阅读笔记作者:张沛然
备注:
1、论文阅读笔记将同步更新到四川大学网络空间安全协会学术园地版块(https://www.scucyber.cn/adversarial-socialbots-modeling-based-on-structural-information-principles-论文阅读笔记/);
2、论文阅读笔记需要同时通过Synology Drive上传到资源共享平台和协会学术园地版块收稿邮箱1092477425@qq.com并抄送到whzh.nc@scu.edu.cn,邮件中注明该文档在网站发布时的作者为本人真实姓名还是昵称(昵称命名不得违规)。
1 原文作者
Xianghua Zeng (Beihang University),Hao Peng (Beihang University),Angsheng Li (Beihang University,Zhongguancun Laboratory)
2 论文来源
Proceedings of the Conference on Artificial Intelligence 2024(AAAI2024)(CCF-A)
3 论文地址
https://ojs.aaai.org/index.php/AAAI/article/view/27793
4 论文简介
有效检测的重要性在于社交机器人模仿人类行为传播虚假信息,导致社交机器人和检测器之间的持续对抗。尽管反应型检测器快速发展,但对抗性社交机器人建模的探索仍不完整,显著阻碍了主动检测器的发展。为了解决这一问题,作者团队提出了一个基于结构信息原理的对抗性社交机器人建模框架,即SIASM,以实现更准确和有效的对抗行为建模。首先,提出一个异构图来整合社交网络中的各种用户和丰富活动,并通过结构熵来测量其动态不确定性。通过最小化高维结构熵,生成社交网络的层次社区结构,称为最佳编码树。其次,设计了一种新方法,通过利用分配的结构熵来量化影响,从而减少SIASM的计算成本,过滤掉无影响力的用户。此外,定义了社交机器人和其他用户之间的新条件结构熵,以指导跟随者选择,实现网络影响力最大化。在同构和异构社交网络上的大量对比实验表明,与最先进的基准相比,当使用准确率达90%的健壮社交机器人检测器进行评估时,所提出的SIASM框架在网络影响力(提高高达16.32%)和可持续隐蔽性(提高高达16.29%)方面显著提升。
5 解决问题
论文针对的问题是现有对抗性社交机器人建模的不准确性,尤其是在Thai Le等人提出的对抗性社交机器人学习(ASL)问题中,如何优化粉丝网络以最大化影响力,同时保证社交机器人的隐蔽性。
6 本文贡献
本文的主要贡献在于如下方面:
