阅读笔记作者:解思雨
1 原文作者
Youngjin Jin(KAIST), Seungwon Shin(KAIST), Eugene Jang(S2W Inc.), Jian Cui(S2W Inc.), Jin-Woo Chung(S2W Inc.), Yongjae Lee(S2W Inc.)
2 论文来源
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(ACL 2023), CCF A
3 论文地址
https://aclanthology.org/2023.acl-long.415.pdf
4 论文简介
研究表明,暗网与明网使用的语言有明显的不同。而由于对暗网的研究通常需要对该领域进行文本分析,因此针对暗网的语言模型可以为研究人员提供针对性的帮助。本文介绍了暗网数据预训练语言模型 DarkBERT。文章描述了为过滤和编译用于训练 DarkBERT 的文本数据所采取的步骤,以应对暗网文本存在极端的词汇和结构多样性的特点。我们对 DarkBERT 及其基础模型以及其他广泛使用的语言模型进行了评估,并且通过多个用例,证明了DarkBERT针对暗网领域的优势。评估结果表明,DarkBERT 的表现优于当前的语言模型,可作为未来暗网研究的宝贵资源。
5 解决问题
暗网作为恶意活动的首选平台,受到研究人员广泛关注,而暗网的NLP研究集中在网络威胁情报分析,研究人员已发现基于BERT的分类模型在暗网可用的NLP方法中实现最先进的性能,但由于暗网和表层网的文本特征存在差异,传统的预训练语言模型在暗网特定NLP任务上的表现效果并不理想。
本文希望设计针对暗网文本的NLP预训练模型,验证在网络安全相关任务中的检测优越性,为未来相关研究提供资源。
6 本文贡献
1)提出在暗网文本数据上进行预训练的语言模型DarkBERT
2)证明DarkBERT在暗网领域的有效性。评估表明,与其他预训练的语言模型相比,DarkBERT更适合暗网上的NLP任务
3)展示了DarkBERT的潜在用例场景,并表明与其他预训练语言模型相比,它更适合与网络安全相关的任务
4)提供了用于暗网领域用例评估的新数据集
7 论文方法
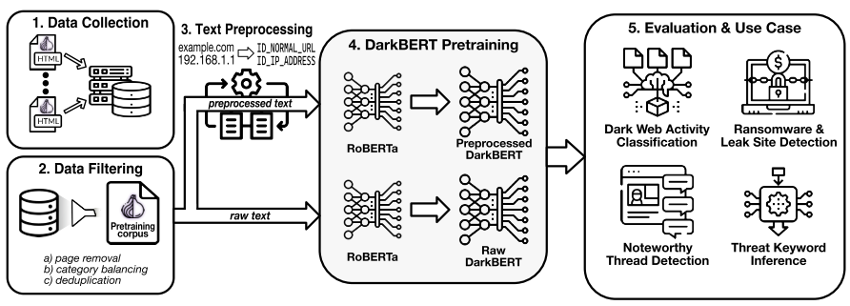
论文所设计DarkBERT的构造框架如图所示。
7.1 数据收集
设计一个预训练语言模型需要一个庞大的文本语料库。首先通过公开存储库和浏览器Ahmia收集种子地址,通过种子地址抓取暗网页面,扩展域列表,解析页面,将页面的标题和主体内容保存为文本文件。共收集约610万页。
7.2 数据过滤和文本预处理
庞大的数据中可能包含无用信息,需要进行数据过滤:
