Intentions and Implicit Attack Detection
阅读笔记作者:周涛昱
1 原文作者
Maryam Sadat Mirzaei, Kourosh Meshgi, Satoshi Sekine
(RIKEN Japan)
2 论文来源
WWW ’22, April 25–29, 2022, Virtual Event, Lyon, France.
3 论文地址
4 论文简介
研究背景:大量的研究已经调查了显性仇恨言论攻击,而且仇恨言论的破坏性得到了广泛的认识和充分的研究,但很少有人关注隐性攻击案例和对话谈话行为。而在没有识别出隐性攻击的情况下,这种现象变得更加复杂,因为一个行为可能被认为具有负面意图而引发冲突。
根据这些例子,作者做出了一个合理的假设是,问一个问题会极大引发隐性仇恨冲突。对话是由几句话组成的,其中提出的问题是我们重点关注目标。
因此,在本研究中,目的是从读者的角度分析问题背后的感知意图、问题中的隐性攻击的实例,以及使用问题作为攻击工具的可能性。全文围绕着以下几个研究问题进行讨论:
RQ1:问题能否被用作攻击某人的手段?
RQ2:问题是否可以包括不明显或者明显的人身攻击,但仍然被认为是负面的?
RQ3:人们的观点和忍受的阈值的不同会导致对一个问题的有几种不同的解释吗?或者我们该如何基于不同的视角来感知发送的消息?
RQ4:我们能检测到一个问题的意图极性并识别问题中的隐性攻击吗?
研究结论:一个问题可以作为攻击某人的手段,并且隐形仇恨攻击与其意图有一定关联
5 解决问题
RQ1:问题能否被用作攻击某人的手段?
RQ2:问题是否可以包括不明显或者明显的人身攻击,但仍然被认为是负面的?
RQ3:人们的观点和忍受的阈值的不同会导致对一个问题的有几种不同的解释吗?或者我们该如何基于不同的视角来感知发送的消息?
RQ4:我们能检测到一个问题的意图极性并识别问题中的隐性攻击吗?
6 本文贡献
- 提供注释方法并收集关注问题的意图和攻击类型的数据集
- 从读者的角度收集感知意图,并对问题的不同用例进行了分类,尤其是当意图既不积极也不中立时
- 得到感知的意图和攻击的识别是相互关联的
7 论文方法
7.1问题能否被用作攻击某人的手段?
1.最常引起冲突的对话通常是简单的批评、指责和嘲笑
2.负面意图的问题会导致隐性攻击,引发冲突
3.高达百分之60的隐性攻击占比说明问题能作为攻击某人的手段

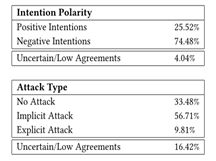
7.2问题能否包括不明确或明显人身攻击,但仍是负面的?
文章分别定义了问题在对话的前后位置:
- 问题极早的就出现在对话中,远远早于发生言语攻击的时候(earlier than personal attack)
- 在涉及言语攻击前(prior to personal attack)
- 在言语攻击的评论之中(within personal attack)
- 不包括言语攻击的对话(no personal attack)
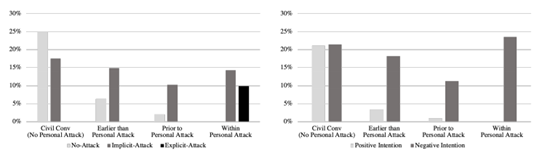
无论是文明对话还是人身攻击,都包含带有隐性攻击的问题。由此可以得到,隐式攻击类别几乎均匀地分布在所有位置,这表明此类问题在对话中经常使用。这些带有隐性攻击的问题可以是包含在言论攻击之中,也可以出现在言论攻击之前,这突出了它们在引发冲突中的作用。然而,相比于隐式攻击使用问题的显式攻击只发生在人身攻击之中,通常是在进行中或在使用辱骂性语言之后。这可以更好的分别两类攻击。
在文章中假设,在涉及语言攻击前和在语言攻击的评论之中的问题更有可能具有负面意图,而那些出现在无攻击或远远早于发生语言攻击的时候的问题不太可能具有负面意愿。但是,这些数据表明,即使是极早的出现在对话中也同样有负面意愿的问题,也就是说,无论问题出现在哪里,都有可能引发负面情绪。
7.3不同视角是否有不同解释?
