1 原文作者
Xianbing Zhou(Xinjiang Normal University),
Yong Yang(Xinjiang Normal University),
Xiaochao Fan(Xinjiang Normal University),
Ge Ren(Xinjiang Normal University),
Yunfeng Song(Xinjiang Normal University),
Yufeng Diao(Dalian University of Technology),
Liang Yang(Dalian University of Technology),
Hongfei Lin(Dalian University of Technology).
2 论文来源
ACL(2021)
3 论文地址
https://aclanthology.org/2021.acl-long.556/#
4 论文简介
- 研究背景
随着移动互联网和社交媒体的盛行,仇恨言论的恶意传播现象逐渐泛滥成灾。这往往会造成不可估量的后果,已经成为一个严重的社会问题。如何快速、准确地自动检测出仇恨言论,进而更好地进行干预防范,已成为自然语言处理领域的研究热点之一。对仇恨言论的自动检测可以防止仇恨言论的病毒式传播,从而减少网络欺凌和有害信息的恶意传播。在舆情分析、监控和干预领域,仇恨言论检测具有广泛的应用价值。
- 研究内容
本文作者提出了一个基于情感知识共享的仇恨言论检测框架(SKS)。在提取目标句子本身的情感特征的同时,更好地利用了来自外部资源的情感特征,并最终融合了来自不同特征提取单元的特征来检测仇恨言论。最后,在两个公共数据集上的实验结果证明了该模型的有效性。
- 研究结论
在本文中,作者探讨了多任务学习在仇恨言论检测任务中的有效性。其主要思想是利用多个特征提取单元来共享多任务参数,使模型能更好地共享情感知识,然后利用门控注意力来融合特征进行仇恨言论检测。其提出的SKS模型可以充分利用目标和外部情感资源的情感信息。实验结果表明,情感知识共享比基线提高了系统性能,并推进了仇恨言论检测。最后,详细的分析进一步证明了SKS模型的有效性和可解释性。
5 解决问题
近年来,仇恨言论的检测受到了许多关注,出现了许多研究成果。然而,由于自然语言结构的内在复杂性,这项任务是相当有挑战性的。大多数现有的工作都围绕着规则或人工特征提取。基于规则的方法不涉及学习,通常依赖于预先编译的主观性线索的列表或字典。Chen等人(2012年)提出了各种语言学规则,以确定一个句子是否构成仇恨言论。例如,如果第二人称代词和贬义词同时出现,如”<you,gay>”,该句子就被判定为侮辱性的。这类方法不仅需要人工制定规则,而且还需要贬义词的字典。也有很多人尝试用传统的机器学习方法来检测仇恨言论,但人工特征只能反映文本的浅层特征,无法从深层语义特征中理解内容。
