1 原文作者
Yingjie Li (Computer Science Department University of Illinois at Chicago)
Cornelia Caragea (Computer Science Department University of Illinois at Chicago)
2 论文来源
Annual Meeting of the Association for Computational Linguistics (ACL/IJCNLP (Findings) 2021: 2320-2326)
3 论文地址
https://aclanthology.org/2021.findings-acl.204.pdf
4 论文简介
目标立场检测旨在识别同一文本中一对不同目标的立场,通常,每个数据集有多个目标对。现有的工作通常针对每个目标对训练一个模型。然而,他们不能学习目标特定的表示,并倾向于过度拟合。本文提出了一种多任务学习环境下的训练策略,即在所有目标对上训练一个模型,帮助模型学习更多的通用表示,并缓解过拟合问题。此外,为了提取更准确的特定目标表示,我们提出了一个多任务学习网络,它可以与立场一致性检测任务联合训练我们的模型,该任务旨在识别成对文本中立场之间的一致和不一致。实验结果表明,本文提出的模型在宏观平均f1得分上比表现最好的基线高出12.39%。
5 解决问题
当前有了对于MTSD的一些研究,但是大部分采取的策略是针对一个目标对专门训练一个模型,然后在该模型上进行测试。这样地模型既不能学习目标特定地表示,并且存在过拟合的问题。
6 本文贡献
本文主要贡献及创新点在于:
- 提出了合并策略。
- 使用了多任务学习框架,提出了立场一致性检测任务,辅助训练模型。
7 论文方法
模型框架就是在Bert模型的基础上加了多任务学习框架,两个任务分别为立场检测任务和立场一致性检测任务。“合并”策略就体现在在一个模型上进行训练。
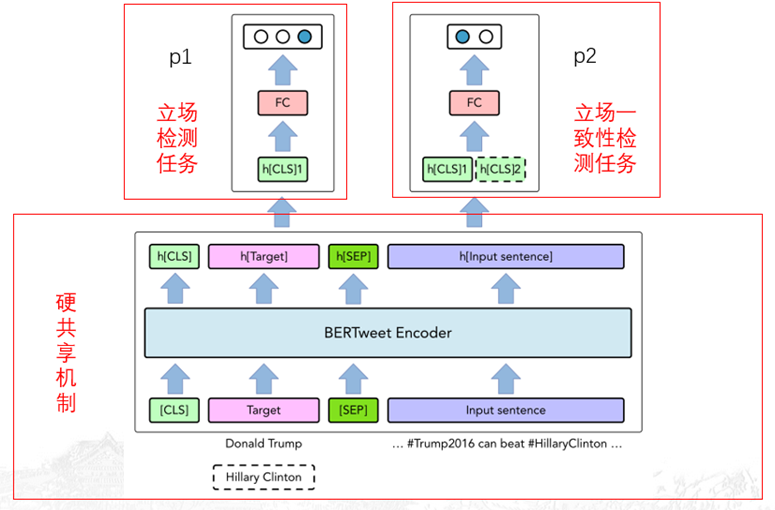
对于多任务学习的框架来说,采用的是参数的硬共享机制(底层共享参数,任务层有特定参数)。而使用的bert模型是对已有的BERTweet模型的微调,原来的模型是在850M的推文上训练好的模型,微调过程为batchsize为32,最大序列长度为128,使用adamW优化器,学习率为2e-5。
整个模型的输入是目标t和句子x,根据bert模型的输入规则为[[CLS]t[SEP]x],经过bert模型后得到句子的编码标识h[CLS]1,立场检测任务的内容是根据h[CLS]1得到对目标t的预测(FAN)。立场一致性检测任务是二分类任务,这个任务的目的是为了检测一个句子中对两个目标所表达的立场是否一致。在对目标t1进行立场检测时,将t2作为辅助任务进行输入,得到句子编码h[CLS]2,然后依据h1和h2得到立场一致性任务的预测p2。
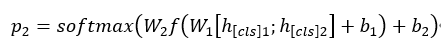
D是MTSD的标记训练数据集,dj是MTSD的小批量, y1和y2分别表示立场检测任务和(dis)协议任务的真实标签。利用交叉熵损失对模型进行训练。L1和L2分别是立场检测任务和合并任务的丢失。损失函数为(超参数α为0.5):
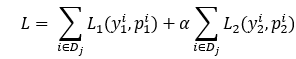
8 实验结果
实验准备:
环境:
数据集:
论文[1](每条tweet都有两个关于两个目标的立场标签,每个标签都有一个值:“FAVOR”、“AGAINST”或“NONE”): Parinaz Sobhani, Saif Mohammad, and Svetlana Kiritchenko. 2016.Detecting stance in tweets and analyzing its interaction with sentiment. InProceedings of the Fifth Joint Conference on Lexical and Computational Semantics, pages 159–169.
