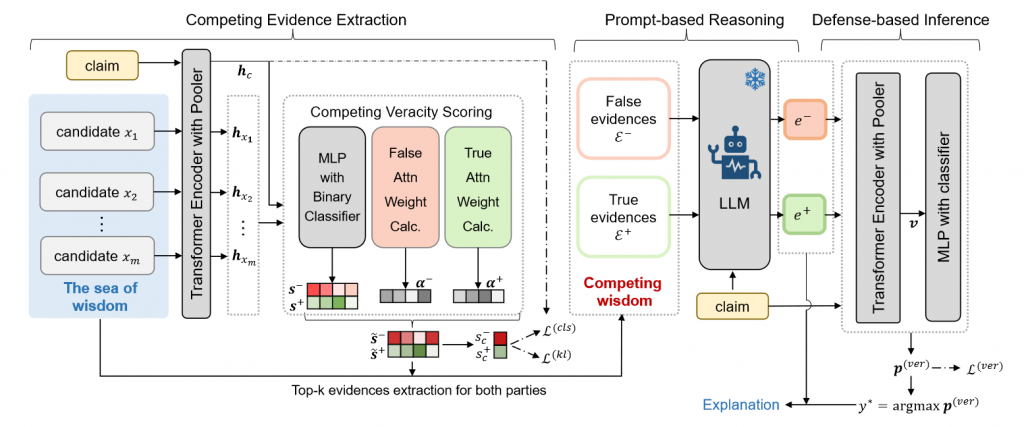
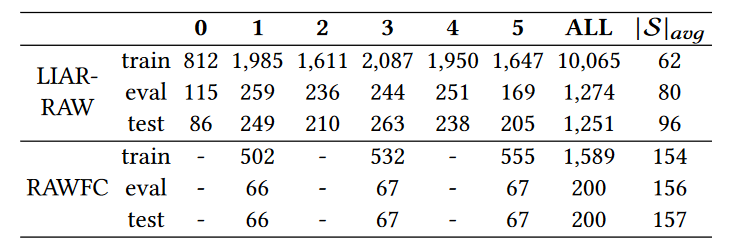
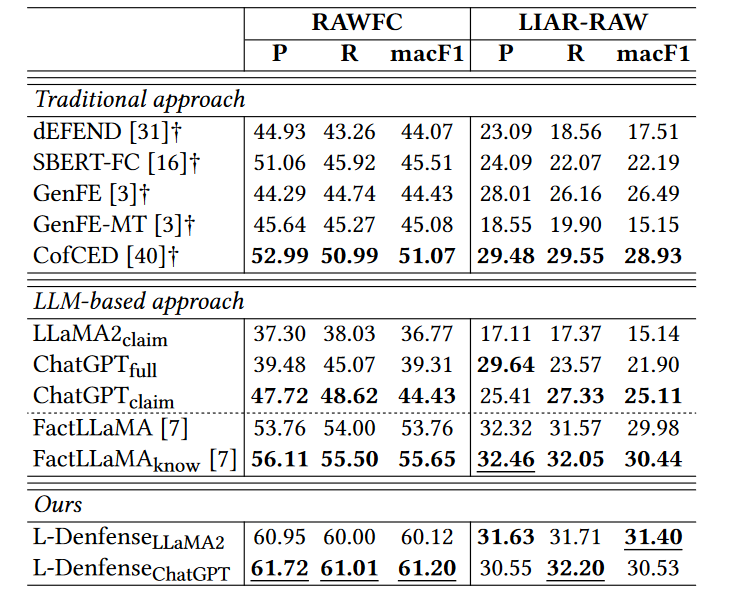
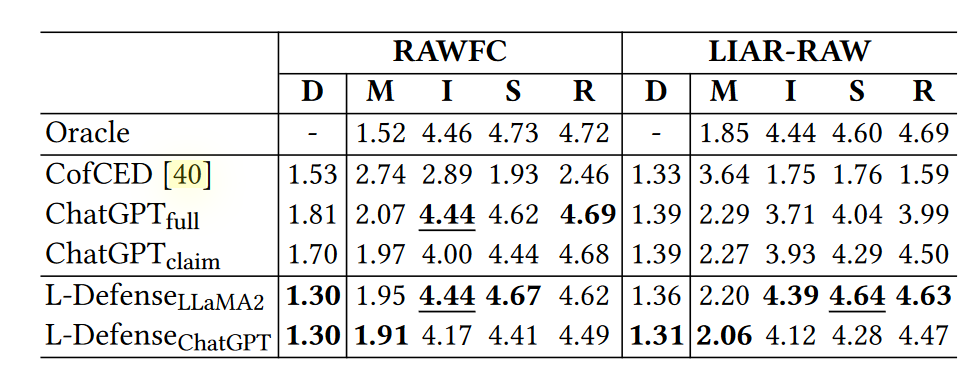
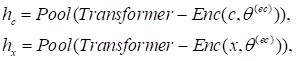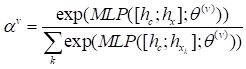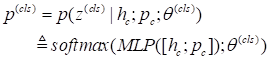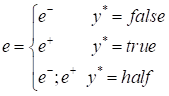(1)传统方法的表现:
大多数传统方法的表现不如ChatGPTclaim,这表明大语言模型(LLMs)在假新闻检测中具有潜力。
(2)三种未调优的LLM方法:
在前三种未经过任何调优的LLM方法中,ChatGPTclaim取得了最好的结果。LLaMA2claim的表现较差,可能是因为其模型规模显著小于ChatGPT。ChatGPTfull表现不佳的一个可能原因是LLM容易受到大量输入报告的偏见影响。
(3)与传统方法中的最佳方法对比:
