1 原文作者
Parisa Kaghazgaran (M University College Station, TX )
James Caverlee (M University College Station, TX)
Anna Squicciarini (Pennsylvania State University State College, PA)
2 论文来源
WSDM (2018)
3 论文地址
https://dl.acm.org/doi/abs/10.1145/3159652.3159726
4 论文简介
我们提出了一个名为TwoFace的系统发现针对在线评论系统的众包评论操纵者。TwoFace 的一个独特特征是它的三阶段框架:(i) 在第一阶段,我们通过利用揭示战略操纵证据的低适度众包平台智能地对操纵的实际证据进行采样(例如,审查操纵者);(ii) 我们然后传播这些种子用户的可疑性,以通过在“可疑性»»图上随机游走来识别相似的用户;并且(iii)最后,我们通过将用户映射到低维来发现(隐藏)充当结构相似角色的远距离用户捕获社区结构的嵌入空间。总共,TwoFace 系统在来自亚马逊的 38,590 名评论者的样本中恢复了 83% 到 93% 的所有操纵器。
5 解决问题
人工标记:依赖无监督算法或人工标记,由于标记人员无法获得评论作者的真实意图,可能容易出错。
事后分析:通过算法筛选排名靠前的结果,但这种方法倾向于关注非常明显的虚假行为,可能会忽略更微妙的行为。
模拟虚假评论:志愿者模拟假评论作者发布虚假评论,这种方法缺乏对真实的虚假评论作者的策略和动机的洞察。
证据不够充足:大量正常评论会掩盖虚假评论,两者偶尔在评级、评论的突发性、评论长度等方面表现不同,但不足以完全将两者区分开。
6 本文贡献
- 提出了TwoFace系统来发现在线评论系统中的众包评论者。
- 我们发现,与行为特征相比,社交特征在区分虚假评论者和正常评论者方面表现得更强。
- 我们发现,虚假评论者和正常评论者在评分、评论突发性等方面表现相对相似。
- 我们发现,研究参与多个众包活动的评论者对于发现表现不明显的虚假评论者发挥着关键作用。
- TwoFace系统恢复了83%到93%的虚假评论者,性能优于最先进的基线。
7 论文方法
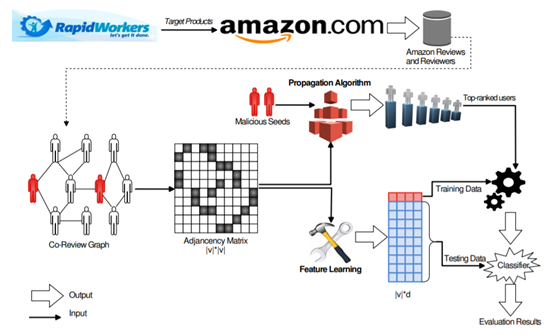
(1)爬取数据、种子用户:找出一批实锤的众包评论用户,这是种子用户。
爬取数据:
将众包网站上发布过众包任务的亚马逊商品爬取下来,然后爬取这些商品下的评论
收集所有爬取的的评论人员的所有以往的评论。
种子用户:
如果一个用户评价了两个以上的”众包商品”,就认为是水军:在亚马逊几百万商品中同时评论两个”众包商品”的概率太小了。
(2)可疑度传播:构建user-user的图,利用关联关系传播嫌疑度,找出图中存在关联关系的用户。
o-review graph:
c评价过相同商品的用户会有一条边,边的权重是评价过相同商品的数量
基于种子用户进行随机游走,得到一个基于种子用户的可疑用户排行:根据每个用户在co-review graph中与其他用户的连通性来计算每个用户的可疑度得分,在直觉上,欺诈行为的用户会对类似的产品撰写评论,因此他们可能会形成可疑的密集子图。
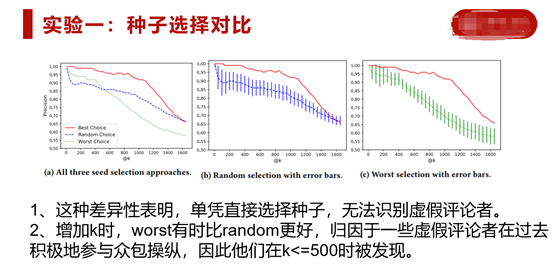
种子选择:
“Best”:选取经常性参与众包评论的用户。
“Random”:在已有的众包用户中随机挑选,这个接近现实情况(即随机游走选取)。
“worst”:选取偶尔参加众包评论的用户。

本文使用了 Jure Leskovec 于2016年 KDD 提出的node2vec 嵌入方法。简单来说就是对 DFS(深度优先) 和 BFS(广度优先) 搜索的结果进行采样,能够有效保存其邻居节点的结构信息。
(3)分类:将第二步得到的向量映射到低纬度空间,找出隐藏的图结构相似的可疑用户。
使用一些常用的分类器对“可疑度传播”构建的向量进行有监督的学习。
训练集的正样本来自种子集和其随机游走到达的节点,负样本来自普通商品中采样的正常用户。
选取了逻辑回归,朴素贝叶斯,随机森林,支持向量机和决策树
8 实验结果
数据:前面爬取的众包商品的评论,及这些用户的以往评论;从别人的数据集中抽取的正常评论。
训练集:正样本来自种子集和其随机游走到达的节点,负样本来自普通商品中采样的正常用户。


9 本文不足
10 代码和数据集地址