BERT Learns to Teach: Knowledge Distillation with Meta Learning
阅读笔记作者:翦逸飞
1 原文作者
斯坦福大学:
- Wangchunshu Zhou (Stanford University)
加州大学圣地亚哥分校:
- Canwen Xu (University of California, San Diego)
- Julian McAuley (University of California, San Diego)
2 论文来源
自然语言处理顶会(CCF-A):
- Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL’2022)
3 论文地址
- https://aclanthology.org/2022.acl-long.485/
4 论文简介
(1)知识蒸馏的含义
- 知识:模型训练过程中学到的参数值
- 蒸馏:将知识从复杂的大模型迁移到适合部署的小模型
(2)研究知识蒸馏的原因
- 超大型深度神经网络的流行引发了人们对于模型高效性、环保性的反思
- 超大型模型难以部署或应用于一部分对响应速度要求高的轻型领域
(3)知识蒸馏的模式(Student-Teacher)
- 将复杂且占用空间大的模型作为Teacher
- 将简单且占用空间小的模型作为Student
- 用Teacher来辅助Student的训练
- 让Student来学习Teacher的执行任务能力
- 不关注Teacher大模型的能力,真正部署上线执行任务的是Student小模型
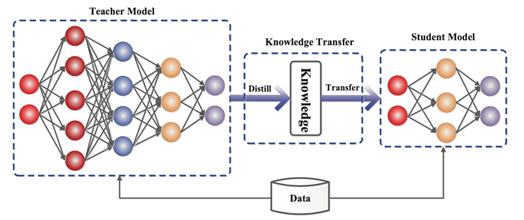
l 上半部分:让Student的输出分布尽可能拟合Teacher的输出分布(蒸馏学习)
l 下半部分:通过学习正确的标签,从而减少Teacher中的错误知识被蒸馏到Student中(机器学习)
l 上半部分的蒸馏损失与下半部分的学生损失共同构成整体损失
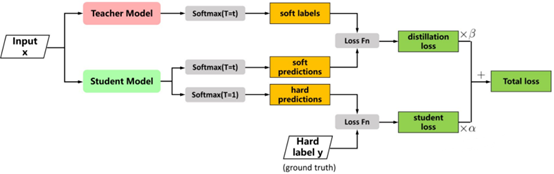
l 元学习(Meta-Learning)通常被理解为“学会学习(Learning-to-Learn)”,指的是在多个学习阶段中改进学习算法的过程
l 元学习包含一个双层优化过程,与普通的机器学习任务的区别在于:内部学习者(Inner-learner, Student)为元学习者(Meta-learner, Teacher)的优化提供反馈,即Teacher不仅负责传授Student知识,还得在这个过程中不断提升自己的教学能力
5 解决问题
- Teacher不知道Student学习的情况:在传统的知识蒸馏中,Student被动地接受Teacher的知识,而Teacher无法察觉Student的学习能力和表现
- Teacher在知识蒸馏的过程中未被优化:对于一个经典的蒸馏过程,Teacher往往作为一个固定的模型,其知识不会改变;以往的工作涉及到训练Teacher优化自身的推理性能,而未研究Teacher如何才能更好地把知识传授给Student
6 本文贡献
(1)总体贡献
提出了一个基于元学习思想来进行知识蒸馏的“通用”框架——MetaDistil
(2)思想上的创新与贡献
- 试点更新(Pilot Update):使得Teacher与Student在训练的过程中“对齐(align)”