1. 提出了SIASM(Structural Information principles based Adversarial Socialbots Modeling framework)框架,使用异构图神经网络整合社交网络中的用户和活动,并通过结构熵测量动态不确定性。
2.设计了量化网络影响力的新方法,减少了计算成本,过滤掉无影响力的用户。
3. 定义了社交机器人与其他用户之间的新条件结构熵,以指导跟随者选择,实现网络影响力最大化。
7 论文方法
总的来说,本文提出的SIASM框架包括三个阶段:图构建、活动确定和关注者选择,具体如下所示:
1. 图构建阶段:将异构社交网络转化为多关系用户图,并编码网络结构;
2. 活动确定阶段:选择社交活动,简化多关系图为同构图,并生成最优编码树;
3. 关注者选择阶段:量化用户网络影响力,移除低影响力用户,测量条件结构熵指导关注者选择;
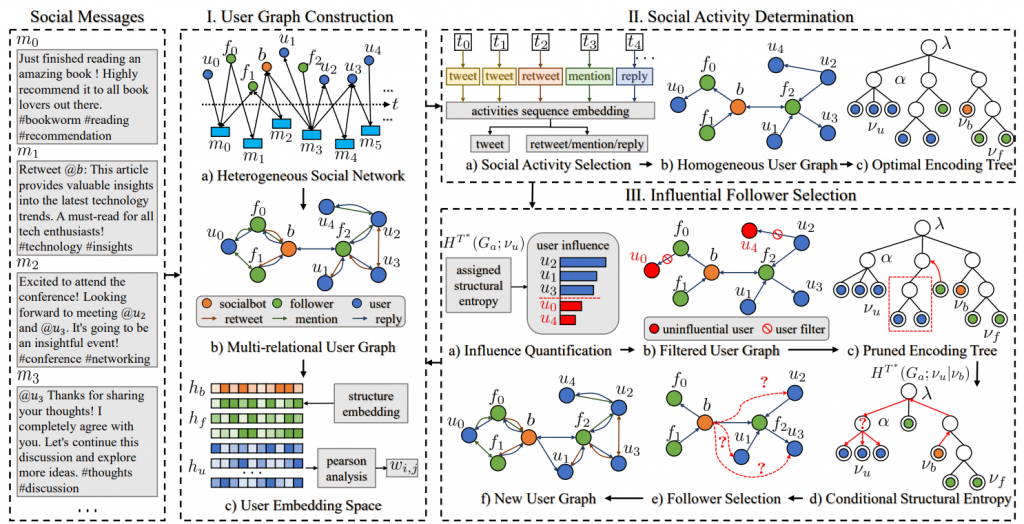
图1为原文作者构建的SIASM框架,该框架由上述三部分组成,接下来对其进行具体解释:
7.1 关键词生成器具体构建过程
基于社交消息的历史记录,作者团队提取用户元素和各种社交活动,包括推文、转发、提及和回复,构建如图一所示的异构社交网络。为了保留不同元素之间的异构信息,作者团队将社交图转换为多关系用户图。如图一所示。在这个多关系图中,顶点V表示社交用户,包括社交机器人B和关注者F。这些集合配备了预训练的词嵌入和时间戳编码特征,增强了它们的语义表示和时间信息。当用户以不同的社交活动A分享相同消息时,在Gm中建立代表各种用户关系的边。由于在多关系图中的这些关系中的杂质水平不同,并且共同影响嵌入结果,作者团队采用R-GCN网络(Schlichtkrull et al. 2018)对Gm的结构进行编码。对于每个用户顶点v,将其预训练特征和多关系结构信息集成在一起,编码成一个d维的嵌入向量hv,如图一所示。
7.2 活动检测器具体构建过程
在这个阶段,SIASM引入了一个强化学习智能体,动态选择一种社交活动类型来简化多关系图,将其转换为同构用户图,并最小化其结构熵。此过程生成了社交用户的层次社区结构,以便于后续选择有影响力的关注者。
在每个时间步,强化学习智能体将其活动历史编码为一个固定维度的向量,并利用学习到的表示来确定要执行的社交活动类型,旨在实现可持续的隐蔽性,如图一中步骤II.a所示。如果选择推文,那么在该特定时间步内,SIASM框架将跳过有影响力的关注者选择阶段。基于选择的活动a,作者团队通过消除代表其他类型社交活动的有向边,将多关系图Gm简化为同构用户图Ga,如图一所示。为了计算每条有向边的权重,作者团队对其表示进行Spearman相关分析,如下所示:

为了评估特定活动a对社交网络的影响,作者团队将消息传播建模为同构图Ga中用户之间的随机游走,并结合结构熵来量化固有的动态不确定性。通过最小化其高维结构熵,作者团队生成了一个最优编码树,作为用户社区的层次划分结构。具体来说,作者团队为同构图Ga初始化一个单层编码树T,如下所示:
(1) 对于整个顶点集V,生成一个根节点λ并设定Vλ=V;
(2) 对于每个顶点v,生成一个叶节点v并设定Vv={v};
(3) 对于每个叶节点v,将其父节点设为根节点λ,记为v–=λ。此外,作者团队采用HCSE算法(Pan, Zheng 和 Fan 2021)中的两个操作,stretch和compress,以优化单层编码树。在作者团队的工作中,作者团队将对层i中所有树节点Ui进行一轮stretch和compress操作所带来的结构熵平均减少量。通过迭代和贪婪选择树节点执行上述操作,作者团队生成了具有K层的最优编码树T*。优化过程总结如下算法1。在每次迭代中,作者团队检查同一层的所有节点集,以确定最大化结构熵平均减少量的节点集Ui(算法1第3行),然后对Ui*中的每个节点执行stretch和compress操作(算法1第7和8行)。作者团队继续这些操作,直到树的高度达到K(算法1第2行)或没有满足条件的节点(算法1第4行)。作者团队终止迭代并将T输出为最优编码树T*。

图2中的编码树T*展示了社交用户的层次社区结构,其中每个树节点代表一个用户社区,其高度表示该社区在层次结构中的位置。每个叶节点v对应一个包含单个用户顶点v的单例,Vv={v}。每个非叶节点a对应一个新社区Va,由其子社区组成,根节点λ对应整个社交用户集,Vλ=V。
7.3 交互分类器具体构建过程
在前一阶段确定活动类型之后,SIASM会量化每个用户社区的网络影响力,并计算社交机器人与每个叶节点之间的条件结构熵,以指导选择粉丝,从而最大化其社交影响力。
对于最优编码树T*中的每个树节点a,作者团队使用公式3计算其分配的结构熵。直观上,较高的结构熵值表明用户社区Va内发生特定类型的社交活动a的可能性比从a的兄弟节点开始的其他社区更大。在图一的步骤III.a中,作者团队通过求和从根节点λ到节点a的路径上每个树节点β的发生概率来量化用户社区Va的网络影响力Ia,具体如下:

为了减少粉丝选择问题的规模,作者团队会修剪从T*中网络影响力较低的节点a开始的分支,并从图Ga中过滤掉社区Va内的所有用户,如图一中的步骤III.b和III.c所示。这种策略有效地减少了潜在粉丝的数量,确保了SIASM框架的高效性。在本研究中,作者团队将过滤掉的用户节点比例和修剪的子树高度分别设置为5%和1。
作者团队追踪每个潜在粉丝u从vu到根节点λ的路径,并在这条路径上的每个树节点δ处验证社区Vδ内是否存在社交机器人b。当作者团队定位到一个节点δ其社区Vδ包含v和b时,作者团队计算条件结构熵,如图一中的步骤III.d所示:
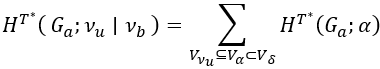
作者团队利用条件结构熵来测量从父节点δ到叶节点vu的不确定性,其中a是这条路径上的任意节点。这种熵反映了新闻从社交机器人b传播到用户u的概率,并将其用作最大化社交机器人网络影响力的初始选择概率。为了进一步优化这个概率,作者团队采用演员–评论家强化学习(PPO)算法(Schulman et al. 2017)。为了实现高效的优化过程,作者团队使用状态抽象机制(Zeng et al. 2023b),从所有顶点的表示向量中提取关键特征,从而实现有效的粉丝选择,如图一中的步骤III.e所示。最后,社交机器人将用户u添加为新的粉丝,并构建一条社交活动a的有向边,从而生成更新后的用户图,如图一所示。
8 实验结果
本文作者在同构和异构社交网络上进行实证和比较实验,以验证SIASM框架的优越性。每次实验都使用五个随机种子进行,以确保评估的公正性并避免差异。
8.1 实验设置
数据集:为了分析同构数据集,作者团队收集了推特上关于美国总统选举和COVID-19大流行主题的前100篇热门文章,并研究它们的传播网络,这些网络包括1500名社交用户。对于异构网络分析,作者团队使用最新的Higgs推特数据集(De Domenico等人,2013),其中包括有向多关系互动。这些网络由多个星形社区组成,连接有限,与之前的研究观察一致(Sadikov等人,2011;Kamarthi等人,2020)。像其他研究(Le, Tran-Thanh和Lee,2022)一样,作者团队选择10%的真实网络构建合成随机网络作为训练集,其余90%的收集网络作为测试集。
基线:该文将SIASM与最新的对抗性社交机器人建模方法ACORN(Le, Tran-Thanh和Lee,2022)进行比较。此外,作者团队结合几种经典启发式方法(CELF(Leskovec等人,2007)和DEGREE(Chen, Wang和Yang,2009))与之前学习的代理创建其他基线,称为ACORN-H和SIASM-H。
8.2 评估
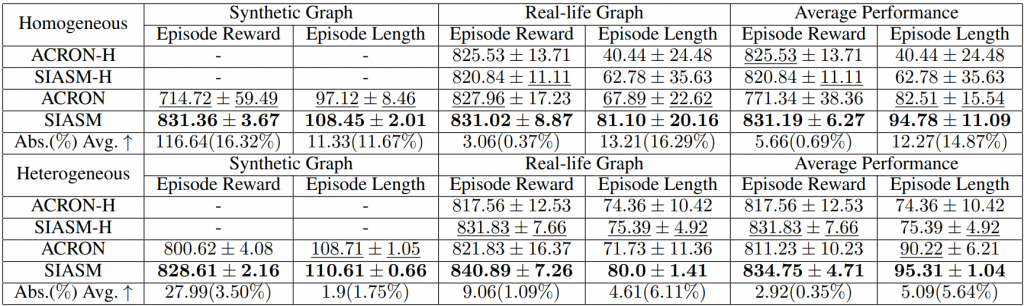
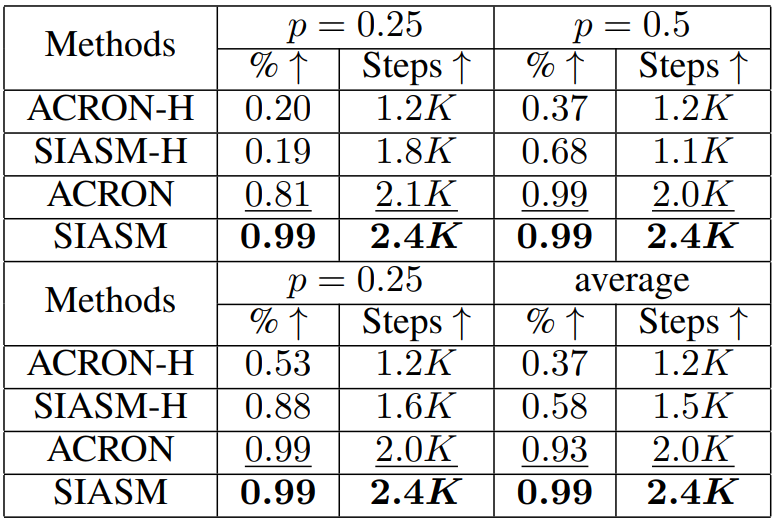
在本节中,作者团队在同构和异构社交网络中使用合成图训练模型并测试其性能。实验结果的平均值和偏差总结在表1中。分析表明,SIASM在合成图和真实图中显著提高了奖励和长度。具体来说,SIASM在奖励和长度上分别提高了116.64(16.32%)和13.21(16.29%),展示了其在网络影响力和可持续隐蔽性方面的优势。此外,以下小节分别详细分析了在同构和异构数据集上进行的实验。
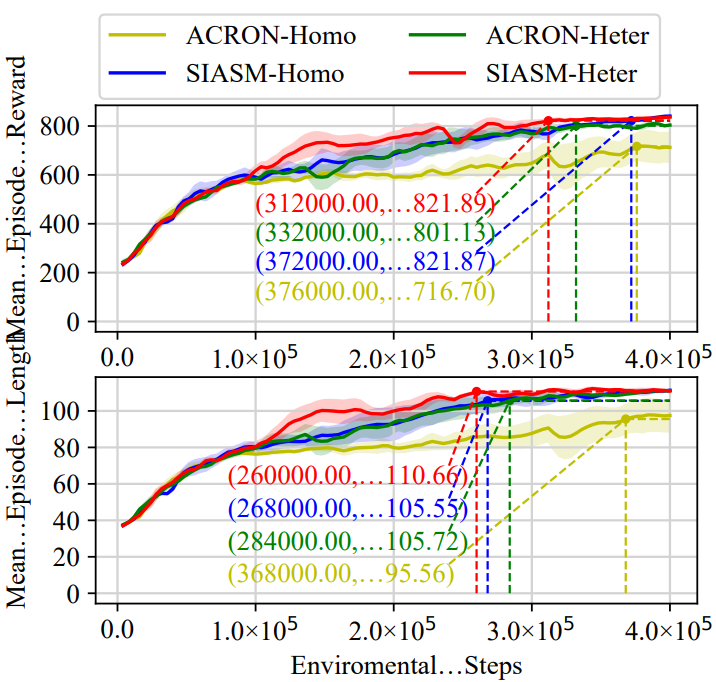
