原文作者
Authors: Rui Xia, Zixiang Ding
Institution: Nanjing University of Science and Technology
Research direction: natural language processing and text mining: text classification; sentiment analysis and opinion mining, etc.
2 论文来源
Conference/Journal: ACL 2019
3 论文地址
https://arxiv.org/abs/1906.01267
4 论文简介
4.1 研究背景
情感分析一直是NLP研究的热门方向,最初情感分析相关研究大多集中在情感分类和情感要素抽取的任务上,相关的技术也较为成熟。 后来提出了新任务Emotion Cause Extraction(ECE),即对情感文本的情感原因进行抽取。通常是给定文本,并对文本进行一定的标注,然后找到文本情感对应的cause子句。研究备受关注且应用也十分广泛。
4.2 研究内容
本文提出了新任务Emotion-Cause Pair Extraction(ECPE)——直接提取文档中所有潜在的情感–原因对。
4.3 研究结论
本文提出两步策略来解决问题,首先通过多任务学习进行单独的情感提取和原因提取,然后进行情感–原因配对和过滤。最终解决了所提出的ECEP任务,并且经过验证本文的模型在情感–原因对提取中获得了61.28%的F1分。实验结果证明了ECPE任务的可行性和所提方法的有效性。
5 解决问题
解决了ECE任务的两个明显的缺点:
(1)在原因提取前必须对情感进行标注,这极大地限制了它在现实场景中的应用;
(2)先对情感进行标注,再提取原因,忽略了情感和原因是相互指示的。
6 本文贡献
(1)本文提出了一个新的任务:情感-原因对提取。它解决了传统ECE任务在提取原因前需要对情感进行标注的缺点
(2)本文提出了一个两步框架来处理ECPE任务,首先进行单独的情感提取和原因提取,然后进行情感-原因配对和过滤
(3)在一个ECE基准语料库的基础上,构建了适合ECPE任务的语料库。实验结果证明了ECPE任务的可行性和所提出方法的有效性。
7 论文方法
本文提出了一个两步框架:
Step 1:通过两种多任务学习模型,将情感-原因对提取任务转化为两个独立的子任务(分别是情感提取和原因提取),目标是提取一组情感子句和一组原因子句
Step 2:进行情感原因配对和过滤。我们将这两个集合的所有元素合并成对,最后训练一个过滤器来消除不包含因果关系的情感-原因对。
接下来做详细说明
Step 1. Individual Emotion and Cause Extraction
