1 论文来源
EMNLP (2021)(CCF-B类会议)
2 论文作者
Mieradilijiang Maimaiti, Yang Liu , Yuanhang Zheng, Gang Chen ,Kaiyu Huang , Ji Zhang7, Huanbo Luan, Maosong Sun
3 论文地址
https://aclanthology.org/2021.emnlp-main.158.pdf
4 论文简介
目前最先进的(SOTA)有效的神经网络方法和基于预训练模型(PTM)的微调方法已应用于中文分词(CWS)中,取得了很好的效果。然而,以往的工作主要集中在每次迭代时使用固定语料库训练模型,生成的中间信息也很有价值却往往被忽略。此外,以往的神经方法的鲁棒性受到大规模标注数据的限制,因为在带注释的语料库中存在一些噪声。于是,作者提出了一种自监督的直接有效的CWS方法。首先,训练一个分词模型,并使用它来生成分割结果。然后,使用一个改进的掩蔽语言模型(MLM)来评估基于MLM的预测的分割结果的质量。最后,通过改进的最小风险训练来帮助训练分段者。实验结果表明,该方法在9个不同的CWS数据集上的单准则训练效果优于以往的方法。
5 解决问题
1.标注的不一致性:操作系统 & 操作/系统
2.词边界检测:犯罪案 & 走私/案
3.架构的复杂性:分词模型越来越复杂,对算力要求偏高
4.低鲁棒性:不同数据集或领域上同个模型的表现差异大
6 本文贡献
1.提出了一种自监督的CWS方法,它使用改进后的MLM的预测来辅助分词模型。
2.提出了一个改进版本的MRT(最小风险训练方法),通过增加正则化项,以提高分词模型的性能。
3.该方法在不同标准训练下优于以往的方法,并提高了模型的鲁棒性
7 论文方法
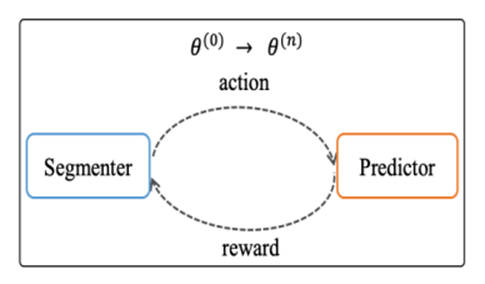
作者的方法的总体过程见算法1:首先,训练一个分词模型,并使用它来生成分割结果。然后,根据分割结果,根据一定的策略生成掩蔽句子,并用掩蔽句子训练一个MLM。之后,在训练集中掩盖了这些句子,并且使用MLM设置和预测掩蔽部分来评估分割结果的质量。最后,我们利用这些结果来帮助训练分割模型。
具体训练过程如下:输入是一个具有基于字符的标记化的句子,输出由一个BERT模型和一个CRF层按顺序生成。分割结果由四个标签B、M、E和s.b表示。B和E表示一个多字符单词的开始和结束,M表示多字符单词的中间部分,S表示单字符单词。分割模型用PTM(即BERT)初始化,并使用负对数似然(NLL)损失进行训练。