深度学习方法也被广泛应用于仇恨言论检测领域,并取得了良好的表现。仇恨言论的语义包含强烈的负面情绪倾向,前人的深度学习方法往往只使用预训练的模型或更深层次的网络来获得语义特征,忽略了目标句子的情感特征和外部情感资源,这也使得神经网络在仇恨言论检测中的表现不尽人意。
为了克服以往工作的弱点,本文提出了一个基于情感知识共享(SKS)的仇恨言论检测框架。大多数仇恨言论都包含有强烈负面情绪的词汇,这可以作为仇恨言论的最直接线索。同时,Davidson等人的研究表明,词汇检测方法往往精度不高,因为它们将所有包含特定词汇的信息都归类为仇恨言论。因此,本文作者希望能够更好地利用外部情感资源,使模型能够学习情感特征并共享,这将大大影响仇恨言论检测的性能。
6 本文贡献
- 鉴于以往工作中缺乏对情感信息的利用,本文不仅将目标句子的贬义词整合到神经网络中,还利用多任务学习使模型学习并共享外部情感知识。
- 为了更好地捕捉共享的任务或特定任务信息,本文提出了一个新的框架,该框架使用多个特征提取单元,每个提取单元使用多头注意力机制和前馈神经网络来提取特征,最后使用门控注意力融合特征。
- 在SemEval-2019 task-5和Davidson数据集上的实验结果表明,与强大的基线相比,本文的方法取得了最先进的性能,然后进一步详细的例子验证了我们提出的模型在仇恨言论检测方面的有效性。
7 论文方法
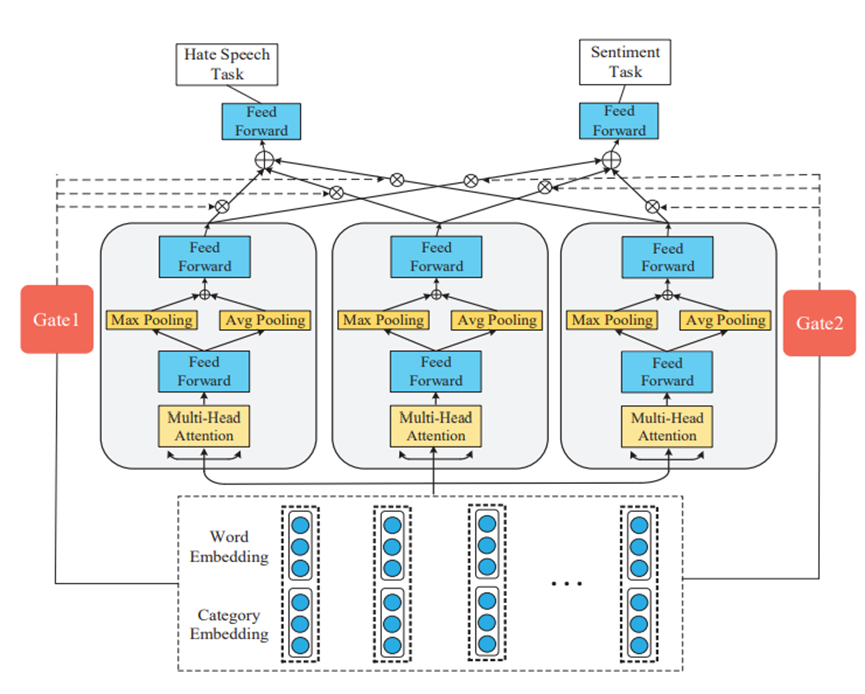
SKS的整体架构如图 1所示。该框架主要由三层组成:1)输入层。使用贬义词词典来判断每个词是否是仇恨词,然后将类别信息附加到词嵌入中;2)情感知识共享层。使用多任务学习框架以利用共享情感知识;3)门控注意力层。针对不同任务,通过Gate得到不同的权重指数。最后,由前馈神经网络对仇恨言论进行检测。
- 输入层
首先,使用词嵌入将每个词转化为实值向量。
由于强烈的负面情绪,仇恨言论往往包含明显的负面情绪词汇。因此,本文建立了一个贬义词词典。词汇来自维基百科(https://www.wikipedia.org/)和另一个网站(https://www.noswearing.com/),包括仇恨言论、残疾人、LGBT、种族和宗教,共5个类别。由于该词汇包含2或3个词组,在判断是否为贬义词时,使用n-gram,n∈[1,2,3]。
贬义词词典用于将推文分为两类,即包含贬义词或不包含贬义词,然后为推文中的每个词分配这两个类别。每个词的类别被随机地初始化为向量,并附加到词嵌入中。
- 情感知识共享层
由于受到不同国家、地区、宗教和文化的影响,许多语言中的侮辱性含义隐藏在潜在的语义中,而不仅仅是反映在情感词中。
