论文标题
A Feature Ensemble-based Approach to Malicious Domain Name Identification from Valid DNS Responses
基于特征集成的有效 DNS 响应中的恶意域名识别方法
来源
IJCNN(International Joint Conference on Neural Networks,国际神经网络联合会议) 2020 (CCF-A类会议)
作者
Chen Zhao; Yongzheng Zhang; Yipeng Wang
论文链接
https://ieeexplore.ieee.org/document/9207527
摘要
识别互联网活动中的恶意域名已成为保护互联网用户的有效手段。以往的工作取得了很好的识别效果,但它们高度依赖域名系统(DNS)历史响应和外部情报来源。因此,他们很可能在没有先验情报的条件下无法识别出未知域名。本文课题组提出了一种基于特征集成的识别工具:Glacier,用于从有效的 DNS 响应中识别恶意域名。Glacier 通过在域名字符串中利用两种类型特征来解决上述问题——语言学特征和统计特征:(1)语言特征是由两层双向长短期记忆(BiLSTM)神经网络从域名字符序列中生成向量表征。值得注意的是,本项目对最后一层 BiLSTM 进行了修改,以增强语言特征的表征能力。(2)统计特征是由 6 个人工设计的统计信息,组成表示域名的信息结构,上述结构信息很难被 BiLSTM 神经网络直接学习。因此,将统计特征与语言特征相结合可以提高恶意域名识别的有效性。本项目在一个真实的域名数据集上评估了 Glacier 的识别能力,最佳指标平均准确率为 90.86%,平均 f1 分数达到 84.37%。实验结果表明,在没有任何 DNS 流量数据和未知域名先验域名知识的情况下,Glacier 可以准确识别可解析的恶意域名。
关键词
Domain Name System, Malicious Domain Name, Nerual Language Model, Deep Learning, Cyber Security
问题描述
恶意域名是攻击者进行非法活动,如网络钓鱼、垃圾邮件、恶意软件、僵尸网络攻击常用的攻击工具。识别跟踪来自域名系统(DNS)的恶意域名是保护互联网用户免受网络攻击的有效方法。当前已有不少恶意域名识别工具包括 Notos、Exposure、Seguigo 和 FANCI ,它们在通过追踪 DNS 流量识别恶意域名方面取得了不小成果。但上述工具均基于海量历史 DNS 流量数据或已有情报进行检测,在没有这些先验情报的情况下并不能很好地进行预测或识别工作。为突破上述工具的局限性,本文推出了一种系统:Glacier,该系统能利用域名的字符特征对域名的恶意和非恶意进行分类。
应当重点关注到的是,在实际应用中,由于恶意域名始终存在被屏蔽的风险,恶意域名的攻击者常常需要批量注册域名。在保证域名注册费用比较低和尽可能避免与现有良性域名冲突的条件下,攻击者更喜欢注册费用不昂贵和不太“通俗”的域名。因此,有效和可解析的域名通常存在不可读和不必要情况下很长的特点。
相关工作
学界对于恶意域名识别的研究方法无外乎两个范畴:基于特征方法和基于关系方法。
大多数基于关系的方法会通过域名和该域名其他相关特性构成的二部图对未知域名进行信誉分数评估。文章介绍了三种现有的基于关系方法的识别工具。
- B. Rahbarinia 等人推出的 Seguigo 是一种基于客户和查询域名之间的二部图进行恶意域名识别的系统,该系统通过使用二部图对域名节点进行了域名活跃特征和 IP 大量出现特征进行属性划分和分类;
- I. Khalil 等人则开发出了一种基于域名加权图的恶意域名推测系统。该系统从已知域名中对外传递域名信誉分数,加权图中的结点表示域名,结点间的权重则由他们之间共同解析的 IP 地址数量决定;