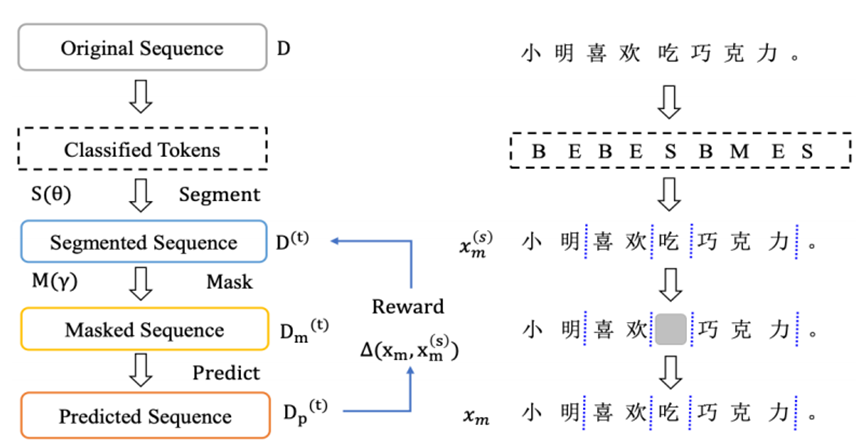
其中,D、D(t)和D(t)p分别表示原始序列、分割序列和预测标记,S(θ)和M(γ)分别代表分割模型和修改后的掩模预测模型。∆(xm,x(s)m)表示在预测掩牌时作为奖励的损失。
在这项工作中,作者使用了一个类似于BERT的修订版MLM(Devlin等人,2019年)来评估分割的质量。然而,在中文BERT的PTM训练中采用的掩蔽策略通常是把单个汉字作为一个单位。这种掩蔽策略不能反映分割信息,因此作者设计了一种新的能够反映分割信息的掩蔽策略。具体策略如下:
1.一个单词中只有一个字符或多个连续字符可以同时被遮蔽。
2.设置一个阈值mask_count。如果一个单词的长度小于或等于mask_count,则整个单词将被遮蔽。否则,随机选择连续的mask_count单词并遮蔽它们。
3.从所有可能的遮蔽中,随机选择一个等概率的遮蔽,并将其应用于输入。
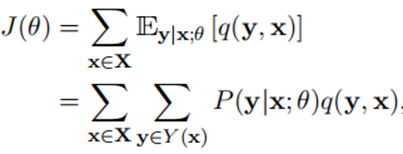
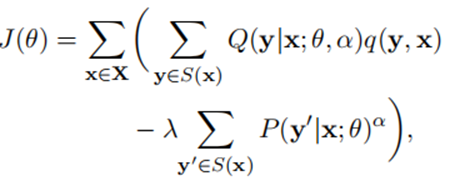
由于可能的分割结果,公式1的计算成本大得难以接受。因此,需要从从Y(x)中采样S(x)的一个子集,并在S(x)上定义一个新的概率分布Q。此外,由于损失函数的下降与P的相比不够平均,这可能会降低一些良好的分割结果的概率,从而降低分割模型的性能。因此,作者增加了一个正则化项。
8 实验结果
1.实验准备
实验中使用的语料库分别来自SIGHAN05(爱默生,2005)、SIGHAN08(Jin和Chen,2008)、SIGHAN10(赵美和刘,2010)和其他一些开放数据集(Zhangetal.,2014)。语料库的统计数据如表3所示,一些超参数也在表4中给出。数据集MSRA、PKU、AS和CITYU来自SIGHAN052语料库,数据集CTB和SXU来自SIGHAN08,CNC、UDC和ZX来自其他开放数据集。语料库SIGHAN08和其他数据集也是公开的3。SIGHAN10包含不同领域的数据,我们选择“金融”、“文学”和“医学”作为跨领域实验数据集。此外,在整个实验中都采用CTB6作为CTB数据集。使用AS和CITYU的原始格式,而不是使用它们相应的简化版本。此外,使用与Huang等人相同的数据预处理。(2020年)进行整个实验。在单标准和多标准实验中,大部分结果都来源于相应的论文。对于多标准实验(Chenetal.,2017),遵循He等人。(2018年),并通过结合所有数据集来准备训练数据。在噪声标记实验中,将输入序列转换为字符,并为输入序列中字符的每个位置随机生成4个标签(如B、M、E和S)。对所有架构使用相同的预处理数据,只构建每个语料库的10%的噪声标记数据,并使用90%的真实数据。对于修正后的掩蔽策略,通过在SIGHAN05上训练和测试MLM来探索预测器的最佳准确性。