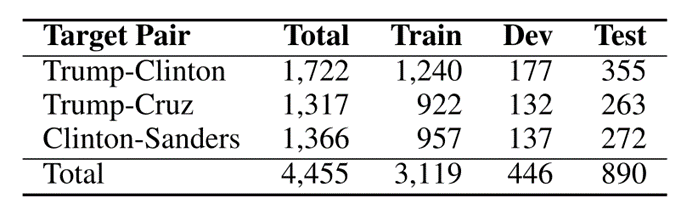
论文[2](对比实验数据集,为了测试“合并”训练策略下无辅助任务的BERTweet模型的泛化能力): Parinaz Sobhani, Saif Mohammad, and Svetlana Kiritchenko. 2016.Detecting stance in tweets and analyzing its interaction with sentiment. InProceedings of the Fifth Joint Conference on Lexical and Computational Semantics, pages 159–169
多目标立场检测实验结果:
1、在ad-hoc中表现良好的模型在合并策略下效果都有大幅度的下降,说明ad-hoc策略过拟合问题相当严重,最严重的是CNN,下降了12%。
2、不论是merged策略还是单独训练模型结果都表明使用微调的Bert和多任务学习框架的f1要高于其他方法。
3、微调的bert模型在采用merged策略时效果提升,表明bert模型能够学习到更多关于目标的通用表示。同样多任务学习框架的模型也是效果有所提升。
4、本文中的方法实验效果对比之前最好的效果提升了12.39%,表明了所提出模型的有效性。
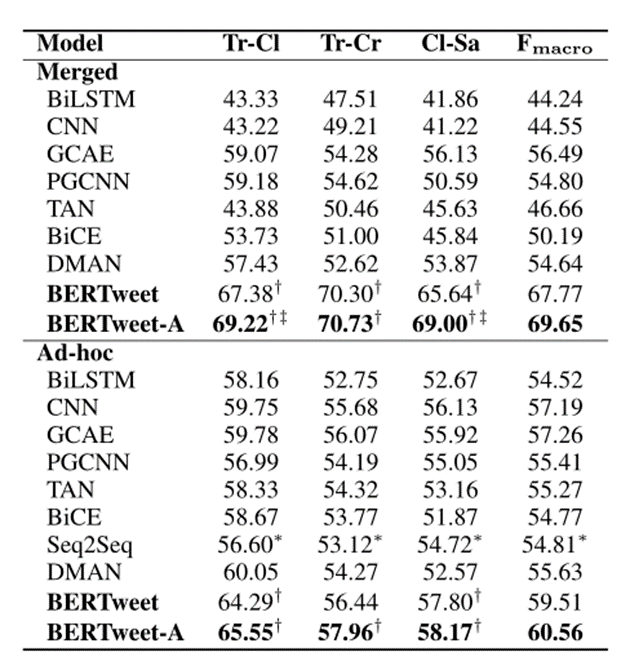
附加实验结果:

结果说明合并训练策略的模型的泛化能力要比单独训练模型的效果好得多。
9 本文不足
- 有些内容没有解释清楚,立场检测任务为多分类任务,但是在最后实验指标时只对favor和against的精度和召回率进行了统计,没有考虑None类型的结果。
- 效果提升12%的描述并不准确,使用合并训练+多任务学习对比使用微调的bert模型进行ad-hoc训练模型效果提升了10%。