1 原文作者
Yuan Gao(pursuing Ph.D. degree in pattern recognition and intelligent systems from the Key Laboratory of Intelligent Perception and Image Understanding of Ministry of Education of China, Xidian University, Xian, China)
2 论文来源
TGRS (2021)
3 论文地址
https://ieeexplore.ieee.org/abstract/document/9076796
4 论文简介
(1)研究背景:虚假评论数据集获取有难度;人工难以大量标注虚假评论检测问题。
(2)现有研究方法有局限性
虚假评论精心制作,人工筛选的特征如文本长度很可能无效;有监督学习时,标注出错容易影响结果
5 解决问题
(1)试图解决的问题:无监督学习下的虚假影评检测
6 本文贡献
(1)针对一个被忽视的新兴领域——电影评论。
(2)该方法采用基于注意的无监督模型和条件生成对抗网络。
(3)介绍了一种注意机制和以用户为中心的模型,该模型优于以评论为中心的模型,因为收集用户的行为证据比欺骗性评论的特征更有效。
(4)引入不匹配的影评对作为假样本,缓解了缺乏标记的欺骗性评论的问题
7 论文方法
详细描述本文提出的技术路线(包括但不限于方法、算法、模型等)。
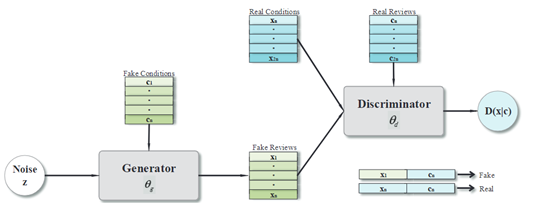
- CGAN
- 一批电影特征被采样并作为条件输入到生成器中,和噪音一起生成评论;从训练集中重新抽取另一批电影特征和相应的评论,并表示为真实的;重新采样的电影特征和生成的评论对被标记为假的
- 鉴别器能够从评论中学习语言特征和匹配关系,从而识别与语言风格或语境不匹配的欺骗性评论。
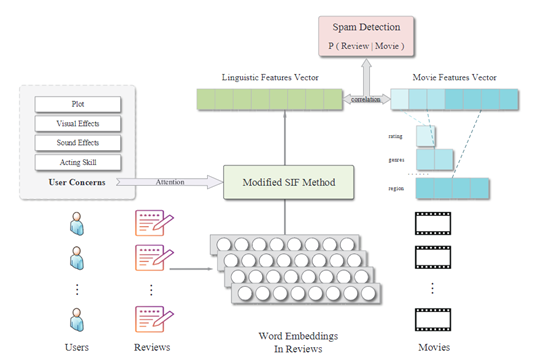
- SIF
- 简单平均的初始词嵌入效果并不好,因为常用词与关键词具有相同的权重。SIF类似TF-IDF,简单来说,就是词向量的加权平均表示为句子向量。然后在整个数据集上进行SVD分解获取句子的公共部分,每个句向量减掉这部分,与类似CNN自动提取的方法意义上类似。
- 作者做了一点改动:加入了Attention:电影元素的特征词:文献[43]证明,当用户对产品特性进行评论时,评论中的词语总是趋同的,少数词能够捕捉到大部分特征(如何使用,在SIF中,这些词的频率被设为0,他们属于高频词但是没有降低权重)
8 实验结果
详细描述本文实验及相关结论。
- 实验数据
请五名志愿研究生对数据集做出独立判断。收集了9部电影中3261名用户的13056条评论作为测试集,其中真实评论10268条,欺骗性评论2788条,然后将这些用户的剩余历史评论用于训练。
- 实验结果
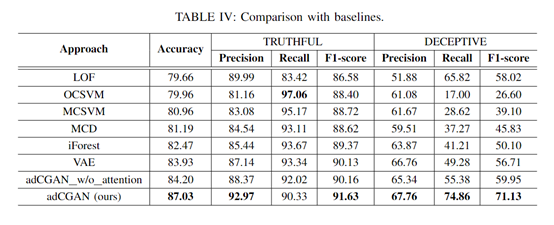
结论:对比了各种无监督学习模型,认为自己提出的无监督模型达到最好的效果。
9 本文不足
1.本文不足
- 使用一个电影画像条件下生成的评论,与另一个电影画像成对之后,就是虚假评论?这一点值得商榷。
- 其次,文本已经被一些论文认为是低级的 特征,不能仅从文本判断评论的真实性。
2.可改进方面:
- 融入其他统计特征
10 代码和数据集地址
未提供