1 原文作者
Fabian Yamaguchi , Nico Golde , Daniel Arp and Konrad Rieck
Institution: University of Gottingen (Germany) Qualcomm Research (Germany)
Research Direction : Vulnerabilities; Static Analysis; Graph Databases
2 论文来源
2014 IEEE Symposium on Security and Privacy
3 论文地址
https://ieeexplore.ieee.org/abstract/document/6956589
4 论文简介
4.1 研究背景
软件漏洞的发现是一个经典但极具挑战性的安全问题。由于一个程序无法识别另一个程序的非平凡属性,查找软件漏 洞的一般问题是不可判定的。因此,目前发现安全漏洞的方法要么局限于特定类型的漏洞,要么建立在繁琐的手工审计之上。特别是,保护大型软件项目(如操作系统内核)的安全类似于一项艰巨的任务,因为单个缺陷可能会破坏整个 代码库的安全性。尽管在整个软件领域中重复出现的某些类型的漏洞存在很长时间,例如缓冲区溢出和格式字符串漏洞, 但如果没有重要的专家知识,自动检测它们在特定软件项目中的具体体现通常仍然是不可能的。
4.2 研究内容
本文提出了一种挖掘大量源代码漏洞的新方法。本文的方法将程序分析的经典概念
与图形挖掘领域的最新发展相结合。
4.3 研究结论
本文 通过引入一种称为代码属性图的新的源代码表示来满足这一需求。该图在联合数据结构中结合 了抽象语法树、控制流图和程序依赖图的特性。通过对代码的全面了解,本文可以使用图形遍历为常见漏洞的模板建立优雅的模型。与数据库中的查询类似,图遍历通过代码属性图并检查代码结构、控制流以及与每个节点关联的数据依赖 关系。通过这种对不同代码属性的联合访问,可以为几种类型的缺陷制作简明的模板,从而帮助审计大量代码中的漏洞。
5 解决问题
本文解决了传统源码审计无法充分地对程序源代码的特征信息进行建模,并且无法有效捕捉关键特征信息的问题,提高了检测准确度。
6 本文贡献
•介绍了一种新的源代码表示方法,它将抽象语法树、控制流图和程序依赖图的特性结合在一个联合数据结构中。
•表明常见类型的漏洞可以优雅地建模为代码属性图的遍历,并产生有效的检测模板。遍历漏洞类型。
•证明通过将代码属性图导入图形数据库,可以在大型代码库(如 Linux 内核)上高效地执行遍历。
7 论文方法
本文提出的代码表征结构“代码属性图(Code property graph)”由三种代码表征组成:抽象语法树,控制流图,程序依赖图。
三种代码表征基本结构如下:

图7-1 示例代码片段
7.1 组成部分
A.抽象语法树(AST)
抽象语法树通常是编译器的代码解析器生成的第一个中间表示形式,因此构成了生成许多其他代码表示形式的基础。