深度学习方法需要大量的标记数据进行监督学习,这需要很多的人力和对这项特殊任务的预先了解。在仇恨言论检测中,高质量的标注数据是稀缺的,这使得该任务中对词语存在定型以及固有的偏见训练。情感分析的研究已经进行了很多年,有丰富的高质量标记数据集。两个任务之间存在着高度的相关性,多任务学习可以利用多个任务之间的相关性来提高模型在每个任务中的性能和泛化能力。因此,本文采用多任务学习的方法进行情感知识共享,从而更好地提取情感特征并应用于仇恨言论检测。
多头注意力机制使用线性变化将输入向量X映射到query、key、value,在本任务中,key=value。然后,该模型通过l-time注意力学习单词之间的语义特征。
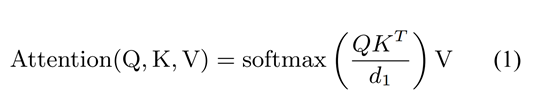
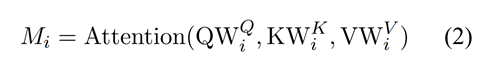
将通过多头注意力机制得到的向量连接起来,得到最终的特征向量。
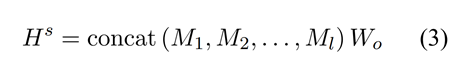
在池化层同时使用最大池化和平均池化对特征进行融合。
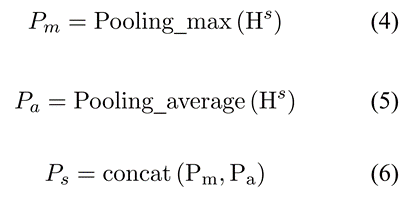
- 门控注意力层
门控注意力机制选择特征提取单元的子集作为输入,对于不同的任务,模型的权重选择不同。特定门的输出k代表不同特征提取单元的被选择的概率,多个单元加权求和,得到句子的最终表示。

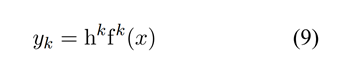
在训练过程中对整个网络的参数进行优化,选用经过L2正则化的交叉熵函数作为损失函数。

8 实验结果
本文实验部分共选取了两个仇恨言论数据集和一个情感数据集,如图 2所示。

其中,SemEval2019 task5 (SE)来源于来自SemEval 2019任务5的子任务A,该数据集被分为3个子集,训练集为9000,验证集为1000,测试集为1271;Davidson dataset (DV)由Davidson构建,其数据来源于Tweet,但该数据集为一个不平衡数据集,仇恨言论较少;Sentiment Analysis (SA)来自Kaggle2018的情感数据集。SA包含更多的正面案例,但负面案例较少。由于测试集无标签,这里只使用训练集。
在实验过程中,选用Acc和F1作为衡量标准。
在实验中,对于输入层,所有的词向量都由Glove Common Crawl Embeddings(840B Token)进行初始化,维度为300。类别嵌入为随机初始化,维度为100。对于情感知识共享层,多头注意力有4个头。第一个前馈网络一层,共400个神经元,第二个两层,共200个神经元。每层之后都使用了dropout,其比率为0.1。优化器为RMSprop,学习率为0.001。模型由512个实例的小批量训练而成。为了防止过度拟合,在训练过程中使用学习率衰减和提前停止。
本文将其所提出的模型与一些已有的方法进行了对比,实验结果如图 3所示。
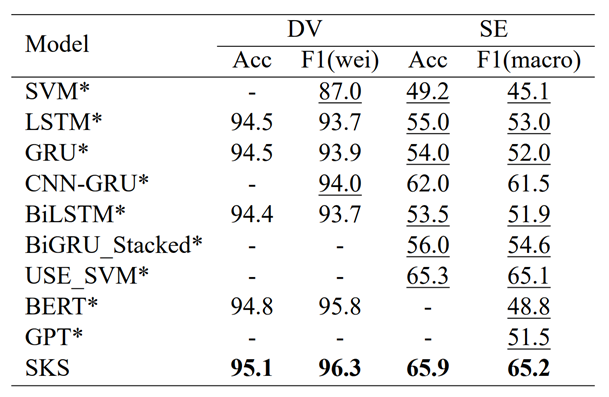
从实验结果可以看出:
- 总的来说,SKS模型在两个数据集上的表现是相当不同的。对于DV数据集,F1值约为90%,而对于SE数据集,F1值不到60%。这主要是因为DV中的负面例子很少,模型没有学到足够有用的特征。此外,语言的细微差别会大大影响模型的性能。基于特征的SVM的性能比神经网络差很多。特别是在SE数据集上,性能是不可接受的。这表明,神经网络可以更好地捕捉词汇的语义关系,以用于仇恨言论的检测。
- 传统的RNNs,如LSTM和GRU,其性能几乎相同。混合神经网络的性能优于简单的递归神经网络(RNN)。与传统的RNNs,如LSTM等相比,无论是CNNGRU还是BiGRU-capsule,其性能都有小幅提升。通过将神经网络的一个层堆叠到另一个层上,深度学习模型有助于更好地学习高层特征。
- BERT在DV数据集上取得了很好的性能。然而,BERT和GPT在SE数据集上都取得了较差的性能。实验结果表明,预训练模型非常依赖于训练数据。
- 与其他神经网络,包括LSTM、GRU和BiLSTM相比,SKS在DV数据集上的F1值提高了近3%,在SE数据集上,F1值提高了近10%;与Universal Encoder相比也更具优势,SKS更易实现且参数更少。
此外,本文还做了消融实验,分析模型的不同部分对于实验结果的影响。实验结果如图 4所示,其中”-sc”表示消减情感知识共享和类别嵌入;”-s”表示不使用情感数据作为模型的输入,而只使用类别嵌入。
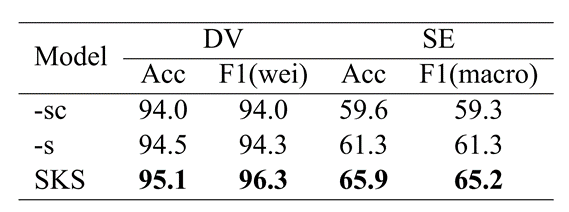
根据实验结果,可以看到:
1)消减情感知识共享和类别嵌入之后,模型在两个数据集上的性能明显下降。但该模型的性能仍优于现有的混合神经网络,说明这个框架可以更好地学习目标句子的潜在语义特征。
2)加上类别嵌入后,模型的性能略有提高。主要原因是贬义词的信息与仇恨言论高度相关,但这也会使模型过于敏感。因此,直接提取贬义词的情感特征对性能的影响有限。
3)SKS的性能最优,证明了共享情感知识的有效性。
同时,作者还分析了门控注意力机制我们模型中的作用。如图 5所示,使用门控注意力机制时,模型的性能在两个数据集上都进一步提升。每个门控网络可以学习选择在输入案例上使用哪个特征提取单元。如果任务是高度相关的,那么共享知识将获得更好的性能。

最后,作者分析了情感数据集的规模对模型性能的影响。由于DV数据集的规模与SA数据集相似,作者将分析的重点放在SE数据集上。
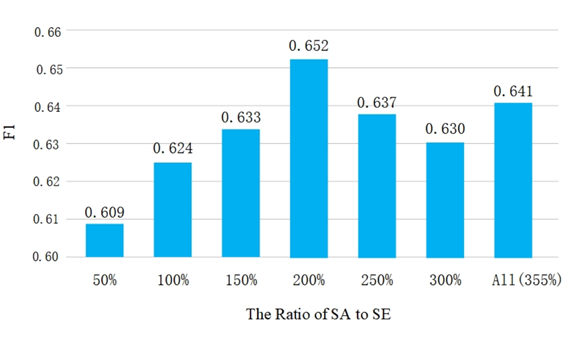
如图 6所示,当两类数据的比例为1:2时,模型的性能很差。随着情感数据比例的增加,模型的性能得到改善。当比例为2:1时,性能达到峰值,然后保持下降趋势。据观察,多任务数据的比例也会直接影响性能。
9 本文不足
仅在两个仇恨言论数据集上进行实验,且其中一个为不平衡数据集。可以尝试在更多数据集上进行实验并将结果进行对比,以证明模型的泛化性。