1 原文作者
Sergio G. Burdisso (Universidad Nacional de San Luis)
Marcelo Errecalde (Universidad Nacional de San Luis)
Manuel Montes-y-Gómez (Instituto Nacional de Astrofísica, Óptica y Electrónica)
2 论文来源
Expert Systems With Applications, 2019
3 论文地址
https://www.sciencedirect.com/science/article/pii/S0957417419303525
4 论文简介
面向在线社交网络的早期威胁检测问题(Early Risk Detection, ERD)包括早期抑郁症检测、早期谣言检测、性捕食者识别等。由于这些任务会参与到人们的日常决策中并修正他们的决定,这类系统需要具备增量学习能力(Incremental Learning)以及自主决定多少量的数据足以分类的能力。然后,目前主流的机器学习方法具有黑盒和不能支持增量学习的两大缺陷,本文提出一种能解决上述ERD问题的有监督文本分类通用框架——SS3。在CLEF’s eRisk2017的早期抑郁症检测数据集上的实验证明了本文提出的框架能达到该任务的SOTA结果,并且具有优良的计算性能和可解释性。
5 解决问题
现有的工作在解决ERD问题时存在以下缺陷:
- 模型无法自主决策何时输出分类结果
- 模型的黑盒性质隐藏了输出以及何时输出分类结果的原因
- 模型无法增量式的构建学习文本特征(例如SVM每次分类都需重新构建文档词矩阵)
因此,本文设计一个全新的文本分类器,能够同时满足:增量分类、早期分类和高可解释性三个要求。
6 本文贡献
提出了一个能够同时支持增量分类、早期分类和可解释的通用文本分类框架SS3,并在CLEF eRisk2017早期抑郁症检测数据集上验证了这三个特性。
7 论文方法
如下图,对每个文档,按照层次一级级切分至单个词(比如文档切分成段落、段落切分成句子、句子切分成单个词)。对于每个词,用本文提出的算法提取其向量。然后对每层得到的向量按照某个操作
逐层聚合成一个文档表示向量。最后将这个文档表示向量放入分类器分类。
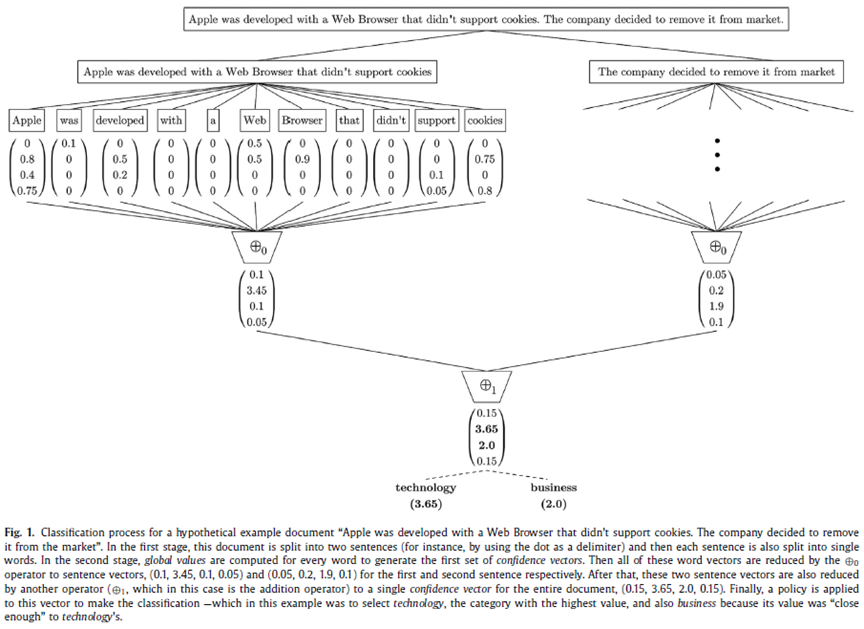

其中,gv为global value,Ci为类别,w表示词,gv(w)可描述为对于词w计算它在每个类别Ci中的global value。在本文,类别C为抑郁或者非抑郁。
gv:global value的计算参考了tf-idf的思想,计算公式如下
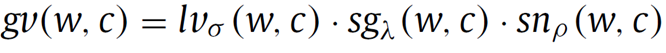
其中lv表示w在c中的局部值算子(local value of w in category c)。sg表示w在c中的重要性算子(significance of w in category c),sn表示w在c中的裁剪度算子(sanction of w in category c)。其中为这三个算子的超参。这三个算子的计算公式如下:
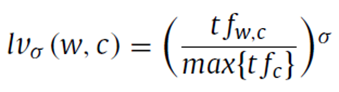
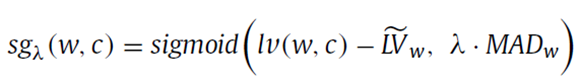
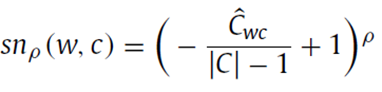
lv为w在类别c的文档集中的词频除以c中最高的词频(normalized value of term frequency of w in c);
sg:如果w在中的lv值和它在其他类c中的lv值都很接近,则w在类中的sg值就尽可能接近0,如果w在中的lv值明显高于在其他类c中的lv值,则w在类中的sg值就尽可能接近1;
sn:如果w只在一个类c中sg值很大,那么w的sn值就尽可能接近1,如果w在多个类c中sg值都很大,那么w的sn值就尽可能接近0。

