阅读链接:https://link.springer.com/chapter/10.1007/978-3-031-06433-3_19
提供源代码/数据库链接:项目有源码 数据集为:Deepfakes、Face2Face、FaceShifter、FaceSwap 和 NeuralTextures 子数据集中生成的视频。还使用了包含 5000 个视频的 DFDC 测试集。
技术路线概述:技术路线图
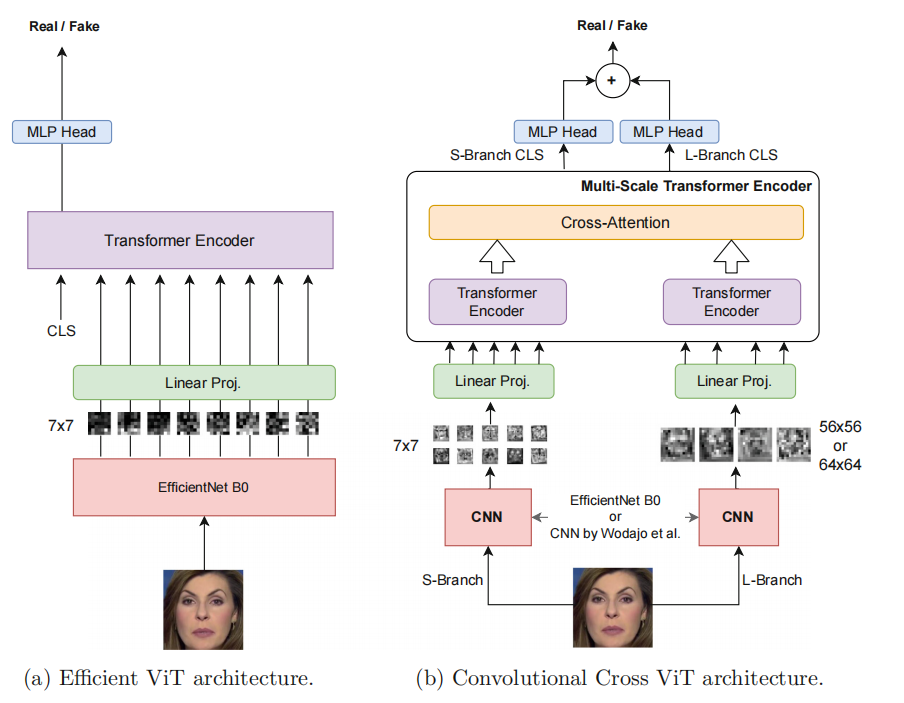
两个模块 Efficient ViT 和 Convolutional Cross ViT
该论文提出了两种架构,Efficient ViT 和 Convolutional Cross ViT,用于检测深度伪造视频。
Efficient ViT 由卷积模块和 Transformer 编码器组成,使用 EfficientNet B0 作为卷积提取器,并在推断阶段使用投票程序来聚合视频中多个人脸的分数。
Convolutional Cross ViT 则结合了 S-branch 和 L-branch 两个分支,分别处理较小和较大的图像块,并通过交叉注意力机制进行交互,以处理深度伪造视频中局部和全局的伪造特征。
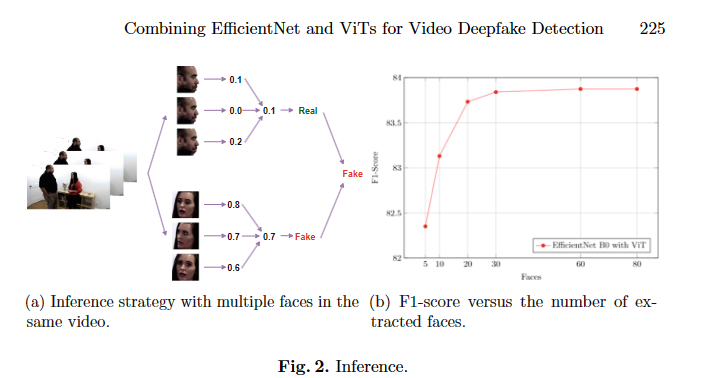
在数据集上的效果:
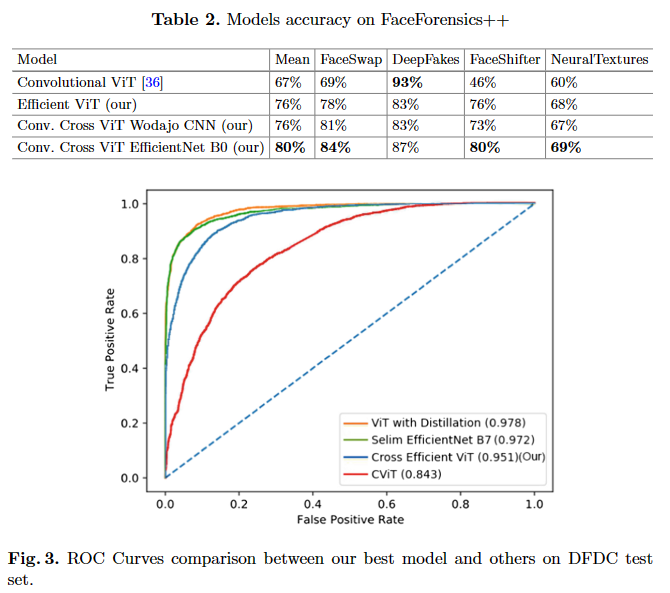
亮点之处
Efficient ViT 和 Convolutional Cross ViT 在深度伪造检测方面取得了与最先进方法相媲美的结果,尤其是 Convolutional Cross ViT 在使用 EfficientNet B0 作为补丁提取器时表现出了较高的准确性。此外,这些模型在参数较少的情况下实现了与其他最先进方法相媲美的性能,且在推断阶段处理视频中多个人脸的投票方案能够略微提高结果
论文中提出的模型是通过将 EfficientNet B0 和不同类型的 Vision Transformers 相结合来构建的[7]。Efficient ViT 模型由卷积模块和 Transformer 编码器组成,使用 EfficientNet B0 作为卷积提取器,并在推断阶段使用投票程序来聚合视频中多个人脸的分数[6]。Convolutional Cross ViT 架构则在 Efficient ViT 和多尺度 Transformer 架构的基础上构建,使用两个不同的分支(S-branch 和 L-branch)来处理较小和较大的图像块,并通过交叉注意力机制进行交互,以处理深度伪造视频中的局部和全局伪造特征[6]。
这些模型的创新点在于使用 EfficientNet 和 Vision Transformers 相结合的方式,以及在推断阶段处理视频中多个人脸的投票方案,这些方法在深度伪造检测方面表现出了潜力。
不足之处
虽然模型在大多数 FaceForensics++ 子数据集上表现优异,但在 DeepFakes 子数据集上的表现略逊于其他方法,可能是因为网络在特定类型的深度伪造视频上泛化能力较差。另外,虽然 Convolutional Cross ViT 在使用 EfficientNet B0 作为补丁提取器时表现出了较高的准确性,但仍然略低于其他最先进方法。