1 为什么要研究虚假评论:
- 虚假评论危害极大
- 虚假评论会影响消费者的消费决策,从而影响商家的经济收益
- 虚假评论普遍存在于电子商务、社交媒体、旅游网站、电影评论网站等领域
2 研究现状:
1、数据集获取困难
- 人工难以准确标注虚假评论,得到真实的标签
- 尽管评论很多,但现有的虚假评论数据集非常的少
2、现有研究方法的局限性(半监督 / GANs)
- 使用半监督方法来进行虚假评论检测的研究十分有限
- 大部分研究都使用预定义的特征集来训练分类器
- 很少有基于GANs的方法用于文本生成
- 大多基于GANs的方法受文本长度限制且需要大量标注数据
3 本文贡献:
核心:提出了一种半监督的基于GAN的虚假评论分类方法——spamGAN
- 第一个探索使用GAN来检测虚假评论的可能性
- spamGAN凭借半监督的方式处理标记和未标记的数据,以此改进了基于GAN的SOTA文本分类模型
- 大多数的研究使用手工选取的特征集来训练分类器,而spamGAN使用从神经网络中学到的特征
- 实验表明,当使用有限的标注数据时,spamGAN在虚假评论分类方面优于现有的SOTA方法
- spamGAN可以生成与训练集非常相似的评论,这可以在GT有限的情况下用于人造数据的生成
4 整体框架:
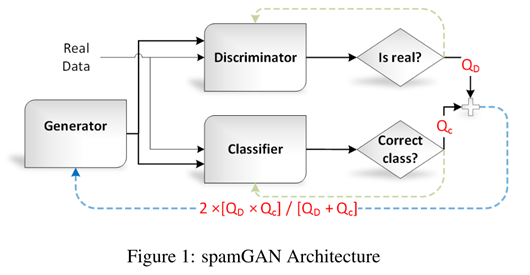
1、生成器
- 本质:一个以门控循环单元为基本组成的单向多层循环神经网络(RNN)
- 功能:生成与训练集高度相似的伪造评论
2、辨别器
- 本质:一个具有稠密输出层的单向循环神经网络(RNN)
- 功能:学会区分真正的评论与伪造的评论
3、分类器
- 本质:一个具有稠密输出层的单向循环神经网络(RNN)
- 功能:学会区分虚假评论与真实评论,即进行虚假评论检测
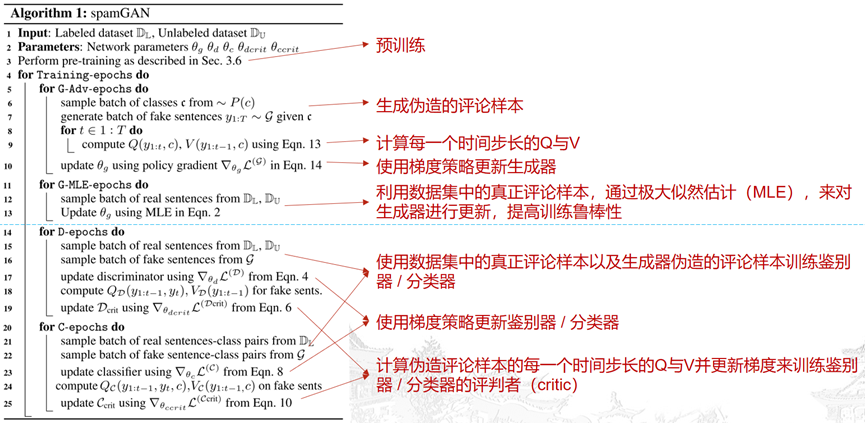
5 算法与解析:
6 数据集:
1、标注数据集
- 共计1596条评论数据的平衡数据集
- 来自Ott论文的TripAdvisor数据集(800条真实评论+800条虚假评论)
2、未标注数据集
- 共计32,297条评论数据
- 来自TripAdvisor平台
7 实验:
1、模型对比
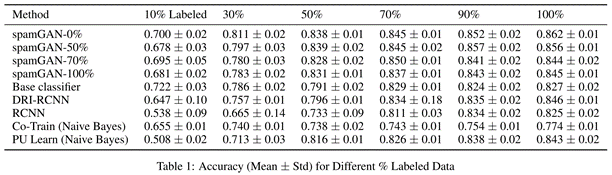
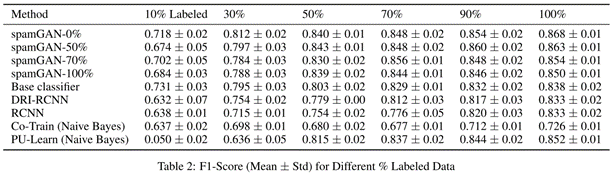
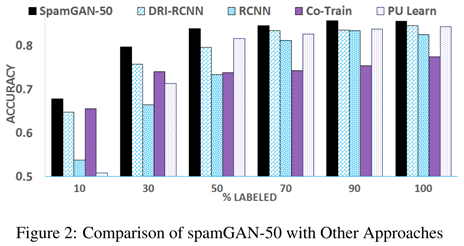
柱状图以spamGAN-50作为spamGAN的代表,主要为了说明在标注数据较少时,本文所提出的spamGAN方法明显优于基线模型
2、标注数据比例的影响
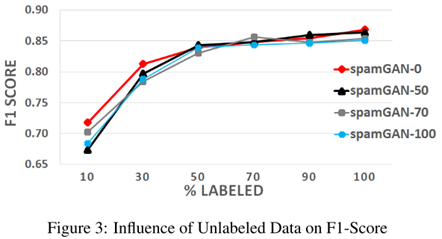
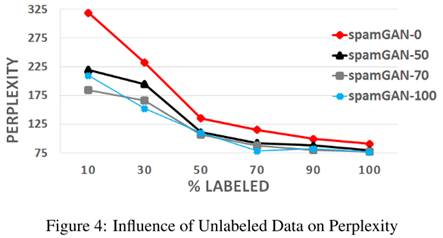
结果说明标注数据占比越高(未标注数据占比越低),spamGAN架构的表现越好
8 个人感想:
1、本文工作的创新
- 领域迁移:将生成对抗网络GANs应用到虚假评论检测领域
- 架构设计:提出了一个基于GANs的半监督学习模型——spamGAN
2、本文工作的不足
- 评论文本长度最大值限定为128,将造成许多评论数据的丢失
- 数据集来自2011年的一篇论文,评论发布时间较早且标注数据较少
- 虚假评论检测不应该仅局限于文本,还应注意其他数据信息(如:评级、照片等)
- 部分贡献未能用具体的实验数据进行证明,是GANs方法所带来的的必然结果
3、本文内容的呈现
- 数学化表达:将本文工作所涉及的几乎所有变量、方法都用规范的数学公式表达出来
- 详细的分析:在页面有限的情况下,对研究方法与实验结果进行了详细的描述与分析