这些树忠实地编码语句和表达式如何嵌套以生成程序。然而,与解析树不同的是,抽象语法树不再代表用于表示程序的 具体语法。例如,在 C 语言中,逗号分隔的声明列表通常会生成与两个连续声明相同的抽象语法树。
抽象语法树是有序树,其中内部节点表示运算符(例如,加法或赋值),叶节点对应于操作数(例如,常量或标识 符)。举个例子,考虑图7-2,它显示了图7-1中给出的代码示例的抽象语法树。虽然抽象语法树非常适合于简单的代码转换,并已被用于识别语义相似的代码,但它们不适用于更复杂的代码分析,例如检测死代码或未初始化的变量。
这种缺陷的原因是,这种代码表示形式既不能使控制流也不能使数据依赖关系显式化。
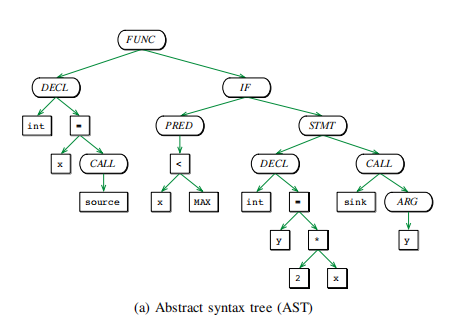
图7-2 抽象语法树示例
B.控制流图(CFG)
控制流图明确描述了代码语句的执行顺序以及特定执行路径需要满足的条件。为此,语句和谓词由节点表示,节点通过有向边连接,以指示控制权的转移。虽然这些边不需要像抽象语法树那样进行排序,但有必要为每个边指定 true、 false 。特别是,语句节点有一个标记为的输出边,而谓词节点有两个对应于谓词的真或假计算的输出边。控制流图可 以通过两步过程从抽象语法树构建:首先,考虑结构化控制语句(例如 if、while、for)来构建初步的控制流图。其次, 通过额外考虑非结构化控制语句(如 goto、break 和 continue),对初步控制流图进行校正。图7-3显示了图7-1中给出的 代码示例的 CFG。
控制流图已用于安全上下文中的各种应用程序,例如,检测已知恶意应用程序的变体,并指导模糊测试工具。
此外,它们已成为逆向工程中的标准代码表示,以帮助理解程序。然而,当控制流图公开应用程序的控制流时,它们无法提供数据流信息。特别是对于漏洞分析,这意味着无法轻松使用控制流图来识别语句,这些语句处理受攻击者影响的数据。
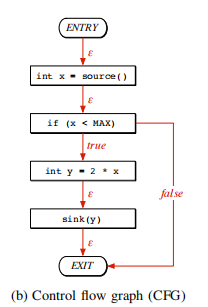
图7-3 控制流图示例
C. 程序依赖图(PDG)
费兰特等人介绍的程序依赖图最初是为了执行程序切片即确定程序中影响指定语句处变量值的所有语句和谓词。程序依赖关系图显式表示语句和谓词之间的依赖关系。
该图使用两种类型的边构造:反映一个变量对另一个变量影响的数据依赖边和对应于谓词对变量值影响的控制依赖边。
通过首先确定定义的变量集和每个语句使用的变量集,并计算每个语句和谓词的到达定义,可以从控制流图计算程序依赖图的边,这是编译器设计的标准问题。
例如,图7-4显示了图7-1中给出的代码示例的程序依赖关系图。请注意,控制依赖关系边不仅仅是控制流边,特别是,不能再从图中确定
语句的执行顺序,而语句和谓词之间的依赖关系是清晰可见的。
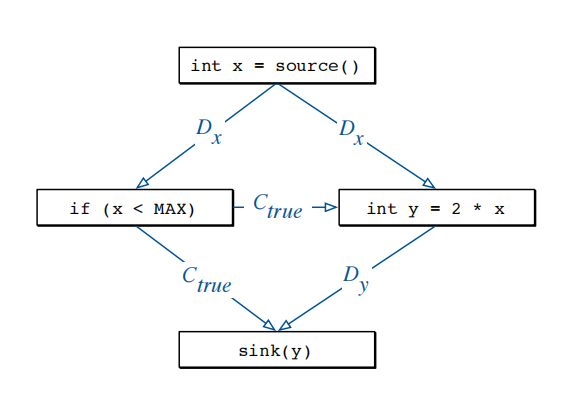
图7-4 程序依赖图示例
7.2 代码属性图生成原理
在绝大多数情况下,仅一种表示不足以描述漏洞类型。
因此,本文提出的代码属性图概念将这三种表示结合到一个联合数据结构中。特别是,本文首先将 AST、CFG 和 PDG 建模为属性图,然后继续将它们合并到一个图中,以提供各个表示的所有优点。
