阅读笔记作者:yf
1 原文作者
Ruifan Li(School of Artificial Intelligence, Beijing University of Posts and Telecommunications, China)
Hao Chen(School of Artificial Intelligence, Beijing University of Posts and Telecommunications, China)
Fangxiang Feng(School of Artificial Intelligence, Beijing University of Posts and Telecommunications, China)
Zhanyu Ma(School of Artificial Intelligence, Beijing University of Posts and Telecommunications, China)
Xiaojie Wang(School of Artificial Intelligence, Beijing University of Posts and Telecommunications, China)
Eduard Hovy(Language Technologies Institute, Carnegie Mellon University, USA)
2 论文来源
ACL(2021)
3 论文地址
https://aclanthology.org/2021.acl-long.494.pdf
4 论文简介
基于方面的情感分析是一项细化的情感分类任务。最近,人们探索了依存树上的图神经网络,以明确地模拟方面和意见词之间的联系。然而,由于依赖关系解析结果的不准确性以及在线评论的非正式表达和复杂性,改进是有限的。为了克服这些挑战,在该文中,作者提出了一个双图卷积网络(DualGCN)模型,同时考虑了语法结构和语义关联的互补性。特别是,为了减轻依赖性解析错误,作者设计了一个具有丰富句法知识的SynGCN模块。为了捕捉语义上的关联,作者还设计了一个具有自我注意力机制的SemGCN模块。此外,该文还提出了正交和差分正则器,通过约束SemGCN模块中的注意力分数来精确捕捉词与词之间的语义关联。正交正则器鼓励SemGCN学习语义相关的词,减少每个词的重叠。差分正则器鼓励SemGCN学习SynGCN无法捕捉的语义特征。在三个公共数据集上的实验结果表明,DualGCN模型优于最先进的方法,并验证了该模型的有效性。