尽管ChatGPTclaim表现良好,但与传统方法中的最佳方法CofCED相比仍显不足。相比之下,经过微调的LLM模型(即FactLLaMA和FactLLaMAknow)在作者提出的模型之外,表现最好。这表明仅仅利用LLMs进行推理效果有限,而仔细考虑如何进一步利用LLMs可以带来更好的性能。
(4)作者提出的模型的表现:
作者的模型在一个新的防御框架中利用LLM作为推理器,在真假性预测上取得了出色的结果,特别是在RAWFC数据集上的提升尤为显著。与FactLLaMAknow相比,作者的模型在所有指标上至少提高了4%。
8.3.2 文本质量评估
(实验一)
在没有参考文本的情况下,ChatGPT 也能从以下几个角度评估文本质量:
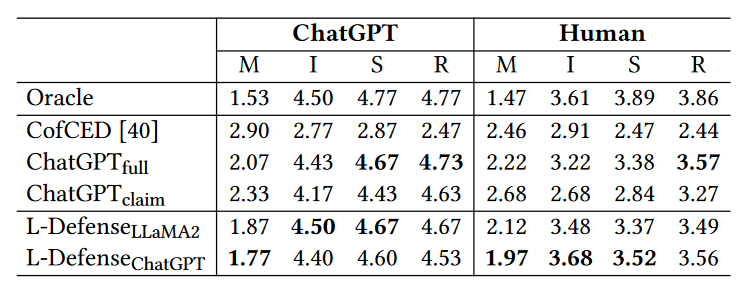
误导性(Misleadingness, M):评估模型解释与真实声明标签的一致性(越小越好)
信息性(Informativeness, I):评估解释是否提供新信息,如背景和附加上下文(越大越好)
合理性(Soundness, S):描述解释是否有效且合乎逻辑(越大越好)
可读性(Readability, R):评估解释是否遵循正确的语法和结构规则,句子是否连贯易读(越大越好)
差异度(Discrepancy,D):不考虑解释质量,通过计算预测标签和实际标签分数的绝对差值来获得(越小越好)
效果如下所示,其中,Oracle 通过向 ChatGPT 提供声明和实际准确性标签,生成声明为何被分类为其实际准确性标签的解释,可当做是一种性能的最高标准。