阅读笔记作者:慕宇
1 原文作者
Yang Zi (Xidian University), Haichang Gao(Xidian University), Zhouhang Cheng(Xidian University), Yi Liu(Xidian University)
2 论文来源
IEEE Transactions on Information Forensics and Security(2020)
3 论文地址
https://ieeexplore.ieee.org/document/8762148/
4 论文简介
验证码又称为全自动区分计算机和人类的图灵测试。目前﹐验证码在各类网站中,就是被用于区分恶意机器和合法人类用户的一层安全防御机制。基于文本的验证码是目前应用最广泛的验证码方案,但是大多数基于文本的验证码已经被破解。然而,以往的研究工作大多依赖于一系列的预处理步骤来攻击文本验证码,操作复杂且效率低下。在本文中,作者介绍了一个简单的、通用的、有效的并且不需要任何预处理的端到端攻击文本验证码的方法。通过一个卷积神经网络和一个基于注意力的循环神经网络,本文的攻击破坏了在Alexa.com中点击量排名前50的网站中广泛部署的真实文本验证码。此外,本文通过实验综合分析了大多数基于文本的验证码抵抗机制的安全性。实验结果表明,在不进行任何分割或预处理的情况下,反分割原则可以完全被深度学习攻击打破。
5 解决问题
目前对于文本验证码的识别,大都还使用基于字符分割的识别算法,对于不同的验证码需要设计不同的分割算法,过程繁琐且不具备不同验证码之间的普适性。随着深度学习技术的逐渐成熟,本文考虑是否存在一种算法,无需预处理和字符分割,就可以端到端的整体识别验证码;并且思考该算法是否具有良好的通用性和高效性。本文对上述的两个问题进行了深入的研究和探讨。
首先,提出一个端到端单步识别验证码的通用算法。为了最终能够达到较高的通用性和高效性,本文结合深度卷积神经网络,提出一个整体识别验证码的算法,该算法只需将验证码原图作为输入,经过训练可以直接得到输出,免去了预处理的流程,这也是该算法最大的优势之一。其次,验证该算法的通用性和有效性。本文通过线上验证码验证该算以及模拟生成验证码评估文本的方法证明该算法的高效性和通用性。最后提出一个可以同时识别多种不同的验证码通用模型。
6 本文贡献
本文系统地分析了文本验证码的安全性,总结验证码发展以来,用于增强文本验证码的安全性,防止恶意机器能够轻易破解验证码的9种不同的抵御策略,并通过大量的实验分析讨论抵御策略的安全性。