- 删除信息密度低的页面:首先对收集到的页面文本数据进行统计分析,确定信息密度判断的字符数阈值,再通过字符数判断信息密度,字符数异常低的可能是404页面或者是登录页面,字符数异常高的可能是信息大量重复的页面,对于模型训练没有实质性帮助,删除此类页面;
- 进行类别平衡:如果语料库中不同类别的数据差距过大,可能会使检测结果偏向于数据量大的类别,所以需要进行类别均衡,通过BERT构建模型,实现对页面的简单自动分类,对于某类别中数量过高的页面进行随机删除;
- 删除重复数据:重复的页面对于模型训练没有意义,通过minhash判断页面是否重复,移除重复页面。
并且模型不能从敏感信息中学习,且可能存在攻击者通过复杂攻击从语言模型中获得敏感信息的可能性,所以进一步对预训练语料库进行预处理,通过正则表达式、开源工具textacy识别出ip地址、比特币地址等,使用标识符掩码或直接删除文本。
7.3模型预训练
为降低计算成本,并保留现有模型学习的一般的英语表示,不从头进行预训练,选择RoBERTa作为基本初始化模型,并且采用,根据RoBERTa的分隔符标记对语料库中的页面进行分隔等操作,来满足DarkBERT和RoBERTa之间的兼容性。
8 实验结果
8.1 模型评估
常见的暗网相关NLP研究大多为页面分类,所以这里采用页面分类作为暗网领域的基准实验。
测试数据为DUTA和CoDA两个开源的英文暗网文本数据集,以经典模型BERT和初始模型RoBERTa进行实验对比。
可见针对暗网数据集DUTA和CoDA,DarkBERT的分类效果均好于另外两个对比模型。
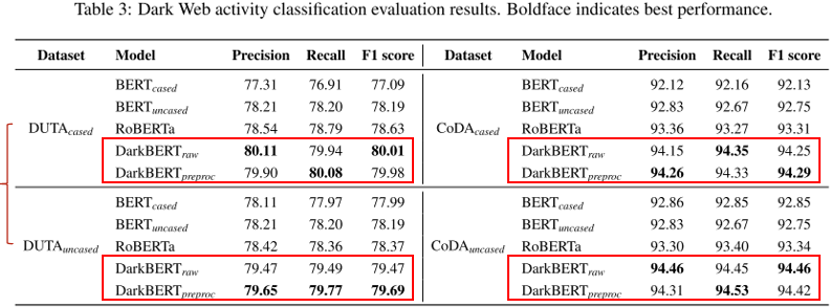
进一步,进行了结果分析,为什么数据集CoDA上的模型效果要优于DUTA(注:CoDA是研究团队的另一项研究成果)。发现DUTA中包含的某些类别可能不适合分类任务,且数据集中包含重复的文本,可能会在微调过程中过拟合模型。
再者,构建混淆矩阵来检查对于CoDA数据集的错误分类,发现对于大多数类别,DarkBERT的表现结果都要更好,但是对于某些类别,如毒品,电子产品和赌博,在所有四种模型中表现结果非常相似。可能是由于这些类别中的页面文本数据具有高度相似性,即明网、暗网中使用的语言差异较小,可能会影响模型分类的结果。
8.2 模型用例
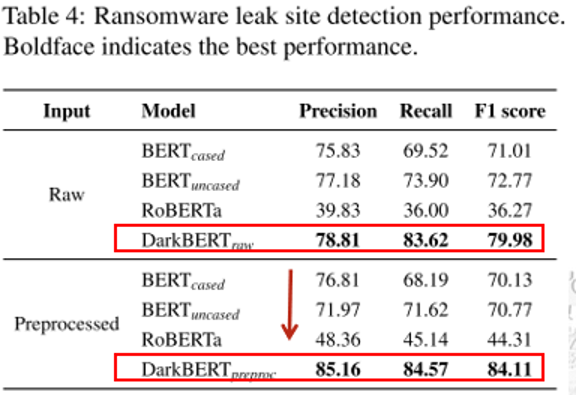
8.2.1勒索软件泄露网站检测
检测勒索软件组织,定期下载网页,特别是当新的受害者出现时。随机选择三个具有不同页面标题的页面作为正面示例,通过活动类别分类器选择与泄露网站相似的页面作为负面示例。