A.转换抽象语法树
提供源代码到语言结构的详细分解的唯一表示是 AST。因此,本文通过将 AST 表示为GA = (VA, EA, λA , µA)开始构建联合表示,其中节点由树节点给出,边是通过标记函数标记为 AST 边的对应树边。
此外,本文使用为每个节点分配 属性代码,以便属性值对应于节点表示的运算符或操作数。最后,本文为每个节点分配一个属性顺序,以反映树的有序 结构。因此,图的属性键为={},而属性值集由所有运算符、操作数和自然数给出。
B.转换控制流图
作为下一步,本文准备将CFG合并到一个联合表示中。为此,本文将CFG表示为一个属性图GC = (VC , EC , λC , ·),其中节点VC仅对应于AST中的语句和谓词,即所有节点VA的属性值为STMT和PRED。此外,本文定义了一个边标记函数λC,它将标签集合ΣC = {true, false}分配给属性图中的所有边。
C. 转换程序依赖关系图
PDG表示语句和谓词之间的数据和控制依赖关系。因此,这个图的节点与CFG的节点相同,只有两个图的边不同。因此,PDG可以通过定义一组新的边EP和相应的边标记函数λP:Ep→ΣP来表示为属性图GP=(VC,EP,λP,µP),其中ΣP={C,D}对应于控制和数据依赖关系。此外,本文为每个数据依赖项分配一个属性符号来表示相应的符号,为每个控件依赖项分配一个属性条件,以表示原始谓词的状态为真或假。
D. 结合表示
作为最后一步,本文将这三个属性图合并成一个联合的数据结构,表示为代码属性图。构造这个图所必需的关键见解是,在这三个图中的每个图中,源代码中的每个语句和谓词都存在一个节点。事实上,AST是这三种表示中唯一的一种,它引入了额外的节点。因此,语句和谓词节点自然地连接表示,并作为从一种表示到另一种表示的过渡点
E. 定义
代码属性图是由源代码的AST、CFG和PDG构造而成的属性图G=(V、E、λ、µ)
• V = VA,
• E = EA ∪ EC ∪ EP ,
• λ = λA ∪ λC ∪ λP and
• µ = µA ∪ µP ,
结合标记和属性函数与一些符号。
图7-5中给出了图7-1中所示的代码示例的代码属性图的一个示例。为简单起见,属性键和值以及AST边缘上的标签未显示。图中的节点主要匹配图2a中的AST(除不相关的FUNC和IF节点外),而转换后的CFG和PDG用彩色边表示。
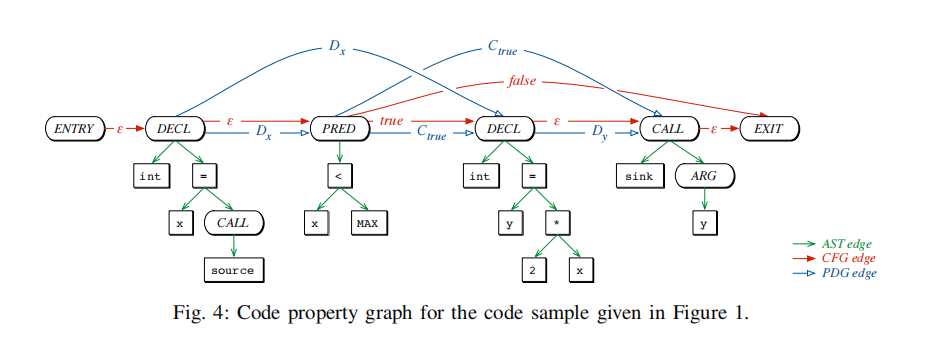
图7-5 代码属性图示例
7.3实际场景应用
本文在linux上进行了代码审计,通过审查 2012 年 Linux 内核报告的所有漏洞的代码来进 行覆盖率分析,并确定哪些漏洞类型可以使用图遍历进行建模。其次,本文研究了其方法发现漏洞的能力,方法是为普遍存在的漏洞构造遍历并将其应用于 Linux 内核的代码属性图。
实验环境:
在配备 2.5 GHz Intel Core i5 CPU 和 8 GB 主内存的笔记本电脑上,导入包含约 130 万行代码的 Linux 内核 版本 3.10-rc1 总共需要 110 分钟。生成的数据库需要 14GB 的磁盘空间用于节点和边缘,另外 14GB 用于高效索引。