本文提出了一种通用的、有效的、端到端的验证码识别方案。该方法是一种基于编码器–解码器框架,结合卷积神经网络、长短期记忆网络和Attention机制的破解方法,利用深度学习技术,使用该方法在谷歌、百度、Yandez、微软验证码,以及目前Aleza.com中访问量排名前50的网站中,挑选了8个网站,共11种不同形式的文本验证码上,进行了全面的安全性分析。最终识别成功率在74.80%到98.30%,识别时间在0.09到0.23之间。该方法的识别准确率和速度均远高于早期的方法,该方法可以称之为是一个实时、通用且高效的算法。提出了一个验证码的生成系统,该系统可以生成形式更加全面的验证码。利用该生成系统,在后续实验中,可以避免收集验证码图片和人工打码的过程。本文还对混合背景方案、程式化方案和两层方案等特殊的抵抗机制进行了攻击。
最后,本文提出了一个通用的模型,利用一个模型同时去识别多种不同的验证码,在实际的识别任务中会更高效,部署更便捷。
7 论文方法
本文提出一个端到端的识别网络,略过传统方法的分割阶段,在无需进行预处理的前提下,单步的识别验证码中的字符。所谓端到端就是直接将原始的验证码图像放进网络中,就可以得到最终输出的识别结果。
该模型主要由编码器和解码器两部分组成。模型的编码器本质上是一个CNN,使用CNN从整个验证码图像中提取特征并送入解码器序列化识别。本文选择了Inception-v3作为提取特征的CNNs。编码器提取的特征向量记为f = fi,j,c (i和j为所特征向量f中第一位和第二维的位置,c为从Inception-v3提取的特征层的通道数)。
模型的核心是LSTM。它作为一个解码器,将特征向量f转换成文本序列。与传统RNN在长时间内存储信息的性能较差相比,LSTM克服了RNN在长期依赖方面的缺点,并显式学习何时存储信息。为了提高解码器的效果,本文引入Attention机制,相比早期编码器-解码器模型中,提取的特征f只作为解码器第0时刻的输出状态输入,或每个t时刻均输出相同的特征f,Attention机制在每个t时刻输入之前都会根据记忆单元C,的隐层输出和特征f自动学习出一个注意力权重,最后将这个权重与特征f的乘积用于计算输出结果。这个权重介于[0,1]的区间,0表示注意力不放在该处,1表示注意力应放在该处。最终该权重使LSTM在输出时,注意力集中于待识别字符的区域范围,忽略其他不相关的区域。采用Attention机制不仅提升解码器的准确率,还避免了对验证码中的字符提前预分割的步骤。
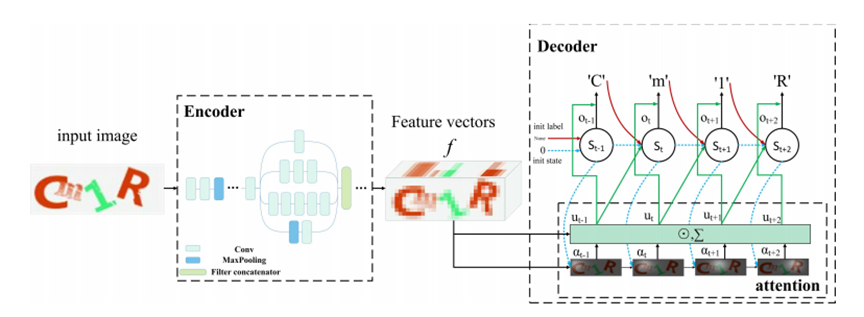
本文将LSTM网络在每个t时刻隐藏状态表示为st,LSTM 网络在每个t时刻的输入表示为xt,计算公式如式(1)所示:
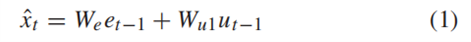
其中e是前一个时刻(t-1时刻)输出的字符的独热编码(one-hot encoding ),如上图中的红色实线所示,ut是注意力权值与特征f加权的乘积,如上图的绿色实线所示,ut的计算公式如式(2)所示:
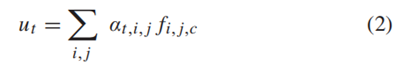
其中αt,i,j表示在当前t时刻,在(i,j)位置上的注意力权重值,这个权重是将当前LSTM的隐层状态st(如图蓝色虚线所示)和特征联结后,经过Softmax 激励函数得到的,具体计算公式如式(3)所示:
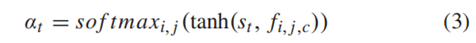
这个权重αt表示了在特征向量f的哪个区域对预测下一个字符起到更大的作用。当人类观察一张验证码图片时,人眼注视的焦点会自动从左边第一个字符依次向右移动。经过训练后,该网络的 Attention机制可以自动使当前待识别的字符区域的注意力权重变大。通过张图图最下面的四张图可以看到,越亮代表权重越大,注意力集中于该区域。
上一时刻的隐藏状态 st-1和当前的输入xt,共同作用于计算t时刻隐藏层输出ot和t时刻的隐藏层状态st。
最终,为了得到t时刻输出的字符分类的概率分布,本文将t时刻的注意力加权后的特征ut,以及该时刻隐藏层输出ot相结合,得到输出Pt,具体计算如式(4)所示:
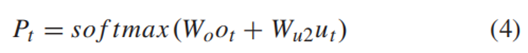
最后经过Sofhax激励函数后﹐得到每个字符的概率分布,最后选出概率最大的结果,作为该时刻的输出,并转换为最后的答案。
8 实验结果
8.1大规模验证码破解
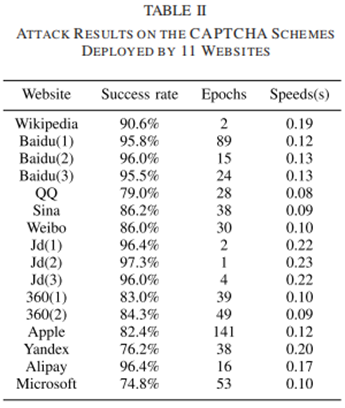
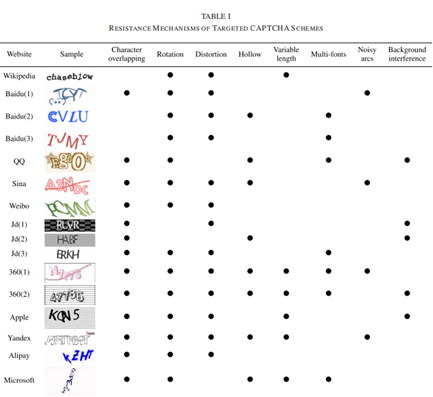
本文选择了11个网站部署的16个CAPTCHA方案,包括Wikipedia、百度、QQ、新浪、微博、京东、360、苹果、Yandex、支付宝和微软。它们的设计特点几乎涵盖了目前所有主流的抗阻机制。
从整体来分析,这16个验证码的识别准确率介于79.0%到97.3%之间,平均识别准确率为88.9%。识别速度介于0.09秒到023秒之间,平均识别速度为0.15秒,其速度远超过人眼识别和人眼反应的时间。在之前的一些研究中提到的,只要验证码破解准确率超过1%,就可以视为是一次成功的破解,而本研究的准确率可以称之为完全成功的破解了11种线上部署的验证码。
8.2与早期破解结果的对比
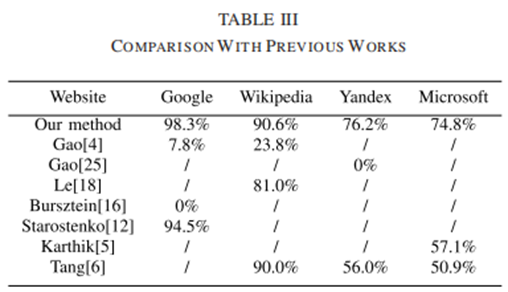
表三的右边4列结果中,对比了谷歌、维基百科、Yandex和微软这四种验证码与早期破解过相同验证码的相关工作对比。从结果中纵向对比可以看出,对于同一种验证码,本算法的结果全部都优于其余所有的之前最好的结果,这说明本文提出的方法,在识别准确率上,具有不错的效果,可以在未来中发挥应用。