5 解决问题
情感分析已经成为自然语言处理中的一个热门话题。基于方面的情感分析(ABSA)是一项面向实体层面的细粒度情感分析任务,旨在确定句子中特定方面的情感极性。
最近的研究致力于依存树的图卷积网络和图注意力网络。然而,在将依存树相关知识应用于ABSA任务时,出现了两个挑战:1)依存语法解析结果的不准确性;2)由于在线评论的非正式表达和复杂性,依存树上的GCN在对句法依存性不敏感的数据集上并没有达到预期的效果。
6 本文贡献
- 为ABSA任务提出了一个DualGCN模型。该模型同时考虑了一个给定句子中的句法结构和语义关联性。具体来说,DualGCN通过一个Mutual BiAffine模块将SynGCN和SemGCN网络联系在一起。
- 提出了正交和差分正则器。正交正则器鼓励SemGCN网络学习一个正交的语义关注矩阵,而差分正则器则鼓励SemGCN网络学习与SynGCN网络建立的语法特征不同的语义特征。
- 在SemEval 2014和Twitter数据集上进行了广泛的实验。实验结果证明了DualGCN模型的有效性。此外,工作中使用的源代码和预处理的数据集在GitHub上提供。
7 论文方法
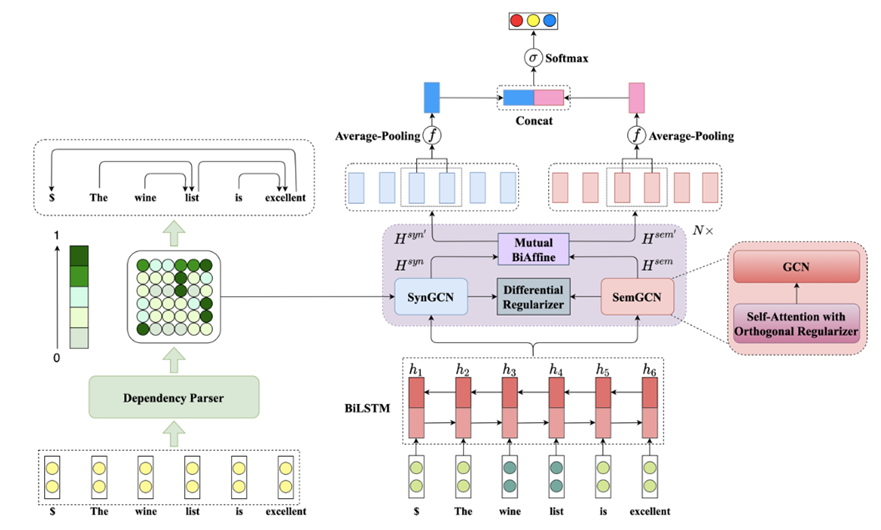
上图为DualGCN的整体架构,主要由SynGCN和SemGCN组成。SynGCN使用依存分析器产生的概率矩阵,而SemGCN利用自我注意力层产生的注意分数矩阵。正交和差分正则器是为了进一步提高捕捉语义关联的能力。这些组件的细节将在下文中描述。
在ABSA任务中,给出了一个句子-方面对(s,a),其中a={a1,a2,…,am}是一个方面。它也是整个句子s={w1, w2, …, wn}的一个子序列。然后,本文利用BiLSTM或BERT作为句子编码器,分别提取隐藏的文本表示。对于BiLSTM编码器,首先从embedding查询表E∈R|V |×de中获得句子s的词嵌入x = {x1, x2, …, xn},其中|V |是词汇表的大小,de表示词嵌入的尺寸。接下来,句子的词嵌入被送入BiLSTM以产生隐藏状态向量H = {h1, h2, …, hn},其中hi∈R2d是BiLSTM在时间t上的隐藏状态向量。隐藏状态向量d的维度由单向LSTM输出。
