阅读笔记作者:骆子悦
1 原文作者
宾夕法尼亚州立大学:
- Thai Le
- Jooyoung Lee
- Dongwon Lee
雅虎研究:
- Kevin Yen
- Yifan Hu
2 论文来源
Findings of the Association for Computational Linguistics: ACL 2022
3 论文地址
4 论文简介
(1)文本中的对抗攻击
- 在文本领域,给定文本x,基于字符的对抗攻击通过操纵x中不同单词的字符,从原始文本x中生成对抗文本x*,使得x的一些属性得以保留,受干扰的文本x*可以欺骗ML模型进行错误的预测。
1、替换/交换/添加/删除附近的字符
2、视觉上相似的字符
3、不同的编码字符

(2)演绎机器生成的文本扰动
- 存在的攻击手段-演绎方式(deductive method)
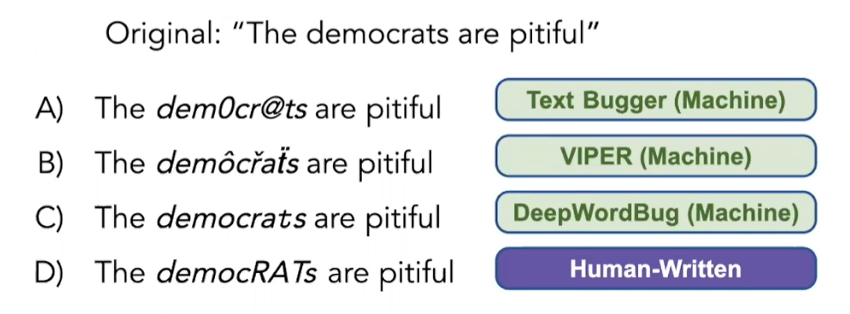
1、TextBugger
2、VIPER
3、DeepWordBug
5 解决问题
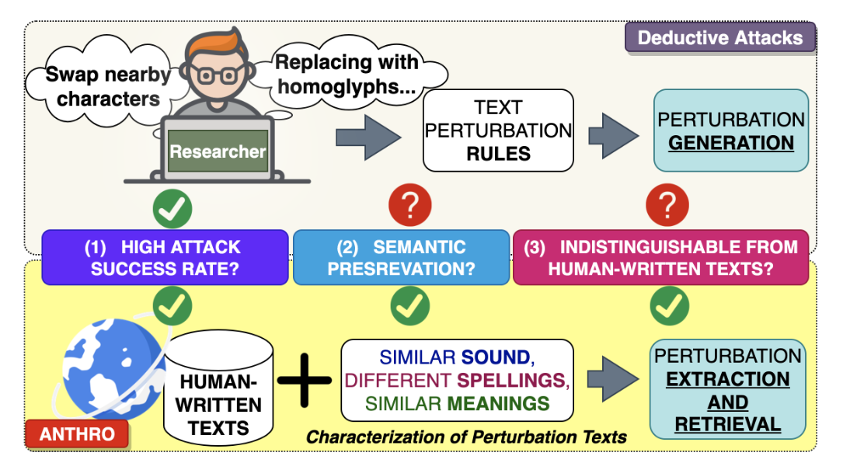
- 生成对抗样本目标:
(1)攻击性能,通过翻转目标模型的预测能力来衡量;
(2)语义保留,通过保留原文的意义的能力来衡量;
(3)隐蔽性,通过不太可能被检测为机器操作,并被防御系统或人类审查员移除来衡量。
- 目前基于字符的对抗样本生成方法只能够满足攻击性能的要求。生成既保留原文意义又与人类书写文本不可区分的扰动是一项非常重要但又具有挑战性的任务。
6 本文贡献
- ANTHRO是第一个在线提取含噪的人类书写文本或文本扰动的工作。
- ANTHRO将”从基于演绎的攻击转移到基于数据驱动的攻击”,这一创新方向对于对抗性自然语言处理领域以及其他需要理解在线产生的现实嘈杂用户生成文本的自然语言处理任务都有益处。
- ANTHRO使得BERT模型能够比流行的Perspective API更好地理解嘈杂的人工写作文本。
- ANTHRO在在线语言使用和网民如何利用不同形式的扰动来规避在这个人工智能新时代的审查方面开辟了新的方向。
7 论文方法
(1)人类书写描述
(1) 用大写和改变词的部分来强调歪曲的意思;
“democrats“→“democRATs”,“republicans”→“republiCUNTs
(2) 用连字符连接单词;
“depression”→“de-pres-sion”
(3) 用表情符号来强调意思
“shit”→“sh💩t”
(4) 重复特定的字符
“dirty”→“diiirty”, “porn”→“pooorn”
(5) 插入读音相似的字符
“nigger”→“nighger”
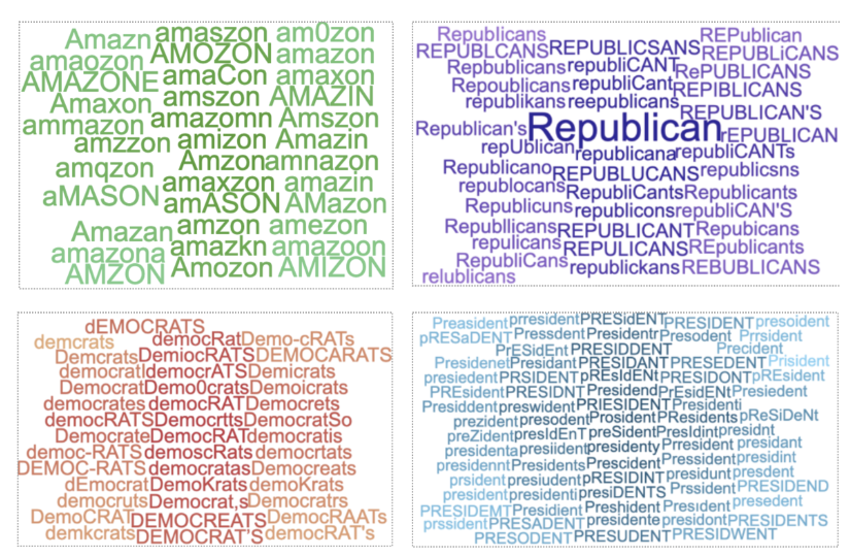
(2)SMS-Similar Sound, Similar Meaning, Different Spelling
- SMS:Similar Sound, Similar Meaning, Different Spelling
- 目标:找到满足SMS(相似的声音,相似的意思,不同的拼写)属性的文本
- SMS特征包含了以往对抗攻击(如TextBugger(’hello’与’he11o’的发音相似))所研究的扰动的”视觉相似”属性的子集。
(3)表征文本扰动
- SOUNDEX++:即能识别视觉相似的字符(“l”→“1″, “a”→“@” and “O”→“0″),又能在不同的层级k上对单词的声音进行编码。在k=0时,通过固定第一个字符,删除所有的元音,并将剩下的字符按照一组预定义的规则一一匹配到一个数字,例如,’B’,’F’→1,’D’,’T’→3。在k≥1时,SOUNDEX++固定前k+1个字符,并对其余字符进行编码。
- democrat、demokrat、democraaaaat三个单词经过SOUNDEX++都可编码为D526