实验结果证明DarkBERT的表现效果更好,且通过数据预处理前后模型的性能提升来证明预处理环节的必要性
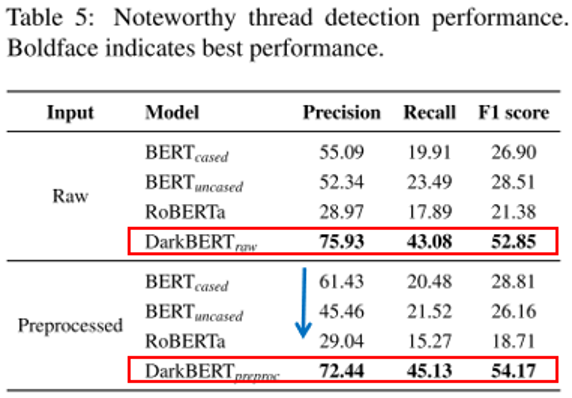
8.2.2值得注意的线程检测
“值得注意的”是一个主观性判断,研究人员选择专业人员对线程类型进行评估,合作进行注释。
实验结果显示DarkBERT的效果显著优于其他模型,且分析了性能指标为什么不好,增加附加特征可能可以提升模型的检测效果,并且分析了为什么进行数据预处理后模型检测效果变差,可能是因为标识符掩码的处理,无法判断线程是否与一个很出名公司、人相关,影响模型判断等。
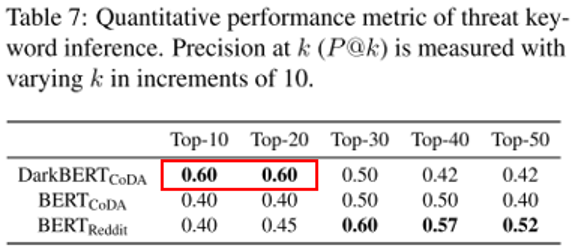
8.2.3威胁关键字推断
采用其他论文所采用的缉毒署公开文档作为测试集,对DarkBERT和对比模型都进行微调,使模型专注于drugs检测任务。
结果表明在k值较低时,明显DarkBERT的推断效果要优于其他模型,而当k值增加时,由于ground truth的数据集主要包含的是surface web的委婉语,DarkBERTCoDA的推断结果不包含在数据集中,所以BERT的效果更好。
通过暗网领域的多个用例,证明DarkBERT在网络安全领域的有效性。
9 本文优点
9.1实验数据集
1)数据集来源可靠——有针对性、有代表性
2)数据集标注可信——注释者来自专业公司、通过Cohen’s Kappa衡量达到注释者间一致性
9.2论文描述
1)对实验评估结果进行错误分析:从实验结果倒推到数据集特征,说明是数据集本身就没有区分度,并不是我模型不行
2)对模型用例实验过程描述详细:安全任务——任务实质——我们上难度——我们确实没那么好,但是我们比你们好,我们有潜力,你只要加点东西,我们就更好
3)实验验证具有针对性:不是BERT不够好,是在这个领域的检测你不够专业
4)所作所为有科学依据:评估采用页面分类——大部分研究都执行页面分类,所以采用此为基准实验;敏感信息掩码预处理——有研究证明可能通过复杂攻击从模型中获得训练过程中的敏感信息;类别均衡——有研究证明某个活动在暗网中占很大比例
10本文不足
10.1 论文内容
1)内容残缺:研究背景提到“暗网语言和表层网不同”,具体不同在哪,缺乏例子证明;自述为了探讨大小写对模型有没有影响而设计了两个数据集,最后实验结果也没有比较说明
2)避重就轻:在”evaluation页面分类”的部分没有说明为什么有些环节,预处理后的数据模型没有原始数据模型效果好,但是在“泄露网站检测”部分强调预处理后性能的进步,去凸显预处理的重要性
10.2实验数据
“出于道德伦理考虑”,该CoDA数据集对于犯罪领域并没有全部爬取,如儿童色情等