- 区分积极和负面意图并不总是直截了当
- 区分意图极性比决定一个问题是否具有隐性、显性或无攻击性困难得多更需要通过上下文提示来分类
- 人们受到冒犯的阈值和攻击的目标不同,导致了人们的视角和容忍阈值都在解释问题的意图方面发挥作用

上图意思是最初,你所做的只是暗示这篇文章不够全面,我们通过解释这篇文章只涉及探索研究所定义的智能设计来解决这个问题。从那以后,你提供什么样的解释?我们拒绝了哪些有用的解释?
人们可以将这个问题视为问题的初衷是陈述事实来情况。另一方面,人们可以将此视为一种侮辱性评论,暗示用户自上一次以来没有提供任何有用的信息。从这个例子中,可以讨论读者对问题的看法是否会在很大程度上影响解释。根据我们的观察,在选择无攻击和隐性攻击案例时,大多数分歧与人们的观点/观点有关,导致了两种不同但可能的解释。所以人们受到冒犯的阈值和攻击的目标不同,导致了人们的视角和容忍阈值都在解释问题的意图方面发挥作用。
7.4我们能检测到意图极性并识别问题中的隐性攻击吗?
建立了两个模型,一个用于检测意图极性,另一个用于对我们的数据集中的攻击类型进行分类,以解决问题。
- 意图检测
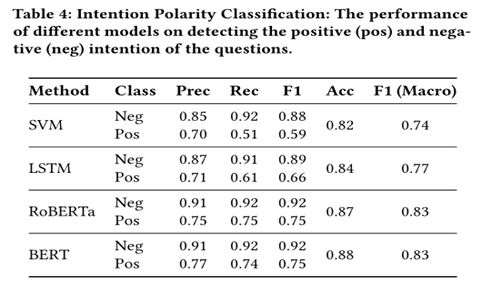
在检测意图时 我们可以看到SVM和LSTM分类器不能很好地处理积极(中立)案例。一个观察结果是,负面意图案例中包含了更具体的词语,这些词语将表明问题的负极性,而这种独特的词语在积极案例中并不常见;因此,这些分类器无法准确区分这两个类。此外,多头注意力和位置嵌入都提供了关于不同单词之间关系的信息。鉴于上下文为解释问题提供了洞察力,BERT是处理我们任务的更好模型。
然而,我们注意到,由于问题的复杂表述,BERT未能捕捉到一些案例,特别是那些涉及礼貌但传达负面意图的案。比如:是我的浏览器,还是你最近的进化逆转毁了了文章的结尾?”分类器未能将其正确标记为否定意图。
- 隐性攻击检测
比较了我们的分类器在检测三类攻击方面的性能。结果表明,BERT模型在区分攻击类型方面仍然是竞争对手中最强大的分类器,RoBERTa仅略优于BERT。SVM和LSTM在区分显式攻击案例方面表现不佳。显性攻击和隐性攻击之间的界限并不总是明确的,这取决于容忍攻击的阈值、文化背景和个人背景。
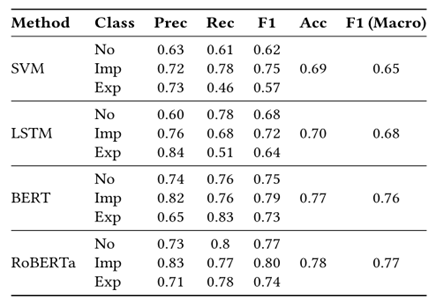
此外,将较轻威胁的声明与隐式攻击的问题相结合,意味着一个复杂的案例
现有模型还无法识别复杂案例如:
“我无意冒犯,但你读过书吗”
“你是一个五岁的孩子吗?