- 学会教学(Learning to Teach):允许Teacher调整其参数,提升自身的教学能力,从而更好地将知识传授给Student
7 论文方法
(1)算法伪代码

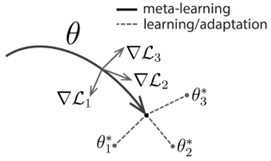
l 第2步:将S’ 视为关于Teacher的参数(T)的函数,进行第二轮知识蒸馏,实现对T的更新【测试Teacher的教学效果,并改进】
l 第3步:在得到更新后的T后,用S替换S’,进行第三轮知识蒸馏,实现对S的更新【让改进后的Teacher来教真正的Student】
8 实验结果
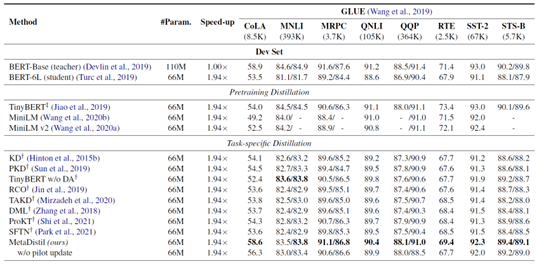
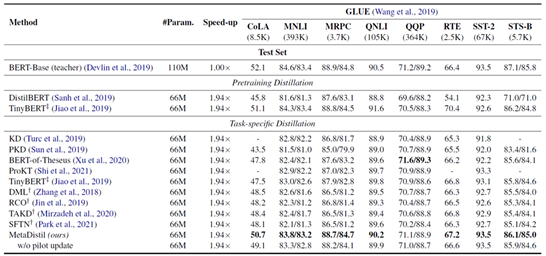
(1)数据集
l GLUE数据集(自然语言理解的基准数据集)的一部分
l 在线评估榜单:https://gluebenchmark.com/
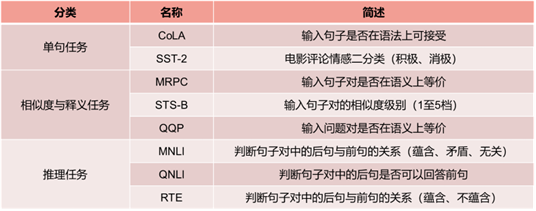
验证集
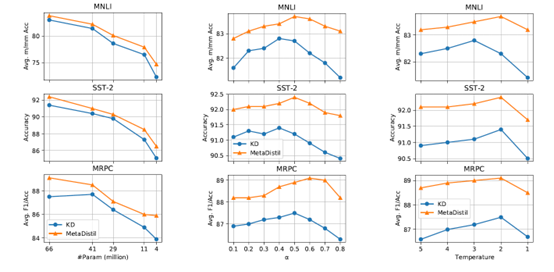
(3)超参数敏感性实验
- Student参数量Param:参数量越大性能越好
- Student损失权重α:权重接近0.5时性能最佳
- 知识蒸馏的温度T:温度为2时性能最佳
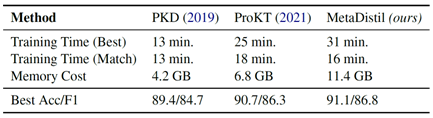
(4)计算资源局限性实验
- Training Time (Best)指的是每个方法达到其自身最佳性能时所消耗的时间
- Training Time (Match)指的是每个方法达到PKD的最佳性能时所消耗的时间
- Best Acc/F1所展示的数据为MRPC数据集(GLUE数据集的一个语料库)上验证集的结果
(5)不同的压缩比实验
蒸馏BERT-base到4-layer BERT(110M → 52M)


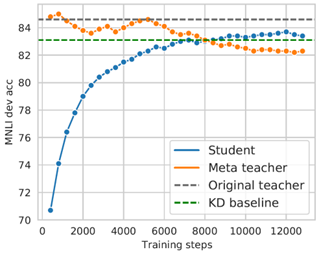
(6)蒸馏动力学实验
- 展示的数据为MNLI数据集(GLUE数据集的一个语料库)上验证集的结果
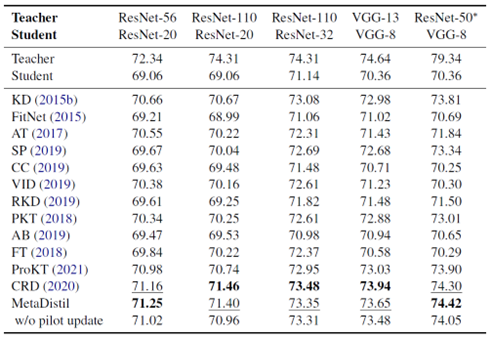
(7)计算机视觉领域模型对比实验
数据集:CIFAR-100数据集
(8)计算机视觉领域蒸馏策略对比实验
- Dynamic:MetaDistil
- Static:传统知识蒸馏
- Static, Cross:交叉教学
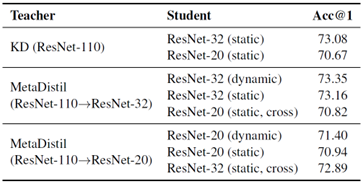
- 结论:MetaDistil的动态教学策略优于传统的静态知识蒸馏方法;MetaDistil培养的Teacher会根据特定的Student优化自身教学能力
9 本文不足
- 知识蒸馏的意义就在于牺牲执行任务能力来实现高效与环保,而MetaDistil既没有比传统知识蒸馏方法高效,其培养的Student也没有比原始的Teacher表现更好,有一点违背知识蒸馏的初衷
- 压缩识别样例(Compression Identified Exemplars,CIE)问题:模型压缩方法的通病,指整体的准确性较高,但在一小部分样本上存在不成比例的高错误率
10 代码和数据集地址