8 实验结果
模型的训练的损失和模型评估指标是有Losada and Crestani在2016年提出的Early Risk Detection Error(ERDE)。
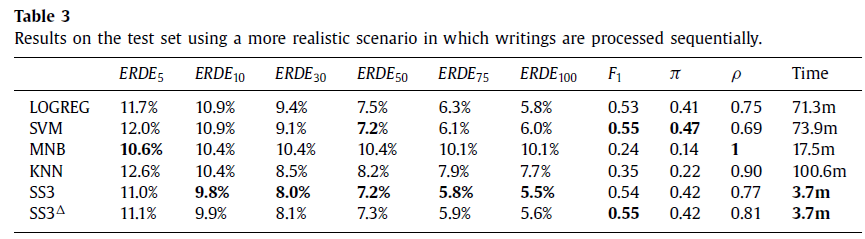
首先做了chunk-by-chunk增量式分类实验。将一个用户按时间序排列的推文按照固定批大小切分后依次输入模型,然后比较评估模型的ERD能力,发现使用策略一进行早期分类的模型SS3在中取得了最好的结果,而使用策略二进行早期分类的模型在中取得了最好的结果。而不管使用何种策略,本文提出的模型在和上的评估结果均优于eRisk2017中提出的所有模型。
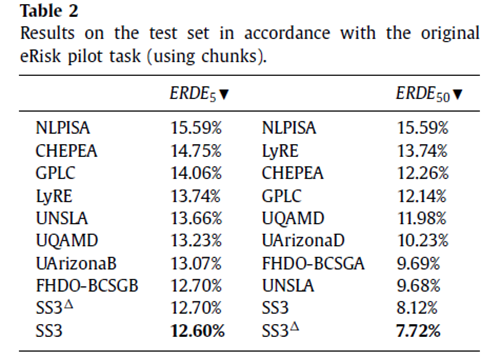
然后做了post-by-post增量式分类实验。这个实验与chunk-by-chunk实验唯一的区别是用户的推文是一条条输入模型的。由于eRisk2017中没有设置这个实验,所以本文将实验结果和现有的一些经典机器学习算法进行对比,发现本文提出的SS3模型在ERD评估时表现总是最佳。
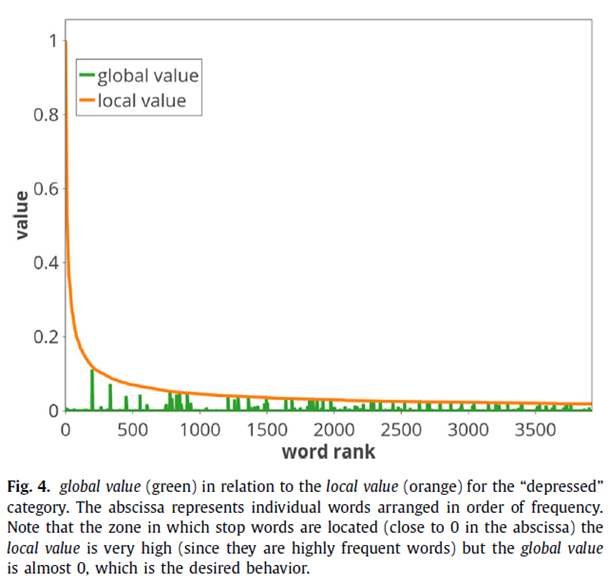
接着,作者对提出的词的global value提取机制进行了有效性分析,发现停用词的global value几近于0,而中频但具有区分度的词会被赋一个较大的gv值。
最后,作者分析了本文提出的方法是如何执行早期分类的,并针对本文提出的两种早期分类策略导致的错误分类分别进行了样例分析。
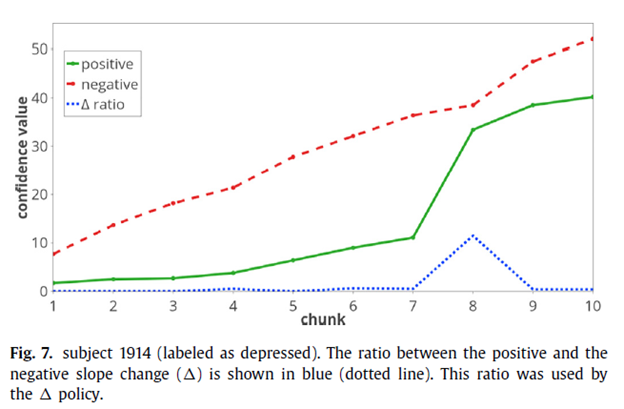
由下图可以看出,通过对本文提出的框架的分类时产生的中间结果进行时间线分析能很好的找到用户含有抑郁用语的推文,而对决策的中间过程进行分析则可以从一条含有抑郁用语的推文里找到抑郁词。由此知本框架具有较强的解释性。


9 本文不足
不足:
- 受限于数据集,无法加入其他的信息以提升检测效果
- 由于知识受限,没有对实验结果进行临床医学上的解释
- 由于模型预测的置信值是增量式增加的,框架无法反应用户的情绪变化或者用户的特定行为
- 模型层面,仅将词作为基本块,没有研究更高级别句子和段落,可能会遗漏一些表达;增量操作可以设计的更为精妙;可以设计更有效的早期停止策略
改进:
- 构建更全面且适合本研究的数据集
- 提取用户每个推文的症状信息
- 学习用户多个症状历史的时间序列
- 模型层面利用预训练句嵌入模型提取嵌入
10 代码和数据集地址
代码地址:
https://github.com/sergioburdisso/pyss3?utm_source=catalyzex.com
数据集地址(CLEF eRisk2017 数据集,未找到网址)