- 由于SOUNDEX++并不是为了捕捉一个词的语义,同时使用Phonetic参数k和Levenshtein距离d作为近似来衡量两个词之间的语义。
- Levenshtein距离指的是将一个字符串变为另一个字符串需要进行编辑操作(替换、插入、删除)最少的次数
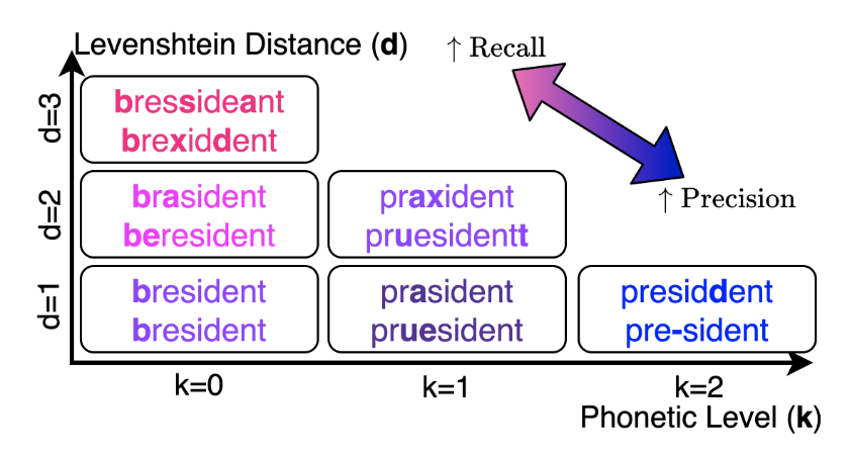
- 在不同的k和d值下,对词“President”提取扰动的精确率和召回率进行权衡。
- 两个词共享同一个SOUNDEX++编码的语音水平(k≥1)越高,并且转换一个词到另一个词的Levenshtein距离d越小,有助于更好地保留原义,即人类越有可能将它们与词义联系起来。
(4)从现实生活文本中挖掘文本扰动
- 从9个不同的数据集中收集了一个由网民撰写的超过18M个句子的大型语料库D,包括攻击性文本,如仇恨言论,敏感搜索查询等。
- 对于每个k<K,规划不同的哈希表
,将唯一的SOUNDEX++编码c映射到一组与其匹配的唯一区分大小写的令牌,这些令牌共享相同的编码c。
找到所有听起来与“election”相似且Levenshtein编辑距离<5的令牌”

