1.论文标题:
FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning
来源:Proceedings of the ACL (2022)
等级:CCF-A
2.论文作者:
Jing Zhou, Yanan Zheng, Jie Tang, Jian Li, Zhilin Yang
3.论文链接:
http://keg.cs.tsinghua.edu.cn/jietang/publications/ACL22-Zhou-et-al-FlipDA.pdf
4.代码链接:
https://github.com/zhouj8553/FlipDA
5.摘要
Most previous methods for text data augmentation are limited to simple tasks and weakbaselines.We explore data augmentation on hard tasks (i.e., few-shot natural language understanding) and strong baselines (i.e., pretrained models with over one billion parameters). Under this setting, we reproduced a large number of previous augmentation methods and found that these methods bring marginal gains at best and sometimes degrade the performance much. To address this challenge, we propose a novel data augmentation method FlipDA that jointly
uses a generative model and a classififier to generate label-flflipped data. Central to the idea of FlipDA is the discovery that generating label-flflipped data is more crucial to the performance than generating label-preserved data. Experiments show that FlipDA achieves a good tradeoff between effectiveness and robustness—it substantially improves many tasks while not negatively affecting the others.
以前用于文本数据增强的大多数方法都局限于简单的任务和弱基线。我们探索了在困难任务(即少镜头的自然语言理解)和强基线(即拥有超过10亿个参数的预训练模型)上的数据增强。在这种情况下,我们重现了大量以前的增广方法,发现这些方法最多只能带来边际收益,有时性能会下降很多。为了应对这一挑战,我们提出了一种新的数据增强方法FlipDA。
使用生成模型和分类器生成标签翻转数据。FlipDA的核心思想是发现生成标签翻转的数据比生成标签保存的数据对性能更关键。实验表明,FlipDA在效率和健壮性之间实现了良好的权衡——它大大改善了许多任务,而不负面影响其他任务。
6.研究背景
数据扩充是一种通过从给定数据生成新数据来扩充训练集的方法。对于文本数据,包括替换、插入、删除和shuffie在内的基本操作已被广泛采用,并集成到一系列扩展框架75、62、65、30和63中。生成性建模方法(如反译)也被用于生成扩充样本13、57。然而,之前的研究有两个主要局限性。首先,一些通用的增广方法基于弱基线,而不使用大规模预训练语言模型。最近的研究表明,当与大型预训练模型结合使用时,一些数据增强方法不太有用41。第二,以前的大多数研究都是在简单的任务上进行的,比如单句分类,这样更容易生成合法的扩充样本。对于更难的任务,如自然语言理解(例如,判断A句是否包含B句),目前尚不清楚以前的方法是否仍然有用。