同构数据集:在每个同构社交网络中,作者团队不考虑不同类型的用户活动(如推文、转推、提及和回复),而是将其建模为同构用户图。在合成图的训练过程中,作者团队使用默认传播概率(p)为0.8,最大回合长度(Tmax)为120。如图3所示,作者团队的SIASM框架在更少的环境步骤(312000和260000)下收敛,并在网络影响力(831.36)和可持续隐蔽性(108.45)方面表现优于其他方法。这些优势表明SIASM在学习粉丝选择和检测规避策略方面的效率,导致了理想的结果。
在使用真实图进行测试的过程中,作者团队改变了p值并测量网络影响比,即接收到目标消息的用户数量与所有用户数量的比率,结果如图4所示。总体而言,SIASM在所有基线方法中表现稳定,尤其是当粉丝数量超过294时,|F| > 294。显然,无论传播概率如何,SIASM在与较少社交用户互动的情况下,稳定地实现了更显著的影响力。这一优势归因于SIASM能够基于结构熵的全局特征选择合适的粉丝,从而克服了依赖局部特征进行节点选择的基线方法的局限性。
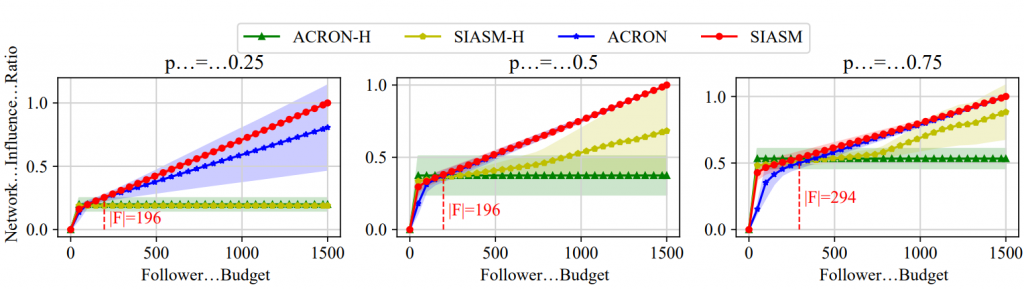
此外,作者团队还进行了额外的评估,以衡量所有比较方法的可持续隐蔽性。作者团队在真实网络中测量了它们的存活步骤,并在表2中总结了比较结果。结果表明,作者团队的SIASM表现出强大的持久性,在各种真实场景中持续了2.4K个时间步,并且网络影响比为0.99,显著优于其他方法。
异构数据集。在异构环境下,作者团队保留多关系的社交活动,以获得更全面的用户嵌入,并基于结构信息的原则建模对抗性社交机器人行为,如图一所示。SIASM和其他基线模型使用与同构训练一致的默认训练参数p和Tmax进行训练。这些模型的训练曲线如图3所示,其中SIASM表现出最快的收敛速度,并以828.61的单次奖励和110.61的单次长度实现了最佳性能。通过有效利用原始社交网络中的异构信息,SIASM及其变体SIASM-H在网络影响力(分别为840.89和831.83)和持续隐蔽性(分别为80.0和75.39)方面,在真实图测试中表现出最高和第二高的性能。
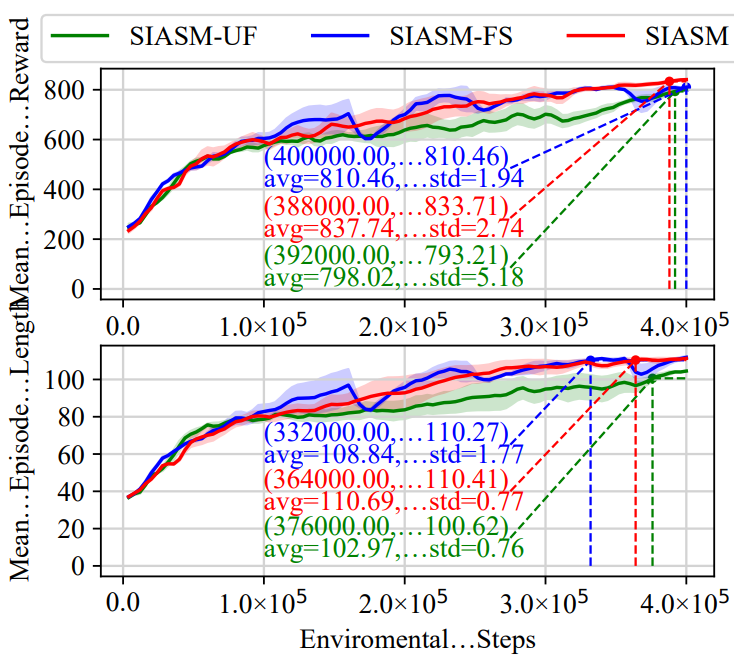
消融研究。在本文中,作者团队在同构社交网络上进行了消融研究,以考察SIASM中用户过滤和粉丝选择阶段的影响。相应的变体分别称为SIASM-UF和SIASM-FS。图5所示的结果表明,移除用户过滤或粉丝选择阶段都会降低策略学习的整体质量和效率。这些发现表明,过滤和选择阶段在增强对抗性建模性能方面起着至关重要的作用。
9 本文不足
我认为本文的主要不足有如下两点:
1. 实验中一些细节被隐去。
2. 图片排版存在问题。
10 代码和数据集地址
该论文中代码地址: