阅读笔记作者:金地
1 原文作者
Youngwook Kim (Department of Computer Science, Yonsei University, Seoul, Republic of Korea),
Shinwoo Park (Department of Artificial Intelligence, Yonsei University, Seoul, Republic of Korea),
Yo-Sub Han (Department of Artificial Intelligence, Yonsei University, Seoul, Republic of Korea),
2 论文来源
COLING 2022 (CCF-B)
3 论文地址
https://aclanthology.org/2022.coling-1.579/
4 论文简介
- 研究背景
- 仇恨言论是指“任何基于某些特征(如种族、肤色、民族、性别、性取向、国籍、宗教或其他特征)而贬低某个人群的表达”。
- 现有的基于词典或神经网络的方法,难以检测隐性的仇恨言论。
- 当在数据集内评估仇恨言论检测模型性能时,其性能可能会被高估,最好进行跨数据集评估以证明模型的泛化能力。

- 预实验
实验目的:查看隐性仇恨言论检测模型在偏向隐性仇恨的跨数据集上是否仍然表现良好
实验结果:隐性仇恨言论检测模型存在泛化问题
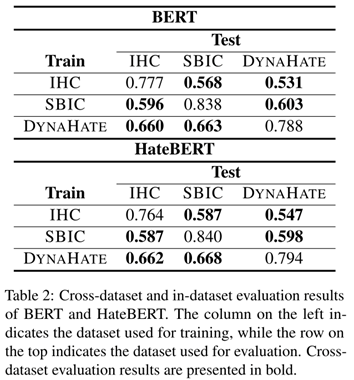
5 解决问题
隐性仇恨言论检测模型在跨数据集的模型泛化问题
6 本文贡献
- 证实了在隐性仇恨言论数据集上微调的预训练语言模型在跨数据集评估中表现相对较差
- 提出在微调隐性仇恨言论检测模型时利用对比学习提升模型的泛化能力
- 提出利用共享暗示作为其对应的仇恨推文的正样本,并引入基于暗示的对比学习方法(ImpCon)
7 论文方法
本文首先提出了对比学习中的两种正采样策略:
AugCon:使用增强后的帖子作为给定帖子的正样本(词法不同,语义相似)
ImpCon:使用暗示(隐藏的真实含义)作为给定仇恨帖子的正样本。一个暗示通常被一组仇恨帖子共享,模型可以学习到同一个暗示下的一组仇恨帖子之间的共同特征

整体的模型架构图如下:
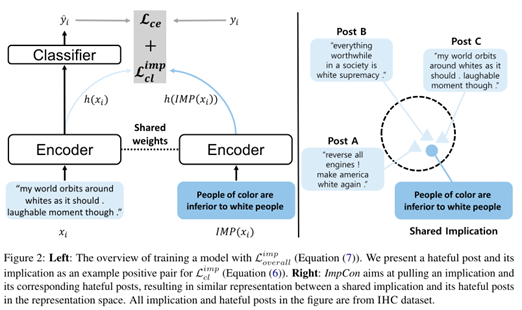
仇恨言论检测模型通常使用交叉熵损失进行有监督的微调。
由于交叉熵损失的限制,仅使用交叉熵损失进行微调可能会导致模型的泛化效果不佳。
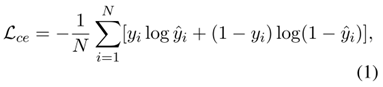
由此,本文提出结合对比损失和交叉熵损失训练可泛化的隐性仇恨言论检测模型。
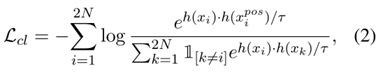
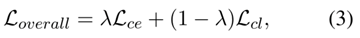
接下来,详细介绍上文中提到的两种正采样策略。
Augmented Post as Positive Samples
隐性仇恨言论微妙且缺乏词汇线索
检测模型易于过度拟合数据集中的非预期词汇偏见
使用词汇不同但语义相似的增强变体作为正样本,模型可以学习到更多不变的语义特征
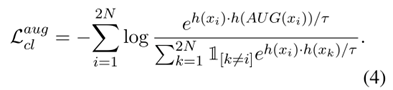

