1.原文作者
Bing Tian, Yong Zhang, Chunxiao Xing(Tsinghua University)Jin Wang(University of California)
2.论文来源
Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19)
3.论文地址
https://www.ijcai.org/proceedings/2019/0495.pdf
4.论文简介
文档分类是许多实际应用中的一项基本任务。现有的方法采用文本语义和文档结构来获取文档表示。然而,这些模型通常需要大量的人工训练实例,这些实例并不总是可行的,尤其是在资源不足的环境下。在本文中,我们提出了一个多任务学习框架来联合训练多个相关的文档分类任务。我们设计了一个层次结构来利用来自所有任务的共享知识来增强每个任务的文档表示。我们进一步提出了一种相互关注的方法来改进具有全局信息的文档的任务特定建模。在15个公共数据集上的实验结果证明了我们提出的模型的优点。
5.解决问题
深度学习模型总是包含大量参数,需要大量标记语料库来学习良好的文档表示。然而,在许多情况下,因为获取手动标记的文档非常昂贵,很难获取大量有标签数据构建和训练大型模型。在这种情况下,由于缺乏训练数据,此类模型的性能将受到限制。
以前的多任务学习也被用在一般的NLP任务上,但是可能不适合文档分类,因为它们无法捕获文档的层次结构。其次,它们直接使用RNN的变体对文档进行编码,而忽略了文本的不同部分在确定文档语义方面可能做出不同贡献的事实。
本文通过将15个文本分类相关的数据集统一输入到多任务学习框架中来联合训练,提取出所有任务的共享知识来增强每个任务的分类准确率,并且通过相互注意力机制,在不同任务之间互相学习注意力权重。
6.本文贡献
提出MT-HIA模型(Multi-Task Hierarchical Inter-Attention Network):
- 提出了一个多任务学习框架来联合训练多个相关的文档分类任务;
- 设计了一个层次结构,利用所有任务的共享知识来增强每个任务的文档表示;
- 提出了一种Inter-Attention机制,任务之间可以互相学习注意力权重;
最终在15个公共数据集上的实验结果证明了模型在大多数数据集上性能更优。
7.论文方法
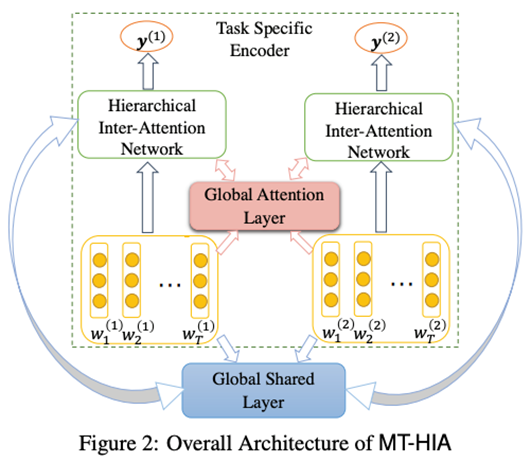
本文提出的模型分为两个部分:
- Task Specific Encoder:特定任务编码器
- Global Attention Layer & Shared Layer:全局共享层
如图所示,其中1体现分层Hierarchical理念,层级间的交互注意力机制则在2中的Attention Layer得到具体实现;2中的Shared Layer实现单词和句子的共享信息表示。
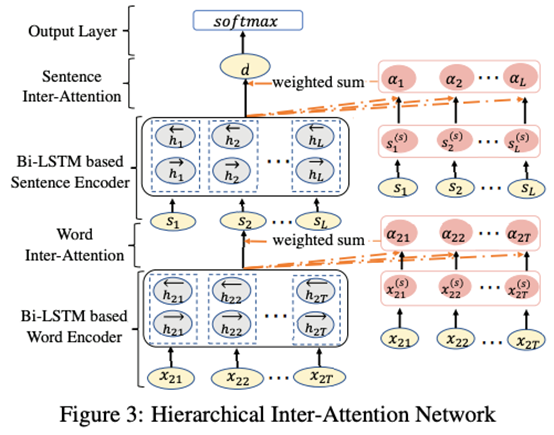
本文提出的模型将从单词层面和句子层面分别进行特征表示,分别在单词表示组成句子表示、句子表示组成文档表示的过程中应用Inter-Attention交互注意力机制。同时,训练一个共享MLP层获取单词的共享表示,再计算单词注意力权值,获得句子表示。句子表示到文档表示则类似。
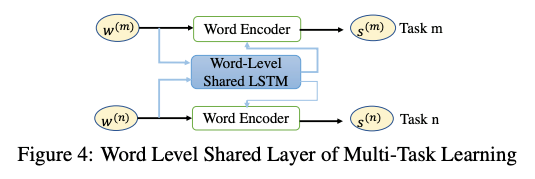
在获取单词表示时,本文利用Bi-LSTM单元的选通机制来控制从全局共享层到每个任务的信息流的传输。如图,g(k)是基于当前时间步长下,单词表示x和经过LSTM后的表示的关联强度,控制全局共享层流向特定任务的信息流比率。对于句子的Bi-LSTM单元同理。
8.实验结果
8.1实验准备:
环境:未提供硬件环境与软件环境信息。
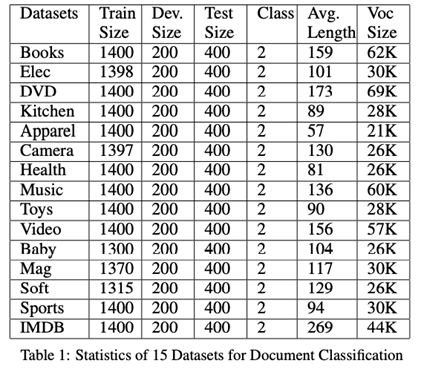
数据集:
14个数据集是来自不同领域的亚马逊产品评论,1个数据集来自IMDB电影评论。
训练方式:
对于多任务学习,用于训练每个任务的标记数据可以来自完全不同的数据集。训练过程通过循环任务以随机方式进行:
- 选择一个随机任务。
- 从该任务中选择一小批示例。
- 更新此任务的参数以及与此小批量相关的全局共享层。
- 返回1。
在联合学习阶段之后,我们可以使用微调策略进一步优化每个任务的性能。
8.2实验结果:
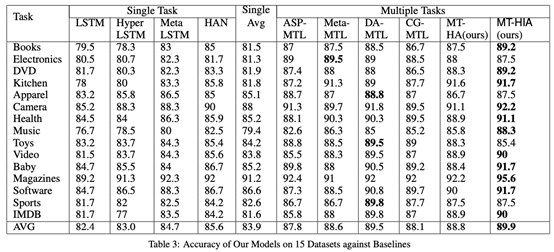
8.3实验分析:

左边即本文最终模型,右边将交互注意力机制从模型中去除掉了。可以看到,MT-HIA能够从其它任务中学习到“Although…I was…”语法的语义,从而选择忽略文本中的第四句话,将注意力集中在第五句话上,最终获得了准确的预测结果。
9.个人收获
1.在文本数据标注中,时间成本耗费太高,可以参考文章中提到的多任务训练的方式,从公开数据集中学习单词的语义知识,以类似迁移学习的方式运用到其他任务中来提高预测准确率。
2.由于立场检测与情感分类任务在某种程度上,都是需要根据文本中的语义信息来进行判定,可以在有限的立场检测数据集的基础上,额外用情感分析数据集来共同训练LSTM单元,来提升网络能够感知的语义信息范围。
3.文中提到的层级注意力机制是文本分类常用的方法,可以借鉴。
10.代码和数据集地址
未提供