(5)ANTHRO攻击
- 使用与其他黑盒攻击相同的迭代机制
- 采用最能降低预测概率f(x)在正确标签上的扰动来替换句子x中最脆弱的单词
- 该过程在TextBugger中的Score函数进行评估。
- 与其他方法不同的是,ANTHRO包容性地从
中捕获的人类书写文本中提取扰动。

8 实验结果
(1)评估方面
- 攻击性能
- 语义保持
- 类人性来评估,即攻击消息被发现为机器生成的可能性。
(2)攻击性能
- 目标分类器:BERT-大小写不敏感和RoBERTa-大小写敏感
- 数据集:
- 有毒评论(TC)数据集
- 仇恨言论(HS)数据集
- 网络欺凌文本(CB)数据集
- 基线模型:
- TextBugger
- VIPER
- DeepWordBug
- 标准设置:
- 重音归一化(A)
- 同形字归一化(H),它将非英语口音和同形字转换成其对应的ascii字符
- 扰动归一化(P),它使用SOTA拼写错误校正模型Neuspell对潜在的基于字符的扰动进行归一化
- 实验结果

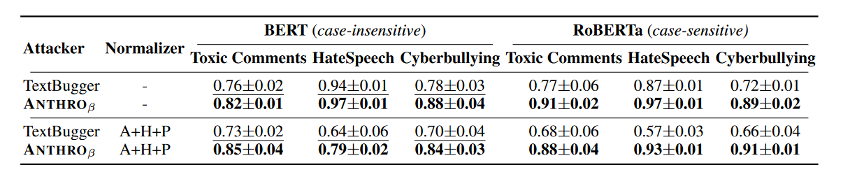
- ANTHRO和TextBugger的表现最好。与TextBugger相比,ANTHRO对大小写敏感,在RoBERTa上表现明显更好,在BERT上具有竞争力。
- ANTHRO在实际应用中更有优势,因为许多流行的商业API服务(流行的Perspective API , Google的情感分析和文本分类API)都是大小写敏感的。
- VIPER在没有Normalizer中RoBERTa中表现得最好;
(2)人工测评
(1)两种假设–给定由任意一种攻击产生的原始句子x及其对抗文本x*;
:由ANTHRO生成的x*比由TextBugger生成的更好地保留了x的原始含义
:由ANTHRO生成的x*比由TextBugger生成的更有可能被视为人类编写的文本(而不是机器)。
(2)测试流程
- 从TC数据集的测试集中抽取的200个样本上生成了针对BERT模型的对抗文本。
- 将一对文本,一个由ANTHRO生成,一个由TextBugger生成,连同原句一起呈现给人类。
- 要求他们选择(1)哪个文本更好地保留了原句的意思,(2)哪个文本更有可能是人写的