Implication as Positive Samples
仇恨言论传递的是针对群体的、贬低群体的刻板印象和偏见
呈现方式不同的仇恨言论可能暗示类似的有害偏见
使用真实含义作为正样本,模型可以学习到隐性仇恨言论及其隐藏的意义之间的关系
8 实验结果
- 数据集
SOCIAL BIAS INFERENCE CORPUS (SBIC):有层次结构的社会偏见数据集。标注了一句话是否有冒犯性、针对哪个群体、暗示了什么。作者对数据集进行细化,使每条被标注为“隐性仇恨”的样本都有含义。
IMPLICIT HATE CORPUS (IHC):隐性仇恨言论数据集。来自Twitter的仇恨社区及其粉丝。标注了一句话针对哪些群体、暗示了什么。作者将标注进行聚合 implied statement + target = implication。
DYNAHATE:通过任何模型交互的过程收集的仇恨言论数据集,这一过程中人故意欺骗模型。
- Baselines
Cross-entropy Loss (CE):使用交叉熵损失来微调模型
Cross-entropy Loss (CE) with Data Augmentation:运用数据增强(数据扩充与AugCon相同,使用WordNet将30%的词替换为同义词);使用交叉熵损失训练模型。
Cross-entropy Loss (CE) with Supervised Contrastive Learning:使用有监督的对比学习 (SCL) 结合交叉熵损失微调模型。在SCL中,同一个类别的帖子在表示空间中被拉近,而不同类别的帖子被推远。
- 模型对比
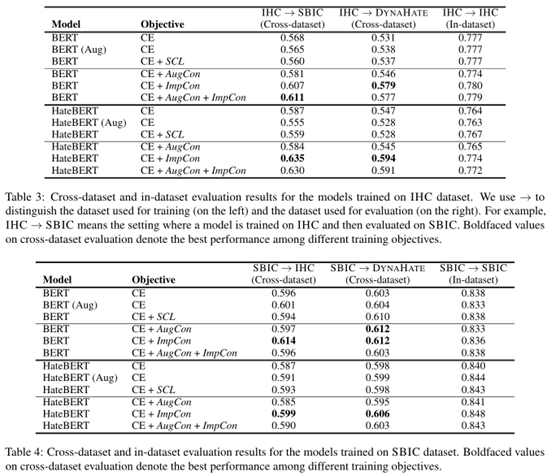
得出结论:
- 只是把一些增强的帖子加到训练集里,对模型的效果没有帮助。
- 仅利用标签信息,使用对比学习的方法,效果不佳。
- AugCon对于BERT效果有所提升,对于HateBERT效果有所下降,证明AugCon效果有限。
- ImpCon对于BERT和HateBERT效果提升明显,证明ImpCon可以提高模型泛化能力。
- 对于数据集内的评估,无论是否使用AugCon和ImpCon,对模型效果影响不大。
实验分析
表示分析-定量分析
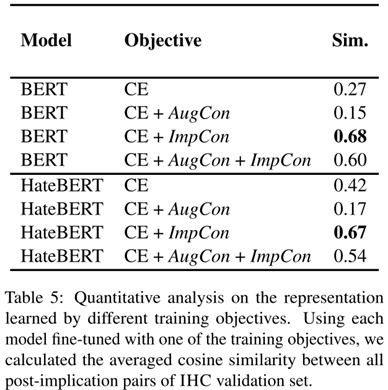
实验目的:探究ImpCon对表示空间的影响
已知:用 ImpCon 训练的模型会把训练集中的帖子-含义对投影的更近
未知:该模型能否将没见过的帖子-含义对也投影的更近
解决方案:用验证集中的帖子-含义对做分析 从表5可以看出,两种用ImpCon的训练目标(CE + ImpCon, CE + AugCon + ImpCon)比其他的相似度高。ImpCon-based训练目标比CE高的相似度证明了ImpCon可以让模型把没有见过的帖子-含义对投影得很近。虽然CE + ImpCon有最高的余弦相似度(BERT上是0.6752,HateBERT上是0.6731),但CE + AugCon + ImpCon有较低的余弦相似度(BERT上是0.6048,HateBERT上是0.5399)。考虑到CE + AugCon有最低的相似度,AugCon似乎阻碍了帖子-含义对被拉近。作者推测这是为什么简单地把AugCon和ImpCon结合起来在4个跨数据集评估中有3个没有得到最好效果的原因之一。
表示分析-定性分析
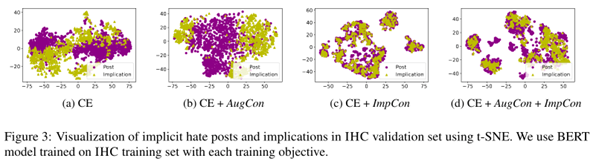
实验目的:探究 ImpCon 对表示空间的影响
使用统计方法 t-SNE,可视化帖子-含义对的特征表示
结论:使用了对比学习目标 (ImpCon) 的模型 (CE + ImpCon, CE + AugCon + ImpCon) 可以使帖子和含义在特征空间中更紧密地聚集。
表示分析
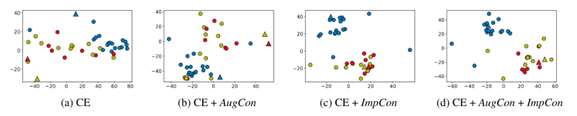
三角形表示implication,圆形表示post
蓝色三角:移民应该被驱逐;红色三角:白人是优越的;黄色三角:非白人是劣等的
实验目的:探究语义相关的帖子和含义是否比不相关的在特征空间中更接近。
使用了对比学习目标 (ImpCon) 的模型 (CE + ImpCon, CE + AugCon + ImpCon) 使不同的含义在特征空间中有明显的区分(蓝色点与红色和黄色点相距较远)
语义相似的含义(及其相应的帖子)在特征空间中更紧密的聚集(红色和黄色的点彼此靠近)
案例分析

错误分析—混淆矩阵
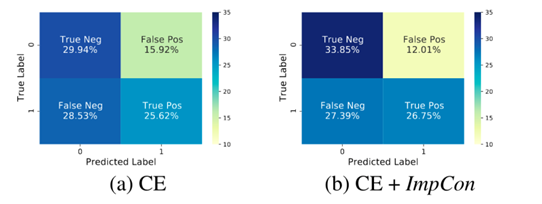
虽然 ImpCon 降低了假正例和假反例的数量,但错误仍较多,假反例比例较高
可能原因:训练集中较少出现的目标群体导致假反例
不同目标群体的仇恨言论基于群体的特征,在训练集中没有出现过的目标群体的仇恨言论会限制模型的泛化能力
9 本文不足

文中所述实验效果的提升在实验结果中并未找到对应提升。
10 代码和数据集地址
https://github.com/ youngwook06/ImpCon