阅读笔记作者:金地
1 原文作者
Santhosh Rajamanickam (ILLC, University of Amsterdam),
Pushkar Mishra (Facebook AI),
Helen Yannakoudakis (Dept.of Informatics, King’s College London),
Ekaterina Shutova (ILLC, University of Amsterdam),
2 论文来源
ACL(2020)
3 论文地址
https://doi.org/10.18653/v1/2020.acl-main.394
4 论文简介
- 研究背景
网上的攻击性和辱骂性行为会给受害者带来严重的心理后果,这就强调了自动检测滥用语言的技术的必要性。滥用(Abusive)一词统指所有诋毁或冒犯个人或群体的表达形式,包括种族主义、性别歧视、人身攻击、骚扰、网络欺凌等等。所有现有的方法都集中在对评论的语言属性或关于用户的元数据进行建模(RNN、CNN、基于字符的模型、基于图的学习方法……),忽略了用户的情绪状态以及这可能对其语言产生的影响。
- 研究内容
提出并评估了不同的MTL(Multitask Learning)架构
- 研究结论
MTL模型在两个不同的滥用检测数据集中的表现明显优于STL(Single-task Learning);
加入情感特征有助于滥用检测;
MTL性能优于迁移学习。
5 解决问题
提出对滥用性语言检测和情绪检测进行联合建模,并提出了第一个通过多任务学习(MTL)范式纳入情感特征的滥用性语言检测方法。
6 本文贡献
- 提出了一种新的滥用检测方法,通过MTL框架,利用情感特征来获得辅助知识。
- 实验证明,带有情感检测的MTL对Twitter领域的滥用性语言检测任务是有帮助的,为改进其他领域的滥用检测系统开辟了新的研究途径。
- 证明MTL比STL在滥用检测方面更加具有优势。在此基础上研究者可以建立更复杂的模型,为滥用检测引入新的辅助性任务。
7 论文方法
首先提出了两种不同结构的STL模型作为基线。
1.Max Pooling and MLP classifier(后续实验中称为STLmaxpool+MLP)
使用两层的双向LSTM获得单词的嵌入表示,以获得上下文的词汇表征,然后进行最大池化操作。

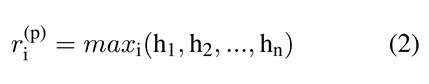
然后进行丢弃正则化和2层的MLP(Multi-layer Perceptron)。
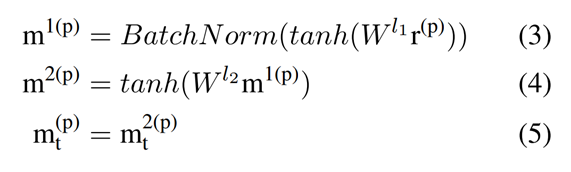