(3)实验结果

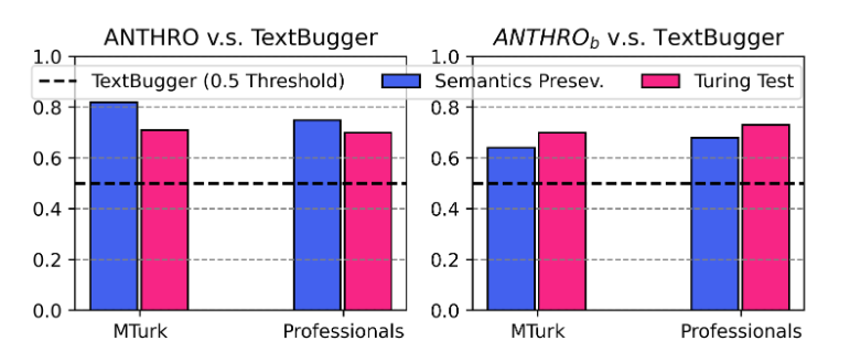
由左图可看出:ANTHRO生成的对抗文本比TextBugger生成的对抗文本在保留原始语义方面要好得多,在与人类书写文本的相似度方面也要好得多

- ANTHRO的干扰被认为与真正的打字错误相似,而且更容易理解。它们也能更好地保留意义和声音。
(4)攻击实验
- 研究了从现实提取的扰动是否有助于改进演绎的TextBugger攻击。在算法1中中引入了
,同时考虑了来自ANRHRO和TextBugger的扰动;