获取结果:
获得了具有 5200 万个节点和 8700 万条边的代码属性图。
随后对生成图进行覆盖率分析:
首先查询 MITRE 组织维护的中央漏洞数据库,查找 2012 年分配给 Linux 内核漏洞的所有 CVE 标识符。共检索了 69 个标识符,解决了内核源代码中 88 个独特的漏洞。为了将这些漏洞分类为不同的类型,作者手动检查每个漏洞的修补程序,并确定报告的漏洞的根本原因。有了这些信息,可以将 88 个漏洞分配到 12 种常见类型,如TABLE I所示。超过一半的漏洞(88 个漏洞中的47个)是内存泄漏、缓冲区溢出或资源泄漏。

为了评估该方法的覆盖范围,作者分析了描述 Linux 内核中发现的 12 种漏洞类型所需的代码表示。分析了(a)单独的 AST,(b)AST 和 PDG 的组合,(c)AST 和 CFG 的组合,以及(d)AST、PDG 和 CFG 的组合的覆盖 率。分析结果见TABLE II。
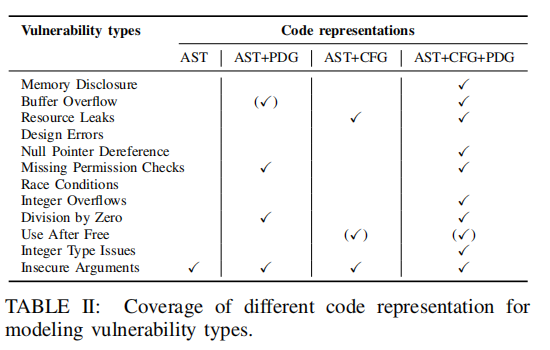
通过在代码属性图中结合所有三种表示,最终能够利用 AST、CFG 和 PDG 提供的信息,对 12 种漏洞类型中的 10 种进行建模。剩下的两种类型,竞争条件和设计错误,很难用图遍历来表示,因为第一种类型取决于运行时属性,第二种类型在没有程序预期设计细节的情况下很难建模。此外,存在许多人为的释放后使用漏洞的情况,如果没有运行时信息,这些漏洞很难描述。
总结:
通过运行四次遍历,作者发现了 18 个以前未知的漏洞,所有这些漏洞都已由内核开发人员解决。特别令人震惊的是,在 18 个漏洞中,有 9 个是去年普遍存在的漏洞类型。这表明,攻击者可以对现有漏洞模式进行建模,从而通过遍历有效地发现代码库中的类似缺陷。TABLE III总结了作者的调查结果。

8 实验结果

图遍历从Linux内核中提取的11个函数,漏洞为着色行。

使用本文的方法发现的Linux内核驱动程序中的缓冲区溢出漏洞。
另外,本文提出的代码属性图结构被广泛应用,为后续许多源码漏洞自动挖掘研究者提供了理论和工具上的支持。
9 本文不足
首先,本文的方法是纯静态的,因此无法克服静态程序分析的固有局限性。当本文实现控制和数据流跟踪时,本文不会解释代码, 例如,使用符号执行寻找等价但格式不同的表达式。因此,运行时行为(如竞争条件)导致的漏洞无法使用代码属性图建模。
其次,由于漏洞发现问题在一般情况下是不可判定的[33],本文的方法只能发现潜在的易受攻击代码。与针对特定类型 漏洞的方法不同,本文侧重于挖掘漏洞的通用方法,这些漏洞可能无法保证安全漏洞的存在,但可以识别非常大的软件项目中的潜在漏洞。
- 本文当前的实现没有解决过程间分析。当本文根据图形数据库中的调用关系链接函数时,制定有效的过程间遍历带来了额外的挑战。
10 代码和数据集地址
Linux内核源码:https://github.com/torvalds/linux