对于OffensEval,在二分类中应用sigmoid激活函数,使二值交叉熵(BCE)最小。
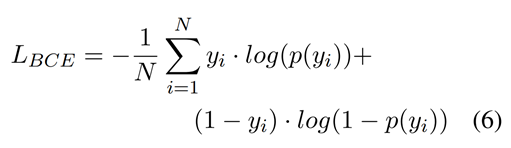
对于Waseem&Hovy,在多分类中应用log_softmax激活函数,使负对数似然(NLL)最小。
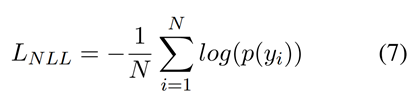
2.BiLSTM and Attention classifier(后续实验中称为STLBiLSTM+attn)
这里对 h 不进行最大池化,而是采用dropout + BiLSTM + Attention。
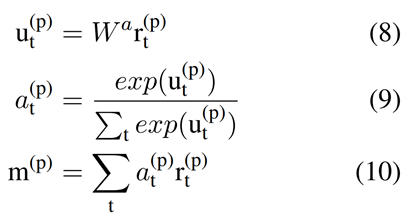
输出层、激活函数与STLmaxpool+MLP相同。
此外,在两个STL基线中,进一步试验了两种不同的输入表示。
- GloVe (G):输入通过GloVe嵌入层;
- GloVe + ELMo (G+E):输入分别通过GloVe嵌入层和ELMo嵌入层,并将其输出串联得到最终的词汇表征。
因此,共有4个不同的基线模型用于滥用检测,使用网格搜索(Grid Search)来调整主线任务(滥用检测)的验证集上的超参数。
接着,本文提出了3种MTL架构。
1.Hard Sharing Model(后续实验中称为MTLHard)
两个任务共享堆叠的BiLSTM编码器和嵌入层。如下图所示,中虚线框代表了STLBiLSTM+attn架构,该架构专门用于滥用检测任务。
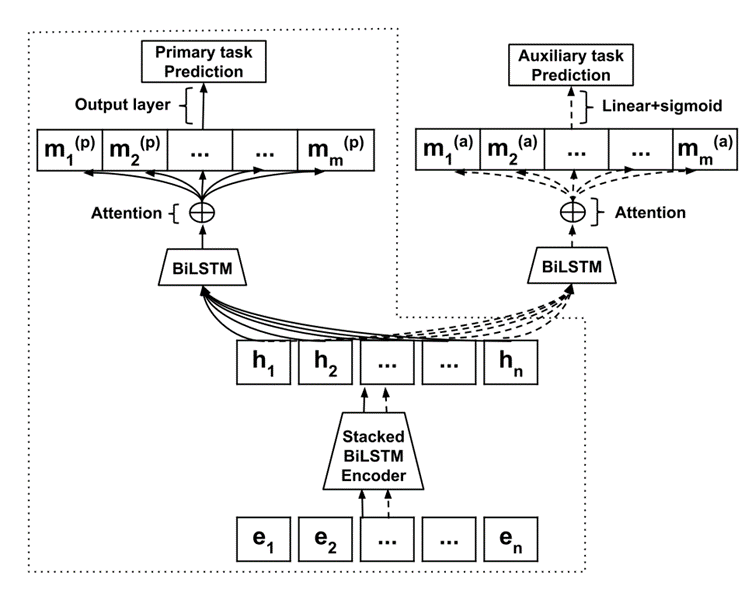
Primary task:滥用检测
对模型进行优化时使用二值交叉熵(BCE)或负对数似然(NLL)
Auxiliary task:情感检测
对模型进行优化时使用二值交叉熵(BCE)
2.Double Encoder Model(后续实验中称为MTLDEncoder)
该模型为MTLHard模型的扩展。
使用2个BiLSTM编码器,分别为针对主要任务的2层的BiLSTM编码器、共享的2层的BiLSTM编码器。
图中α(p)和α(s)为固定值,设置为1。
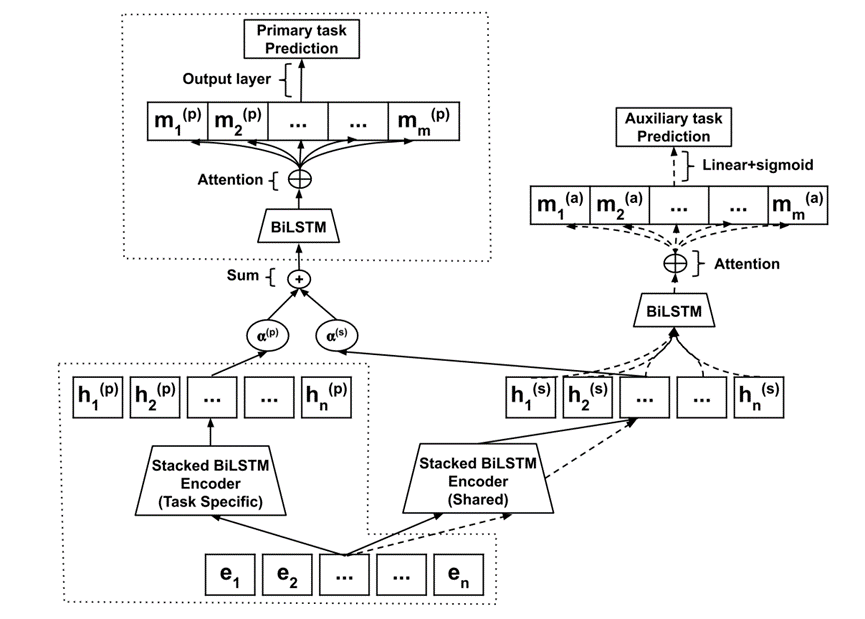
3.Gated Double Encoder Model(后续实验中称为MTLGatedDEncoder)
该模型为MTLDEncoder模型的扩展。
但将α(p)和α(s)改变为两个可学习的参数(其中,α(p)+α(s)=1.0),合并表征h(p)和h(s),以控制来自两个编码器的表征的信息流。
