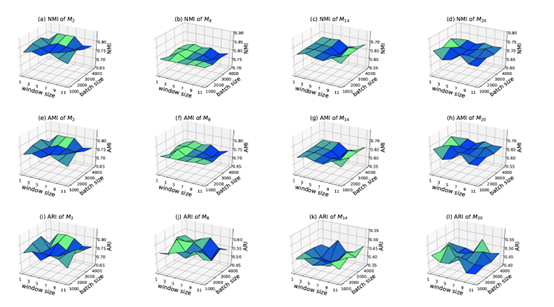
超参数敏感性实验:
实验结果:KPGNN具有不同的超参数。我们展示了KPGNN在信息块𝑀2、𝑀8、𝑀14和𝑀20上采用不同的窗口大小和小批量大小时的表现。(a)-(d)显示NMI,(e)-(h)显示AMI,(i)-(l)显示ARI。颜色表示波动值:凹陷区域用蓝色,凸起区域用绿色。对改变窗口大小以维持KPGNN和小批量大小的影响的研究表明,KPGNN对超参数的变化不敏感。
9 本文不足
- 对比模型较为基础简单,没有充分体现模型的优势;
- 转换为同质图后,异质信息图中的大量信息没有用上;
- 在新事件数据中训练模型时可能需要标注数据(仅靠hashtag标签无法保证事件类别的准确性)
10 代码和数据集地址
Github链接: https://github.com/RingBDStack/KPGNN