- H. Tran 等人推出了一种基于域名和 IP 地址拓扑图的检测方法,他们使用了信念传播算法用以计算域名的恶意分数。
基于特征的方法则会通过从恶意域名和从 DNS 流量当中得到的非恶意域名间的字符区别进行特征提取。文章介绍了四种采用上述方法进行域名识别的工具。
- M. Antonakakis 等人开发的 Notos 系统会监控客户和域名递归解析器间的 DNS 流量。该系统根据域名的 IP 地址特征、相关域名特征以及目标域名和其 IP 地址在恶意样本和黑名单中出现的情况对域名进行信誉评分;
- L. Bilge 等人开发的 Exposure 系统是采用基于时间特征、DNS 应答特征、TTL 值特征等基于域名解析行为的恶意域名识别系统用以描绘恶意样本;
- M. Antonakakis 还开发出了另一种名为 Kopis 的检测系统,该系统工作于递归服务器所属层之上,能使用三种类型的统计特征——请求方多样性(requester diversity)、请求方形象(requester profile)和待解析 IP 信誉(resolved-IPs reputatiopn)检测恶意域名;
- M. Weber 等人设计出了一种基于待解析域名 IP 特征、注册信息和在 DNS 跟踪中出现的相关特征的聚类方法来扩展现有公用域名黑名单的方法。
本文贡献
- 提出一种全新且轻量级的基于恶意域名和非恶意域名字符构成特征的恶意域名识别系统—— Glacier。该系统可以在不需要海量 DNS 历史数据或其他外部情报来源的基础上,通过较低开销向用户提醒可能存在的恶意域名。
- 提出特征集成的方法用以提高神经网络的识别效果。该系统将神经网络生成的特征表示与人工设计的统计特征相结合,在此基础上 Glacier 可以了解到更多神经网络难以直接学习的信息。通过这种方法,可以在不使网络结构复杂化和调整大量可学习参数的基础上提高系统最终的识别性能。
- 文章在一个真实的域名数据集上评估了 Glacier。平均准确率达到了 90.86%,平均 f1 分数为 0.8437,优于纯 BiLSTM 网络,准确率相对误差减少了 3.18%,平均 f1 评分相对误差减少了 2.74%。实验结果表明该方法对可解析恶意域名的识别精度较高,且在相同参数规模下特征集成方法获得了优于纯神经网络方法的结果。
研究方法
一、系统整体架构
Glacier 系统包含两个工作部分:训练部分和识别部分。整个系统包括五个关键组件:域名处理器(Domain Name Processor)、统计特征提取器(Statistical Feature Generator)、语言特征提取器(Linguistical Feature Generator)、分类器(Classifier)和分类器训练器(Classifier Trainer)。

(1)训练部分:
训练阶段的输入数据集是由已知域名 D 及其对应的标签 L 组成的 “Ground Truth”,域名 D 被输入到语言特征提取器和统计特征提取器;标签 L 被输入到语言特征提取器和分类器训练器中。
语言特征提取器将域名 D 视为字符序列,生成语言特征 Fl,同时其训练部分将语言特征 Fl 转换为待验证预测 P,并进行调参;
统计特征提取器提取域名 D,计算统计特征 Fs。此后分类器训练器将语言特征 Fl 和统计特征 Fs 串联起来,基于标签 L 训练分类模型。训练阶段的最终输出是语言特征提取器的参数和分类模型。
(2)识别部分:
识别阶段的输入是实时 DNS 流量。由域名处理器从 DNS 追踪到的信息中提取待检测域名 D,并将其发送至两种特征提取器当中。后面的特征提取步骤和训练部分类似,只是这里的输出结果为该未知域名的属性(恶意或非恶意)。
二、特征表示方法