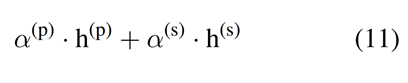
8 实验结果
本文实验部分共选取了两个滥用检测数据集和一个情感数据集。
Abuse detection task
- OffensEval 2019 (OffensEval):
- 包含13240条有注释的推文
- 被分类为offensive (33%) or not (67%),其中攻击性语言包含侮辱、威胁、亵渎性语言和脏话。
- Waseem and Hovy 2016 (Waseem&Hovy):
- 由Waseem和Hovy通过搜索与宗教、性、性别和少数民族相关的常用污蔑和辱骂性词语构建。
- 共包含16202条推文
- 被注释为racism (1939,12%) /sexism (3148,19.4%) /neither (11115,68.6%)
Emotion detection task
- Emotion (SemEval18):
- 来自SemEval-2018的任务1
- 包含大约11k条推文(训练集:6839,验证集:887,测试集:3260)
- 采用11种情感标签进行多标签分类(anger, anticipation, disgust, fear, joy, love, optimism, pessimism, sadness, surprise, trust)
首先在滥用检测数据集上独立进行STL实验,在每个数据集上选择效果最好的STL模型配置,作为MTL实验中相应MTL架构的一部分(最好的结果用粗体标出)。
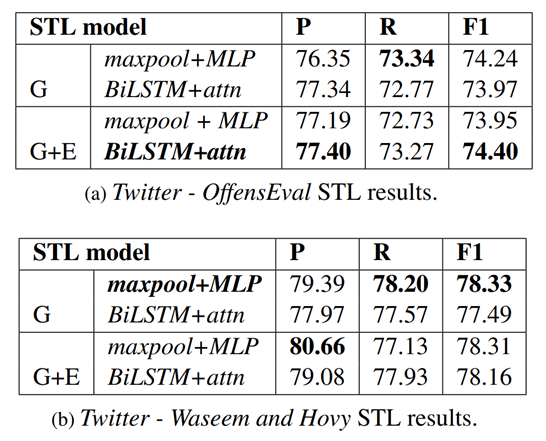
接着,测试将情感检测作为一个辅助任务是否能提高滥用检测的性能。
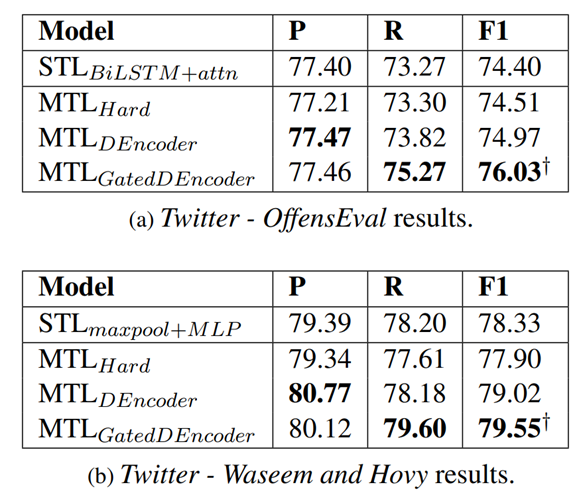
†表示比相应的STL模型有统计意义的结果(使用配对t检验(paired t-test))。
结论:MTLGatedEncoder在F1方面取得了统计学上的重大改进,表明来自共享编码器的情感特征有利于滥用检测任务
最后,将效果最好的MTL模型与相同模型在迁移学习环境下的效果进行对比。
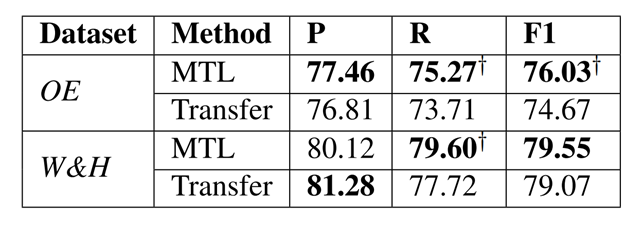
结论:MTL效果优于迁移学习。
9 本文不足
introduction中提到目前大部分研究集中在检测明确的语言滥用(辱骂、贬低、威胁…),其也可以通过更隐蔽和微妙的方式出现(模棱两可的术语、象征性的语言…),但论文中并没有提到对该类的语言滥用识别效果是否有提升。
10 代码和数据集地址
未提供