对于BERT编码器,我们构建一个句子-方面对”[CLS]句子[SEP]方面[SEP]”作为输入,以获得句子的方面感知的隐藏代表。此外,为了使BERT的基于词件的表示与基于词的句法依赖性的结果相匹配,我们将一个词的依赖性扩展为其所有的子词。然后,句子的隐藏表征被分别输入到SynGCN和SemGCN模块中。然后,采用BiAffine模块来实现有效的信息流。最后,将来自SynGCN和SemGCN模块的所有方面节点的表征通过汇集和串联的方式汇总起来,形成最终的方面表征。
1.SynGCN
SynGCN这主要是对给定句子的句法结构进行一个分析。在这里,作者使用了最先进的依赖性分析模型LAL-Parser。作者利用该依赖性分析器获得依赖概率矩阵。作者认为,与依赖性分析器的最终离散输出相比,依赖性概率矩阵可以通过提供所有潜在的句法结构来捕获丰富的结构信息。因此,依赖性概率矩阵被用来缓解依赖性分析的错误。
SynGCN模块将BiLSTM的隐藏状态向量H作为句法图中的初始节点表示,将其输入到一个Dependency Parser(依赖分析器),以依赖概率矩阵的形式作为输出。句法图表示Hsyn ={h1syn, h2syn , …, hnsyn }使用公式(1)从Syn-GCN模块得到。这里,hisyn∈Rd是第i个节点的隐藏表示。请注意,对于方面节点,我们使用符号{ha1syn , ha2syn , …, hamsyn }来表示它们的隐藏表征。
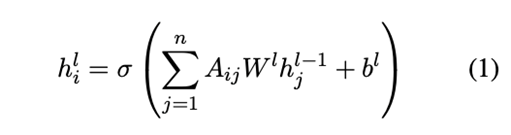
2.SemGCN
SemGCN没有像SynGCN那样利用额外的句法知识,而是通过自我注意力机制获得一个关注矩阵作为邻接矩阵。一方面,自我关注可以捕捉到句子中每个词的语义相关术语,这比协同战术结构更加灵活。另一方面,SemGCN可以适应对句法信息不敏感的在线评论。
自注意力:在该文模型中,作者使用自注意力层来计算注意分数矩阵Asem∈Rn×n。然后,将注意力得分矩阵Asem作为SemGCN模块的邻接矩阵,该过程为:
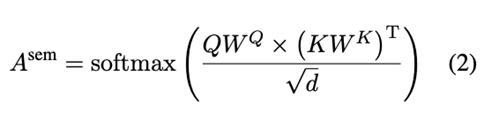
其中Q和K都等于SemGCN模块前一层的图表示,而WQ和WK是可学习的权重矩阵。此外,d是输入节点特征的维度。该文只使用一个自我注意头来获得一个句子的注意分数矩阵。与SynGCN模块类似,SemGCN模块获得图表示Hsem。使用符号 {ha1sem, ha2sem, …, hamsem}来表示所有方面节点的隐藏表示。
BiAffine 模块:
为了在SynGCN和SemGCN模块之间有效地交换相关特征,作者采用了相互的BiAffine变换作为桥梁。这个过程表述如下:
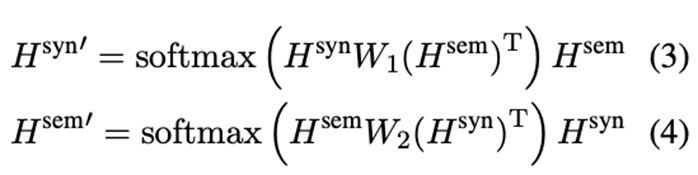
最后,在SynGCN和SemGCN模块的方面节点上应用平均池化和连接操作。和SemGCN模块的方面节点进行平均集合和连接操作。因此,我们得到ABSA任务的最终特征表示:
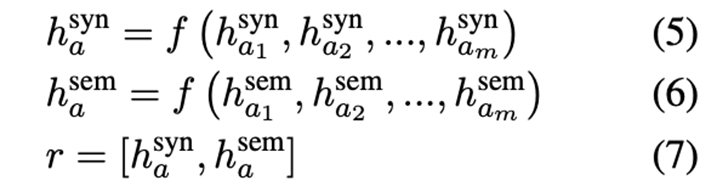
其中f (·)是一个应用于方面节点表征的平均集合函数。然后,得到的表征r被送入一个线性层,接着是一个softmax函数,产生一个情感概率分布,其中Wp和bp是可学习的权重和偏差:
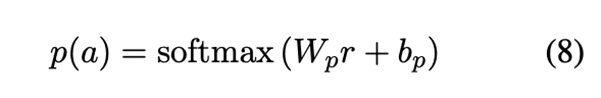
3.正则化
为了改善语义表示,为SemGCN模块提出了两个正则器,即正交和差分正则器。
正交正则器:直观地说,每个词的相关项目应该在一个句子中的不同区域,所以注意力得分分布很少重叠。因此,该文希望正则器能够鼓励所有词的注意力得分向量之间的正交性。给定一个注意分数矩阵Asem∈Rn×n,正交正则器的表述如下:
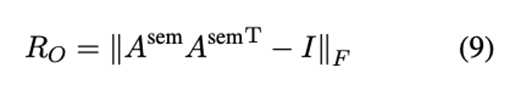
差分正则器:期望从SynGCN和SemGCN模块中学习到的两类特征表征代表了包含在句法依赖树和语义相关中的不同形成。因此,在SynGCN和SemGCN模块的两个邻接矩阵之间采用了一个不同的正则器:
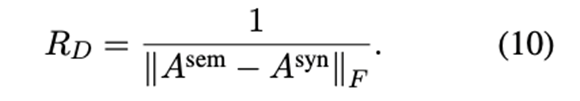
- 损失函数
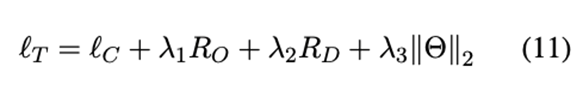
其中λ1、λ2和λ3是正则化系数,Θ代表所有可训练的模型参数。 lC是一个标准的交叉熵损失,对于ABSA任务定义如下:
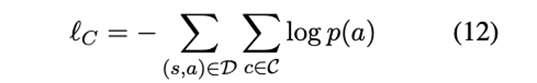
其中D包含所有的句子-方面对,C是不同的情感极性的集合
8 实验结果
数据集:
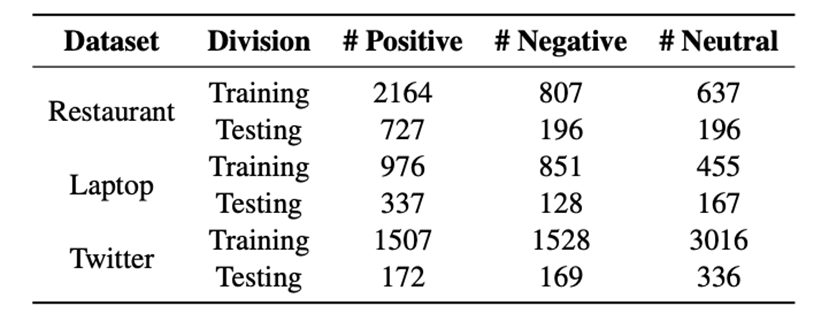
这三个数据集都有三个情感极性:正面、负面和中性。这些数据集中的每个句子都标记了方面和它们对应的情感。
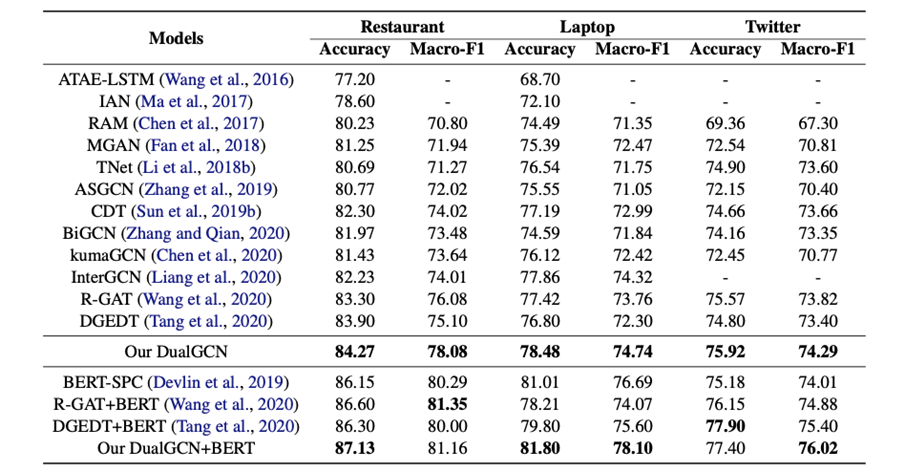
对比实验结果:
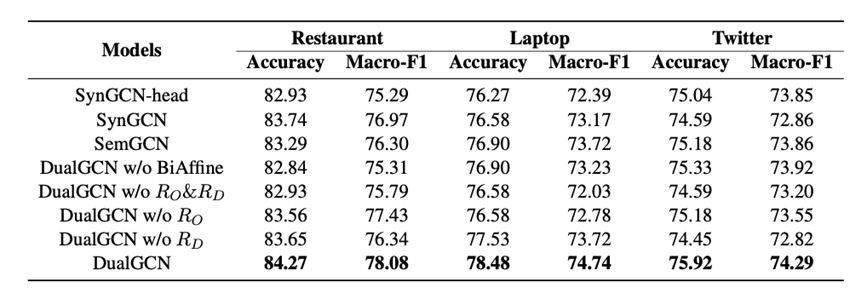
消融实验结果:
9 本文不足
1.该文章实验丰富,选取了15个模型作为对照实验;但本体模型并没有较大的创新。
2.文章所解决的问题聚焦于使用了依赖树的相关研究所产生的问题。
10 代码和数据集地址