在表三中,除了Tuan团队的方法外,其余的方法均使用基于分割的算法,然后再训练了一个用于识别单个字符的CNNs 分类器,但是分割方法需要专门为每个验证码单独设计,并且所使用的CNNs较为简单,无法提取到更鲁棒的字符特征。
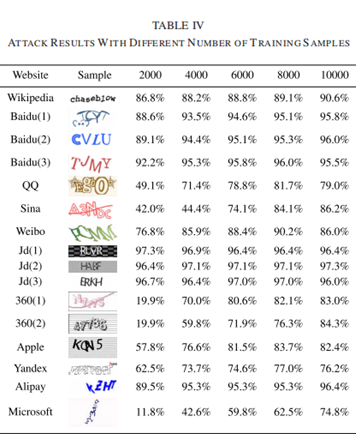
8.3使用不同数量的训练样本进行攻击
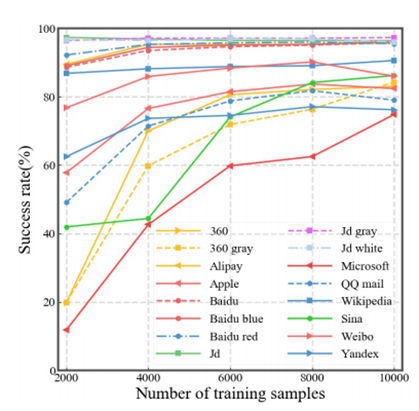
为了在效率和准确性之间取得平衡,本文进行了一系列的补充实验。对于表四中的每个CAPTCHA方案,本分别设置用于训练的样本数为2000、4000、6000和8000。攻击结果如表四所示,在2000个真实样本下,本文的方法在16种验证码中有13种的成功率超过40%。在4000个真实的样本中,本文的方法在16个验证码中有13个的成功率超过70%。下图为每个CAPTCHA方案的成功率与训练样本数量之间的关系曲线。总的来说,成功率随着训练样本数量的增加而增加。
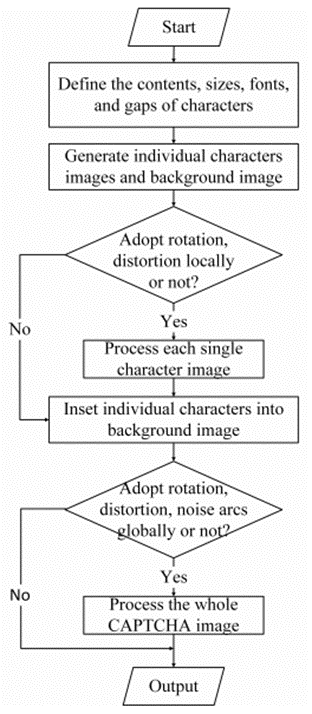
8.4验证码生成系统
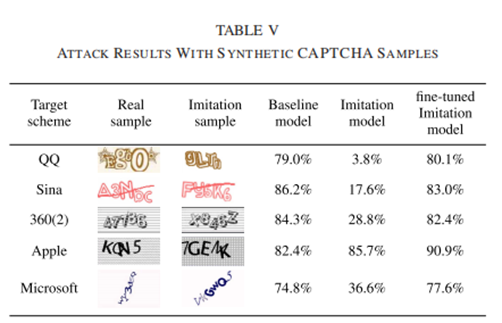
本文生成了如表五第一列所示的5种验证码,分别是QQ、新浪、360、苹果和微软。模拟模型的成功率在3.8% ~ 85.7%之间。为了纠正合成样本和真实样本之间的差异所造成的错误,本文使用了一个小的数字(500)真实世界的样本,以微调模仿模型。结果如表五最后一栏所示,微调模型的成功率在77.6% – 90.9%之间。微调模型的性能与基线模型相当,甚至优于基线模型。
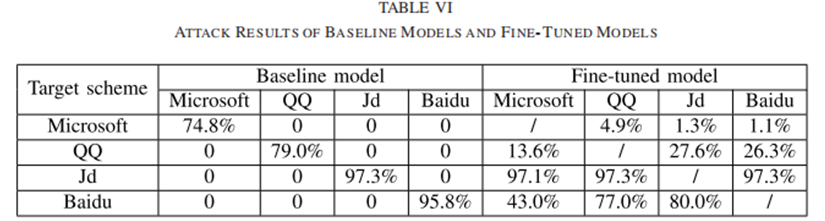
为了进一步测试模型的泛化能力,使用一个在一个CAPTCHA方案上训练的模型来攻击另一个方案。如表六所示,成功率均为零,因为这四种方案的特点是非常不同的。接下来,使用微调策略,用1000个真实世界的样本对每个基线模型进行优化。经过微调的模型的攻击结果也如表六所示。经过微调后,模型的性能有了明显的提高。
8.5正常抵抗机制的安全性
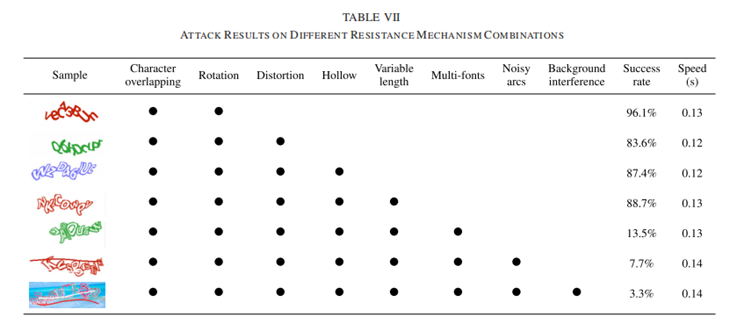
随着CAPTCHA复杂度的增加,成功率从96.1下降到3.3%,说明使用了倍数的组合抗性机制增强了文本验证码的安全性。
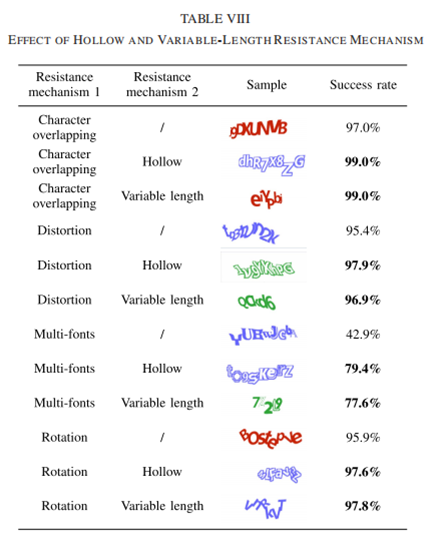
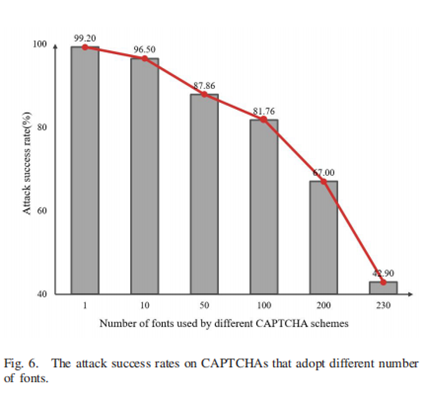
在所有方案中,空心和变长策略的采用略微提高了攻击成功率,而多字体方案的采用导致攻击准确率急剧下降。对于每一个使用一种阻力机制的基本CAPTCHA方案,一旦加入中空机制,成功率都有一定程度的提高。造成这种异常的原因是本文的字符识别过程依赖于轮廓特征,空心机制使得每个字符类别的轮廓更加清晰,降低了该方法的识别难度。根据表八的实验,验证码的平均长度为当字体数量从1个增加到230个时,成功率从99.2%下降到42.9%。多字体机制的采用使得每个字符类别的形状更加多样化,大大增加了字符识别的难度。实验结果表明,多字体机制确实是抵御深度学习攻击的有效机制。