本系统进行识别时利用两类特征:语言学特征和人工设计的统计特征。语言学特征是由基于 BiLSTM 神经网络生成的域名向量表示,同时协同人工设计的统计特征,获取神经网络无法直接学习到的域名结构信息。
(1)语言学特征:
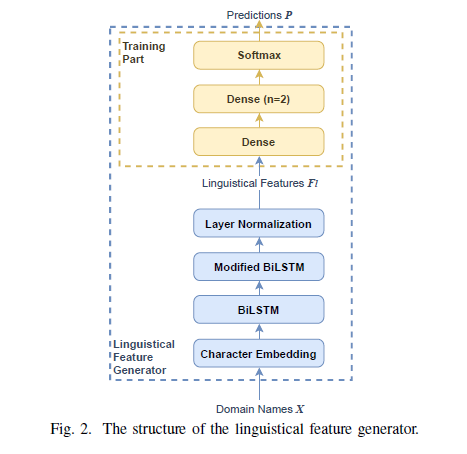
本系统特征提取核心部分在上述图中字符嵌入层及 Modified BiLSTM 层中。
①字符嵌入层:
一个有效域名中语义成分情况将很复杂。例如,域名 researchgatee.net 包含两个词 research 和 gate;域名 54569.com 在最左边的标签中没有重要的语义成分。因此,使用 n-gram 和 word2vec 等方法在标签或语义组件级别表示域名成本高且效率低。为了表示域名,本文选择求助于基于字符的方法。
②Modified BiLSTM 层:
本项目还在最后一个 BiLSTM 层的结构中进行了修改以增强语言特征的表达能力。通常 BiLSTM 层通过舍弃除最后一个以外的时间步的结果,对可变长度的序列生成固定长度的表示。这种方法会丢失一部分的时间步长信息,因为一个 LSTM 单元的记忆步长很短。为此,本系统设计了一个 multi-to-fixed 算法那来替代上述丢弃。multi-to-fixed 操作将计算 LSTM 单元生成的结果的平均值和最大值,并保留最后一个时间步的结果。
multi-to-fixed 的具体算法如下:

(2)统计特征:
在恶意域名识别工作中域名结构信息如长度、数字比例等具有显著重要性。本课题中项目组手工设计了六个统计特征用以总结域名的结构信息,包括域名长度、特殊字符数量、信息熵等 6 种指标。具体如下:
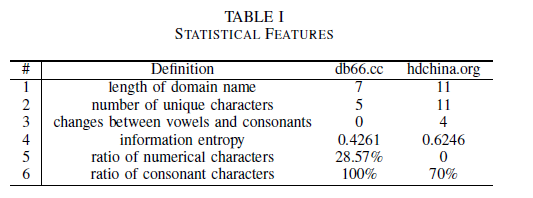
以域名 db66.cc 域名为例,其统计特征元组为 {7, 5, 0, 0.4261, 0.2857, 1.00}。
三、课题实验结果
该课题实验结果表示相比于该种特征集成方法,决策树分类器和 AdaBoost 分类器在准确性和 f1 得分方面都不如该方法;Bagging 分类器在准确性上比该方法差,在 f1 得分上优于该方法。随机森林分类器和 extra-tree 分类器在准确性和 f1 评分方面都优于该方法。实验结果表明,Bagging 分类器、随机森林分类器和 extra-tree 分类器的集成策略能够提高分类能力。该方法的平均准确率在 84.94% 到 90.80% 之间。
结论
本文提出了一种基于特征集成的恶意域名识别方法,并形成系统——Glacier。该系统利用从域名字符串中提取出的两个特征:表示域名字符的语言学特征和表示域名结构信息的统计特征进行模型建立,利用统计特征来补偿仅使用语言学特征无法学习到的结构信息。同时 Glacier 对 BiLSTM 神经网络进行了改进,提出了 multi-to-fixed 算法,增强了语言特征的表达能力。实验结果表明 Glacier 能够准确识别真实 DNS 响应中的恶意域名。
一些补充
1.IP 信誉
IP信誉(IP reputation)是威胁情报领域的具体用例,是识别发送非法请求IP地址的高效工具,使用 IP 信誉列表可以拒绝来自信誉不佳的 IP 的请求。一般而言,IP 信誉可能包括以下几类信息:
- 恶意 IP 地址
- 匿名代理
- TOR 网络
- IP 地理位置
- 网络钓鱼网址
- 垃圾评论者
- 网络攻击 IPs
- 扫描程序 IP
- Windows 漏洞利用
- 病毒感染的个人计算机
- 自动化僵尸网络
- 网络钓鱼代理
2.信念传播算法
一种消息传递算法,用于在图模型(如贝叶斯网络和马尔可夫随机场)上执行推断。该算法计算每个未观察到结点(或变量)的边缘分布。通常用于人工智能和信息论,并在许多其他领域得到广泛应用包括低密度奇偶校验码、涡轮码、自由能近似和可满足性(来源于 wiki,Belief propagation)。