首先,我们将情感-原因对提取任务转换为两个独立的子任务(分别是情感提取和原因提取)。本文提出了两种多任务学习网络,在统一的框架下对两个子任务进行建模,目标是为每个文档提取一组情感子句E = {ce1,···,cem}和一组原因子句C = {cc1,···,ccn}。
这一步的目标是分别为每个文档提取一组emotion子句和一组cause子句。为此,我们提出了两种多任务学习网络,即:独立多任务学习Independent Multi-task Learning和交互多任务学习Interactive Multi-task Learning)。后者是一种强化版本,在前者的基础上进一步捕捉情感与原因之间的关联。
Independent Multi-task Learnin
在我们的任务中,一个文档包含多个子句:d = [c1, c2,…cd],每个ci也包含多个词ci = [wi,1, wi,2,…wi, ci]。为了捕捉这种“word-clausl-document”结构,我们使用了一个分层的Bi-LSTM网络,它包含两层,如图所示
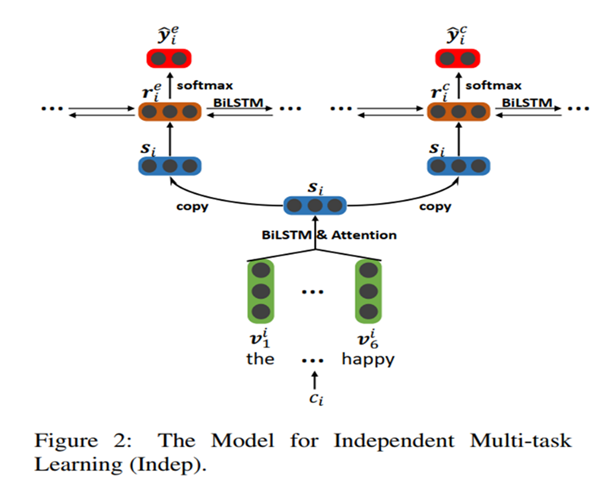
下层由一组word-level组成Bi-LSTM模块,每个模块对应一个子句,并累积子句每个单词的上下文信息。基于双向LSTM方法,得到第i子句中第j个字的隐藏状态hi,j。然后采用注意机制得到子句表征si。
上层由两部分组成:情感提取和原因提取。每个组件都是一个子句级BiLSTM,它接收独立子句在下层得到的表示[s1, s2,…, s|d|]作为输入。两组分Bi-LSTM、rei和rci的隐态,可以看作子句ci的上下文感知表示,最后传入softmax层进行情绪预测和原因预测:
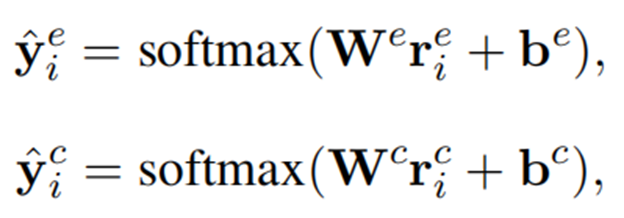
损失函数公式:
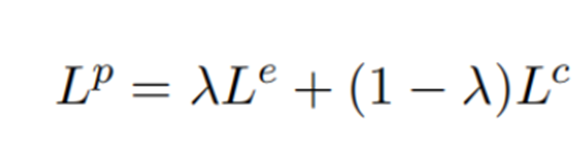
其中:上标e和c分别表示情感和原因,Le和Lc分别为情感预测和原因预测的交叉熵误差,λ为折衷参数。
Interactive Multi-task Learning
到目前为止,上层的两个组分Bi-LSTM是相互独立的。然而,正如我们前面提到的,情感提取和原因提取这两个子任务并不是相互独立的。一方面,提供情感可以帮助更好地发现原因;另一方面,知道原因也有助于更准确地提取情感。
在此基础上,我们进一步提出一个互动的多任务学习网络,以捕捉情感与原因之间的关联。结构如图3所示。需要注意的是,用情感提取来改进原因提取的方法被称为Inter-EC。此外,我们还可以使用原因提取来加强情感提取,我们称之为Inter-CE方法。如图所示:
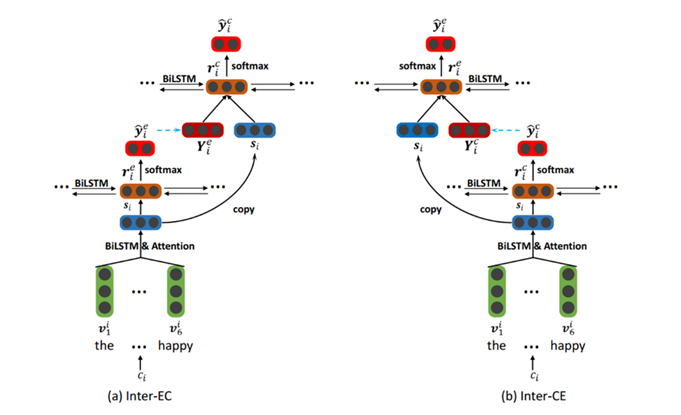
与独立的多任务学习相比,Inter-EC的下层保持不变,上层由两部分组成,分别以交互的方式对情感提取任务和原因提取任务进行预测。每个组件都是一个clause级的BiLSTM,后面跟着一个softmax层。
第一个组件采用从下层获得的独立子句表示[s1, s2,…], s|d|],作为情感提取的输入。clause级 Bi-LSTM的隐藏状态rie用作特征来预测第i个子句的分布。然后我们嵌入第i子句的预测标签作为向量Yie,用于下一个组件。
另一个组件取(s1⊕Ye1, s2⊕Ye2,……(s|d|⊕Y|ed|)作为原因提取的输入,其中⊕表示拼接操作。clause级 Bi-LSTM的隐藏状态rci用作特征来预测第i个子句的分布。
模型的损失函数同上个模型一样。
Step 2. Emotion-Cause Pairing and Filtering
把情感集E和原因集C结合起来,用笛卡尔积把它们结合起来。这就产生了一组候选情感-原因对。我们最后训练一个过滤器来排除情感和原因之间不包含因果关系的对。
在步骤1中,我们最终获得了一组情感子句E = {ce1,···,cem}和一组原因子句C = {cc1,···,ccn}。
第二步的目标是将这两组句子配对,并构建一组具有因果关系的情感-原因对集合:
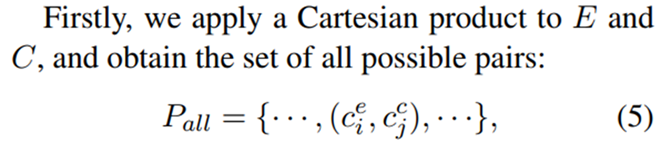
然后用一个由三种特征组成的特征向量来表示Pall中的每一对:
se和sc分别为情感子句和原因子句的表示,vd为两句之间的距离:

然后训练逻辑回归模型来检测每个候选对(cei, ccj)是否有因果关系,从Pall中消除没有因果关系的,得到最终的情感-原因对集合:

8 实验结果
实验数据集:
2016年,Lin Gui等人发表论文:
Emotion cause extraction, a challenging task with corpus construction.
情感原因提取是一项需要语料库建设的挑战性任务
并构建了新的适用于ECE的语料库,此后作为ECE的基准语料库使用。
因为ECPE是作者提出的新任务,无法直接使用ECE的语料库,所以作者自己基于上述语料库构建了适合ECPE的语料库。
为了更好的满足ECPE任务设置,作者将具有相同文本内容的文档合并为一个文档,
并在该文档中对每种情感-原因对进行标记。在合并的数据集中,不同数量的
情感-原因对的文档所占比例如下表所示:

随机选择90%的数据用于训练,剩下的10%用于测试。为了获得统计上可信的结果,我们重复实验20次,并报告平均结果。我们使用precision、recall和F1得分作为评价指标,计算方法如下:
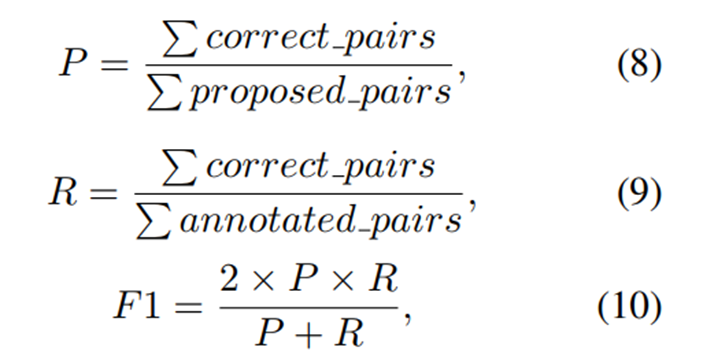
实验准备:
①使用 word2vec在中文微博语料库上预先训练好的词向量(Mikolov等人,2013)工具包。
②单词嵌入的维数设置为 200。
③所有的模型在 BiLSTM中隐藏单元的数量设置为 100。
④所有的权矩阵和偏差是随机初始化的均匀分布 U((0.01, 0.01)。
⑤使用了 SGD算法和混合小批量 Adam更新规则。
⑥批量大小和学习率分别设置为 32和 0.005。
⑦正则化方面,单词嵌入采用dropout, dropout率设置为 0.8。
⑧对 Softmax参数进行L2约束,L2-范数正则化设为 1e-5。
实验一:评估 ECPE 任务:
Overall Performance:
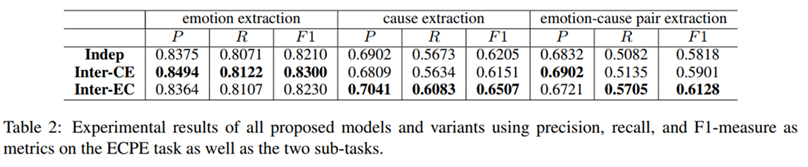
Indep表示情感提取和原因提取分别由两个Bi-LSTMs建模
Inter-CE表示使用原因提取的预测来改进情感提取
Inter-EC表示使用情感提取的预测来增强原因提取
与Indep相比,Inter-EC在ECPE任务和两个子任务上都有了很大的改进。具体而言,我们发现改进主要体现在原因提取任务的查全率上,最终使 ECPE的查全率有了较大的提高。这说明情绪提取的预测有助于原因提取,证明了Inter-EC的有效性。此外,情感提取的效果也有所提高,说明原因提取的监督也有利于情感提取。
与Indep相比,Inter-CE在ECPE任务上也得到了显著改善。具体而言,我们发现改进主要体现在情感提取任务的查准率上,最终导致ECPE的查准率显著提高。这表明,原因预测提取有利于情感提取,证明了Inter-CE的有效性。
结论:(1)情感提取和原因分析相互影响,互相促进
(2) EC对原因提取的改善远远大于CE,猜测是因为原因提取难度高,改善空间大。
Upper-Bound of Emotion and Cause Interaction:

Inter-CE-Bound是Inter-CE的一个变体,它使用原因提取标签来帮助情感提取
Inter-EC-Bound是Inter-EC的变体,它使用情感提取的标签来帮助原因提取
Inter-CE-Bound和Inter-EC-Bound的结果前面都有一个“#”,这表明它们不能与其他方法进行公平的比较,因为它们使用标注。与Indep相比,Inter-EC-Bound在原因提取上的性能和Inter-CE-Bound在情感提取上的性能都有了很大的提高。此外,Inter-EC-Bound对原因提取任务的改善要远远大于Inter-CE-Bound对情绪提取任务的改善。我们猜测这是因为原因提取任务比情感提取任务更难,有更大的改进空间,这与前文一致。
通过比较Inter-EC-Bound和Inter-EC的结果,我们发现Inter-EC的表现虽然好于Indep,但远不如Inter-EC-Bound,这是由于情感提取预测中存在大量错误而导致的。在比较Inter-CE-Bound和Inter-CE时,我们可以得出相同的结论。
这些实验结果进一步说明了情感和原因是相互指示的,说明如果我们能提高情感提取任务的性能,就能在原因提取任务上获得更好的性能,反之亦然,最终导致ECPE的提高。但需要注意的是,这只是一个上界实验,情感/原因的实际情况是用来互相预测的。
结论:(1)进一步说明了情感和原因是相互指示的
(2)说明如果我们能提高情感提取任务的性能,就能在原因提取任务上获得更好的性能
Effect of Emotion-Cause Pair Filtering:
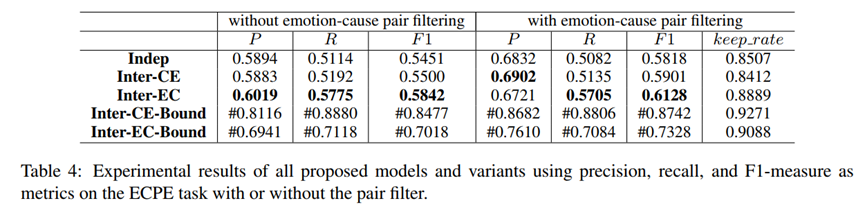
该实验报告了有/无对过滤的情感 –原因对提取性能。有/无对过滤表示我们在第二步应用笛卡尔积后是否采用对过滤,keep_rate表示Pall中情感–原因对在对过滤后最终被保留的比例。
一个明显的观察结果是,采用对偶滤波器后,所有模型在ECPE任务上的F1得分都有显著提高。这些结果证明了配对过滤器的有效性。具体来说,通过引入对滤波器,Pall中的一些候选情绪–原因对被过滤掉了,这可能会导致召回率的降低和精度的提高。根据表4,几乎所有模型的精度得分都有很大提高(超过7%)。相比之下,召回率下降的幅度很小(小于 比1%),从而使F1得分得到显著提高。
结论:证明了引入过滤器的有效性。
评估 ECE任务:
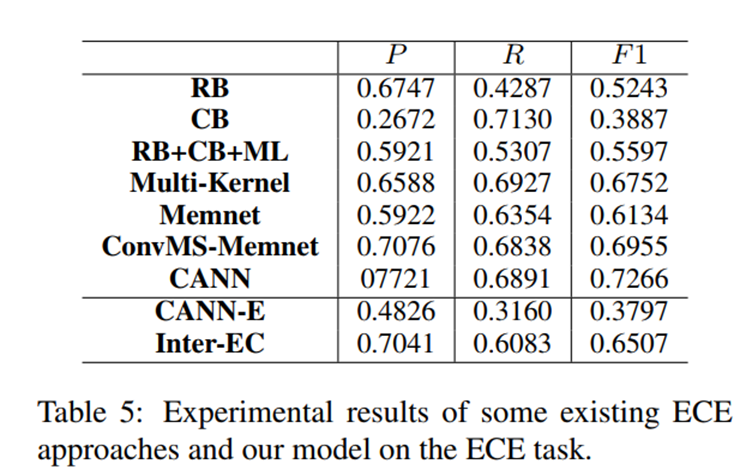

通过与传统ECE任务上的一些现有方法进行比较,进一步检验我们的方法。需要注意的是,我们的Inter-EC模型并没有使用测试数据上的情感标注
可以看出,虽然本文方法没有在测试数据上使用情感标注,但在ECE任务中,它仍然取得了与大多数传统方法相当的结果。这说明本文的方法可以克服传统ECE任务中情感标注必须在测试阶段给出的局限性,但不会降低原因提取性能。
为了在相同的实验环境下与传统的ECE任务方法进行比较,我们进一步实现了CANN的简化(CANN-E),它去掉了测试数据中情感标注的依赖性,很明显,通过去掉情感标注,CANN的F1得分大幅下降(约34.69%)。相比之下,我们的方法不需要情感注释,在F1测量中实现了65.07%,明显优于CANN-E模型27.1%。
结论:在ECE任务中,作者的模型仍取得了与大多数传统方法相当的结果。相比之下,在没有情感标注的情况下,作者的模型取得了远好于传统模型的表现
9 本文不足
存在的问题:
(1)本文的研究思路是分为两步的策略,目标不够直接
(2)本文所提出的模型Inter-CE和Inter-EC相互之间还是独立的,只有单方面的影响关系
(3)第一步预测所产生的错误会影响第二步的结果,有一定的局限性。
(4)模型整体的准确率、召回率和F1得分不算高,上界实验不能代表实际应用的效果,并且在原因分析提取的效果显然不理想。
我的思考:
(1)是否可以构建一个模型来直接解决问题,实现端到端地提取情绪-原因对。
(2)是否可以同时结合Inter-CE和Inter-EC的预测结果进行后续计算
(3)使用BERT或者更新的语言模型代替文中的BiLSTM和Word2vec算法,提高模型的效率和准确率。
(4)新的ECEP任务可以应用到我们的实际任务中:社交网络……
(5)本篇论文提出新任务的思想是将具有相关性但独立处理的任务相结合并同时处理,利用其交互关系,是否可以应用到其他的领域。
10 代码和数据集地址