在这项工作中,我们进一步研究了强基线和硬任务下的数据扩充。我们的研究采用了大规模的预训练语言模型,比如DeBERTa 20,以超过10亿个参数作为基线。此外,我们针对的是一个非常具有挑战性的环境,即自然语言理解(NLU)。我们考虑挑战性的NLU任务,包括问答、文本蕴涵、共指消解和词义消歧。我们采用了SuperGLUE,它包含了当前NLP方法中一些最难理解的语言理解任务。根据56,我们只使用了32个训练示例来构建few-shot环境。
在此背景下,我们复制了大量广泛使用的数据增强方法。我们的实验带来了两个意想不到的发现:(1)以前的大多数增强方法最多只能带来边际收益,对大多数任务都不有效;(2) 在许多情况下,使用数据扩充会导致性能不稳定,甚至进入故障模式failure mode;i、 例如,性能可能会大幅下降或严重恶化,具体取决于使用的预训练模型。上述问题阻碍了这些增强方法在few-shot学习中的实际应用。
我们提出了一种新的FlipDA方法,该方法可以同时实现硬few-shot任务的有效性和鲁棒性。在初步实验中,我们观察到,与保留原始标签的增强数据相比,label-fiipped数据通常在很大程度上改善了预训练模型的泛化。基于这一观察,FlipDA首先使用基于预训练T5 48的单词替换生成数据,并使用分类器选择label-fiipped数据。
实验表明,FlipDA在许多困难任务上显著提高了性能,在平均性能方面大大优于以前的增强基线。此外,FlipDA在不同的预训练模型和不同的任务中都很健壮,避免了故障模式。
7.FlipDA数据增强方法
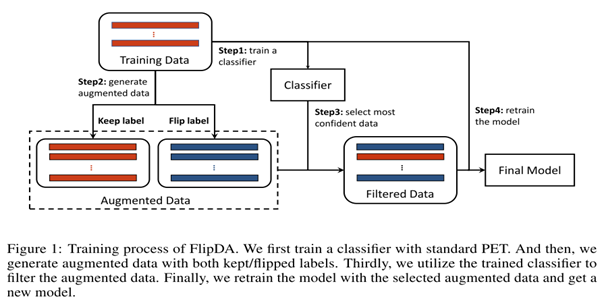
7.1首先使用BERT等训练一个标签分类器。
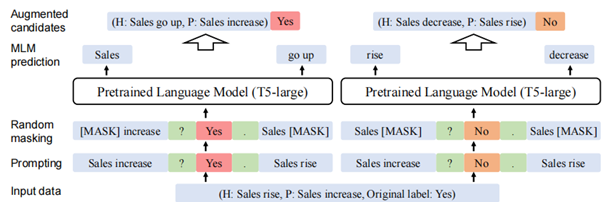
7.2使用T5模型生成新的增强数据:将使用类似于[1]中的 prompt 的方式拼接起来作为 input, 随机 mask 掉一些 input tokens, 使用 T5 模型预测这些 mask 从而生成新的样本(这种方法称为:Pattern-based Data Cloze)。这样,对于每个训练样本 ,可以生成一个新样本集合。
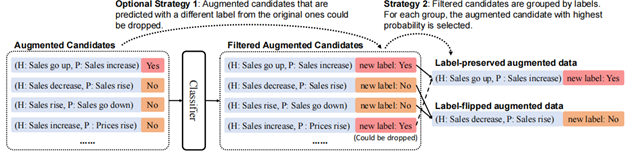
7.3在分类器的帮助下筛选新样本:对于原样本 , 我们有了新样本集, 这个 里面包含了一些标签翻转数据(即:), 我们分类器 把它们挑出来得到。
8.相关实验
实验数据集:
本文作者在SuperGLUE的8个数据集上进行了实验,其中涵盖了共指消歧、因果推断、文本蕴含、词义消歧、问答等较为困难的自然语言理解任务。
1.BoolQ :每条训练数据是一个四元组 (question, title, answer, passage),question 是一个复杂且非事实性的 query,要求基于 passage 给出 YES/NO 的回答。
2.RTE:其中一个文本作为前提(premise),另一个文本作为假设(hypothesis),判断其是否具有蕴含关系。
3.WSC:Winograd 包含一些具有二义性的句子对,当句子里的代词的指的对象发生变化时,问题会得到相反的答案。
4.CB:识别来自《华尔街日报》等文本摘录中包含的假设,并确定该假设是否成立。
5.COPA:给定一个前提,和两个选择,任务是选出和这个前提有因果关系的选择。
6.MultiRC:多句阅读理解(MultiRC)是一个问答任务,每个例子由一个上下文段落、一个关于该段落的问题和一系列可能的答案组成。模型必须预测哪些答案是正确的,哪些是错误的。
7.WiC:WiC为模型提供了两个文本片段和一个多义词(具有多种含义的词),并要求模型确定在两个句子中该词是否具有相同的意思。
8.ReCoRD:由CNN/每日邮报新闻文章自动生成的查询组成;每个查询的答案都是相应新闻的摘要段落的文本跨度。
预训练模型:
实验使用了两个大规模预训练模型:DeBERTa-v2-xxlarge和ALBERT-xxlarge-v2,基于这两个大规模预训练模型进行小样本学习的任务。
预测器:T5-Model(Text-To-Text Transfer Transformer)是前人提出的一个用于处理自然语言理解任务的Transformer预训练模型。
实验基线:
1.简单数据增强、2.回译、3.同义词替换、4.KNN 替换
5.TinyBERT : 使用 BERT 预测出的 token 或者 GloVe 导出的词汇进行替换
6.T5-MLM : 和本文方法大体相同,但是该方法是标签保留的数据增强,而且没有后面的筛选步骤