8.6具有特殊抵抗机制的验证码
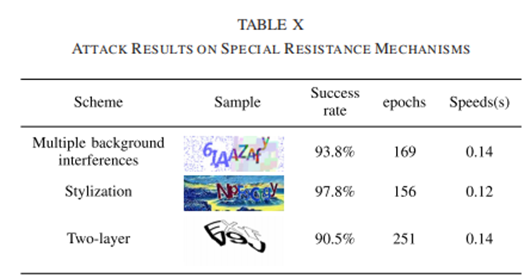
本文还研究了三种特殊的抵抗机制,包括多重背景干扰、程式化和双层结构。实验结果如表X所示。
8.7Large-Alphabet验证码

本文使用GB2313字符集作为字符库,其中包含了3755个最常用的字符。生成三个中文验证码,分别模仿百度、BotDetectTM-Chess和天涯的验证码。在少量的训练时间内,三个验证码的成功率分别为96.5%、99.6%和99.9%。
8.8基于文本的验证码的选择性识别
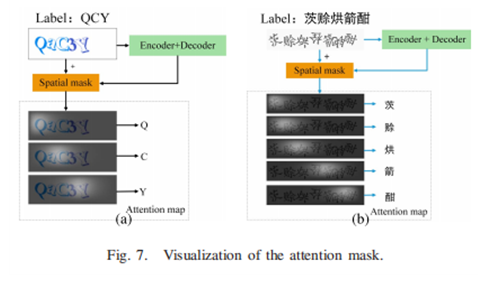
在某些验证码方案下,只要求识别图像中的部分字符。如下图:左边是一个罗马字母的验证码,用户只需要输入大写字母。右边是一个中文验证码方案,有些汉字是倒装的,要求是识别出所有直立的汉字才能通过测试。对于这种类型的机制,只需忽略不需要的字符标记训练样本。两种方案的成功率分别为99.7%和99.9%。
8.9通用模型

考虑到现实世界中有数百种基于文本的CAPTCHA方案,希望训练一个通用模型来破解多个CAPTCHA方案。本文生成了10个特征明显的CAPTCHA方案作为训练样本(如表12所示),每个CAPTCHA使用20万个样本来训练模型。这个模型被训练了300个时代。对于每个方案准备了3000个样品进行测试。不同方案的成功率为58.7% ~ 96.7%,平均速度为0.12秒。实验结果表明,一个通用模型可以破解多种验证码。
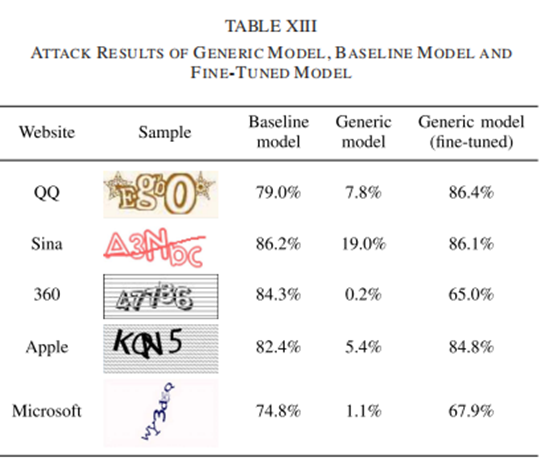
然而,目前尚不清楚现有的通用模型是否适用于培训过程中没有包含的新验证码。为了检验这个想法,本文使用了表二中的其他五种CAPTCHA方案。对于每个方案,准备了500个测试样本并分别运行攻击。但是通用模型在新的验证码上表现不佳。然后,对于每个方案,使用1500个对应的真实世界样本对泛型模型进行了微调。经过微调的泛型模型再次获得了更高的成功率,成功率在65.0% – 86.4%之间,如表十三所示。这表明泛型模型确实可以攻击多种CAPTCHA方案,但在处理新的CAPTCHA方案时,需要先对泛型模型与目标方案样本进行微调。
9 本文不足
本文提出了一种识别文本验证码的通用算法,攻击力11中不同形式的文本验证码,进行了全面的安全性分析,并且提出了一个验证码生成系统,但是没有彻底解决收集验证码图片和人工打标耗费人工的成本高的问题。