在BERT和RoBERTa上表现出了一致的优越性。
- 由右图可以看出:
提高了TextBugger的Atk%,语义保存和人类相似性得分,平均分别提高了8%,32%和42%。
- TextBugger产生的不合理的扰动就会对句子的意思产生不利影响,
(5)
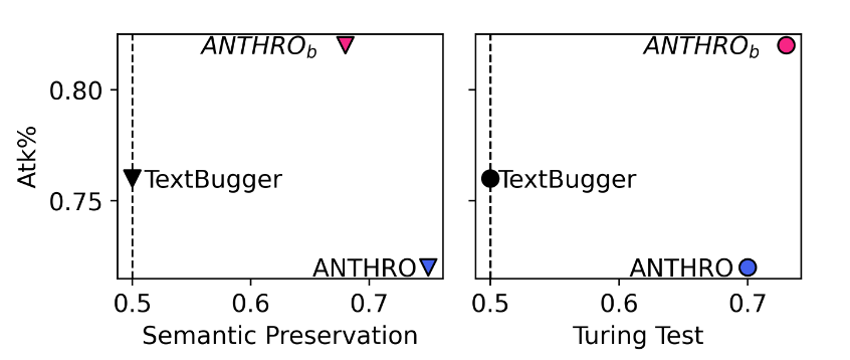
- 现实文本扰动有助于提高语义保存、人类相似性和攻击成功率。
(6)防御
- 两种防御方法:
- Sound-Invariant Model(SOUNDCNN):当防御者无法访问攻击者学习到的
时,防御者训练一个通用模型,该模型编码文本的语音特征,而不是拼写。在嵌入层之上训练一个CNN模型,用于对句子中每个令牌进行离散的SOUNDEX++编码;
- 对抗训练(Adversarial Training,ADV.TRAIN):为了克服对
)提取现实扰动。并使用它们来增加训练样本,即通过自我攻击以1:1的比例来微调一个更鲁棒的BERT模型。
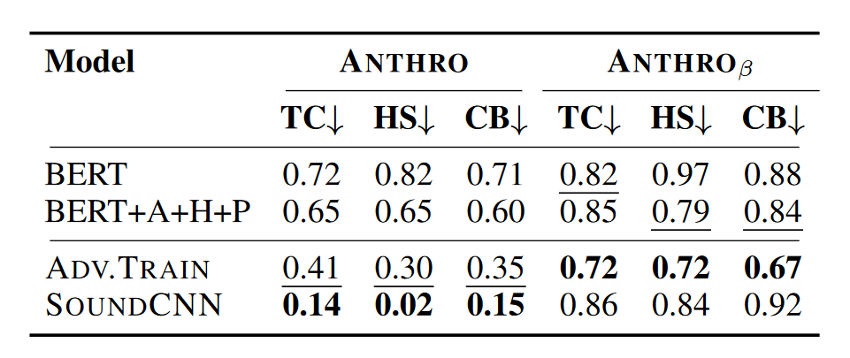
- BERT在防御ANTHRO方面优于RoBERTa;
- ADV.TRAIN在对抗
攻击表现更好;
- 由于SOUNDCNN是严格基于语音特征的,因此当选择TextBugger的扰动时,SOUNDCNN很容易受到
(6)攻击Perspective API
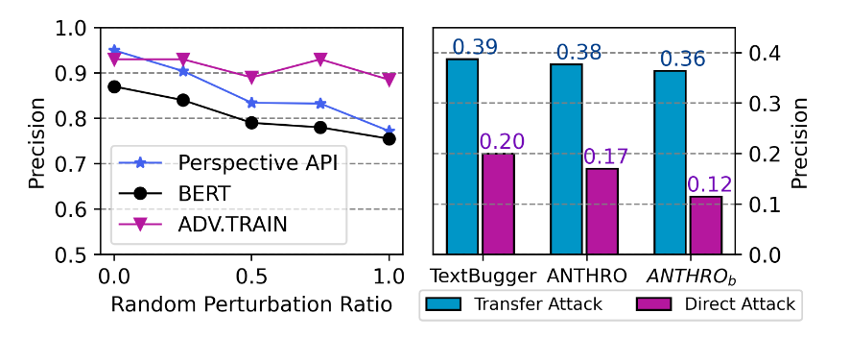
- 与自微调的BERT分类器相比,API提供了更好的性能,但当句子的25%-50%被人为扰动随机干扰时,其精度迅速从0.95下降到0.9和0.82。
- ADV.TRAIN模型在相同的设置下实现了相当一致的精度。
- ANTHRO不仅是一种强大而现实的攻击,而且可以在实践中帮助开发更健壮的文本分类器。
(7)超出攻击性文本
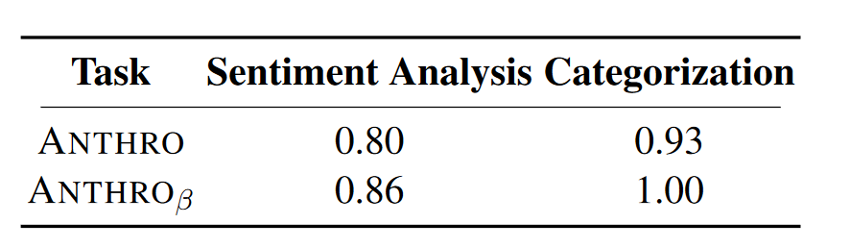
- ANTHRO学习非滥用英语单词的扰动-例如,hilarious->Hi-Larious,shot->sh·t
- ANTHRO和
在愚弄Google Cloud的情感分析和文本分类API上分别达到了80%、86%和90%、100%的攻击率
(8)其它讨论与分析
- 计算复杂性:给定一个词w和k,d,ANTHRO通过等式检索出扰动候选列表有
,其中
为w的长度,
为
中共享相同SOUNDEX++编码的最大令牌集合的大小。由于
。
- 拼写错误纠正词的限制:SOTA NeuSpell依赖于固定的常见拼写字典,或者由字符随机排列生成的合成拼写。此外,由于迭代攻击机制,即一个句子中的每个令牌被许多候选替换,直到正确标签的预测概率下降,ANTHRO只需要一个NeuSpell没有检测到的单个好的扰动就可以成功替换。因此,ANTHRO不仅可以通过拼写来构造扰动,还可以通过声音来构造扰动,从而挖掘出可以绕过Neu Spell的扰动
- ANRHRO的局限性:扰动候选项检索操作的计算复杂性比其他方法更高。这可能会延长运行时间,特别是在攻击长文档时。然而,可以通过存储所有具有给定k、d的常用攻击性和非攻击性英文单词的扰动来克服这一问题。
9 本文不足
- SOUNDER++算法是针对英文文本设计的,在其他语言中可能并不适用。
- 扰动候选项检索操作的计算复杂性比其他方法太高,可能会延长程序运行时间。
- 与TextBugger相比,ANTHRO在BERT上并没有很出色。
- 攻击的目标模型不是很多。
- 参考的文献的年限相对不是很近。
10 开源代码
github.com/lethaiq/ perturbations-in-the-wild.