7.MixUP : 在特征空间进行增强,在特征空间中对两个样本之间线性插值
训练框架:
实验使用PET/iPET(pattern-exploiting training)训练流程。PET/iPET是前人提出的一个半监督学习的训练流程,将输入样本按不同的模式重新构造为封闭式短语,以帮助语言模型理解给定的任务。为了减轻模式不同和随机种子值对实验结果的影响,我们在多个模式和3次迭代中运行每个实验,最后取平均性能。
评估指标:
鲁棒性:MaxDrop(MD),该模型在多个任务上与基线相比的最大性能下降。该值越小,说明模型鲁棒性越大。
有效性:accuracy,f1, em (exact-match):评价预测中匹配到正确答案(真实标签)的百分比。
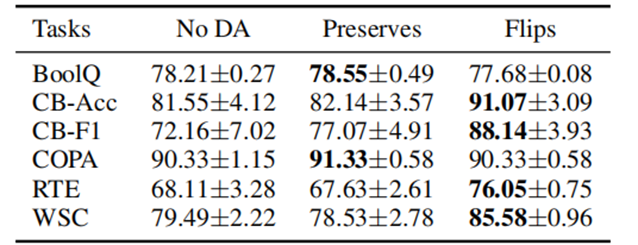
8.1实验一
8.2实验二
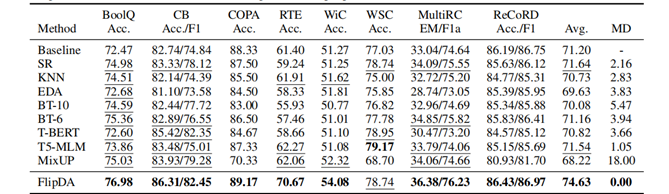
Baseline:表示没有数据增强的原始PET,基于PET和albert-xxlarge-v2的基线方法。
实验结果表明,FlipDA 方法无论在有效性上还是鲁棒性上都有 SOTA 的性能,说明FlipDA通过增加高质量的数据,可以有效地提高小样本学习任务的性能。
8.3实验三
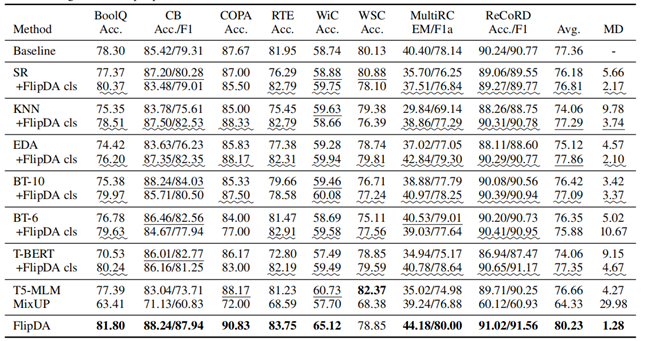
FlipDA cls表示采用与FlipDA中相同的分类器,用于过滤候选增强数据。
实验说明基于模式的数据凝聚在所有任务上都是有效的,因为它可以有效减少语法错误,更加兼容标签翻转方式,并且分类器选择在大多数任务上是有效的。
8.4实验四

实验说明标签翻转+标签保留相比于只使用标签保留的数据增强具有更好的效果。
8.5实验五
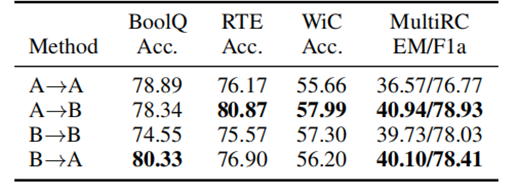
实验说明只有同时具有多个方向的标签翻转增强数据,才更有可能超越 baseline 的性能。
8.6实验六
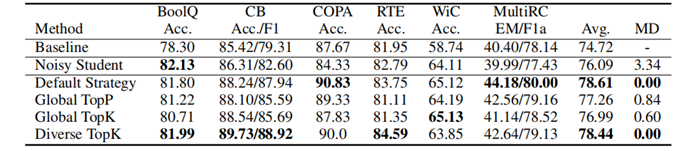
实验说明,默认策略或者 Diverse TopK 更好一些。
9.结果与分析
WSC任务的局限性如上所述,label-fiipped增强对于few-shot学习性能具有令人鼓舞的优势,但它也有局限性。虽然FlipDA在大多数任务上的性能明显优于现有的基线增强方法,但我们也注意到它对WSC任务的影响略低于一些基线。这是因为,对于消除多标记词义歧义的WSC任务,T5很难生成其label-fiipped case。T5模型不擅长构建不在原始句子中的类似实体,因此无法生成所需的候选示例。我们将基于模式的完形填空算法留给未来的工作。我们预计以实体为中心的预训练模型可能会缓解这个问题。
直到现在,怎样评估few-shot学习的性能仍然是一个开放的问题。目前,主要有两种主流的few-shot setting。第一种是使用一组根据实际考虑确定的预先固定的超参数。第二种类型是构造一个小的开发集dev(例如,32个示例开发集)。然后,它执行网格搜索grid search,并使用小型开发集进行超参数模型选择。我们的工作使用前一种setting。我们分别使用这两种setting进行了初步实验,发现第一种setting相对更稳定。我们相信,如何评估few-shot学习系统也是未来工作的重要研究方向。
few-shot学习系统因为缺乏样本而容易过度拟合。FlipDA的核心思想是对标签差异的原因提供中间监督,以提高通用性。从这个意义上说,FlipDA和对比学习19,4之间存在联系,对比学习19,4使用数据扩充来生成正面实例,并使用数据集中存在的样本作为负面样本。FlipDA表明,增强样本也可以扮演负样本的角色。虽然之前关于对比学习的研究侧重于使用大数据进行训练,但我们的实验侧重于表明,增加一个小数据集能够改善few-shot的泛化。看看这种联系是否会在对比预训练和few-shot学习两个领域都取得进展,可能会很有趣;例如,为大规模对比预训练生负样本。
10.相关思考
(1)提出了一种新的针对小样本学习的数据增强方法FlipDA。
(2)该方法实现了数据增强任务的有效性和鲁棒性的平衡。
(3)本文的工作量丰富,且实验充分。
(4)作者没有从理论上清楚解释在现有数据点附近生成标签翻转数据能够提高泛化性。
(5)对于需要预测多个tokens的任务而言,生成标签翻转数据会更加困难一些,且不一定有效果。 (6)本文还可以结合更多的数据增强方法。