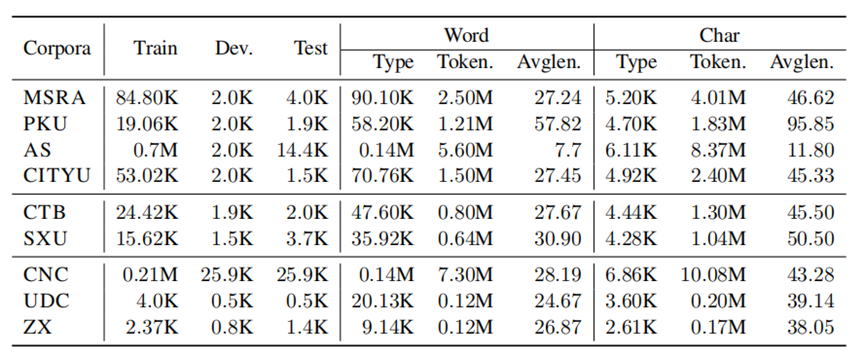
2.实验一
评估指标:F1分数
基线:
- LSTM+BEAM
- LSTM+CRF
- BERT
- SELFATT+SOFT
- BERT+LTL
实验设置:在使用单标准学习的9个标准CWS数据集的测试数据集上的SOTA性能之间的比较(f1-score,%)。“BERT”表示在训练中把BERT作为PTM。任何带下划线的结果都表示重新实现的分数。
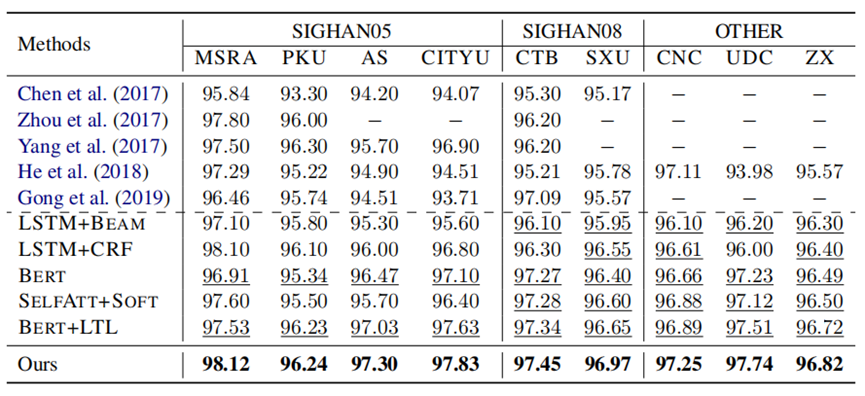
实验结果:该方法在不同标准数据集的单标准学习条件下获得了较好的结果。在流行的数据集中使用了不同的分割标准。特别是PKU、MSRA和ZX的分割规则彼此不同(Huangetal.,2020)。因此,为了研究分割模型的质量,在CWS的9个基准数据集上将作者的方法与之前的SOTA方法进行了比较。除了SIGHAN05语料库上的基线BERT和BERT+LTL外,作者还参考了他们相应论文中报道的结果。然而,对于其他两个语料库(即SIGHAN08和其他其他),作者重新运行了他们的论文中未报告的结果。由于GPU内存较低,重新实现了BERT版本的BERT+LTL,而不是使用roBERTa。
3.实验二
评估指标:F1分数
实验设置:使用多标准学习,比较9个标准CWS数据集的测试数据集上的SOTA性能(f1-score,%)。“BERT”表示在训练中将BERT作为PTM使用。下划线的表明,重新实现了现有的方法,以进行公平的比较。
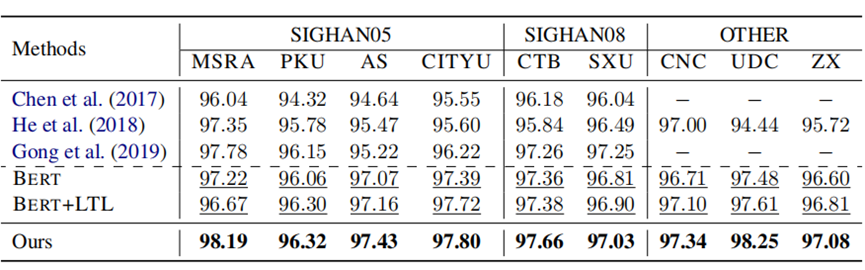
实验结果:作者提出的方法始终优于以前的SOTA方法。虽然在大多数数据集上显著优于所有基线,但多标准学习的一些结果高度接近,有时低于单一标准训练的结果。多标准学习的有效性并不能提高作者的模型在CITYU语料库上的性能。然而,在其他数据集上,作者的模型获得了比单一标准学习更高的结果。
4.实验三
评估指标:f1分数
实验设置:在使用9个CWS数据集的单标准学习上进行噪声标记训练的强基线之间的比较。“BERT”表示在训练中使用BERT作为PTM。
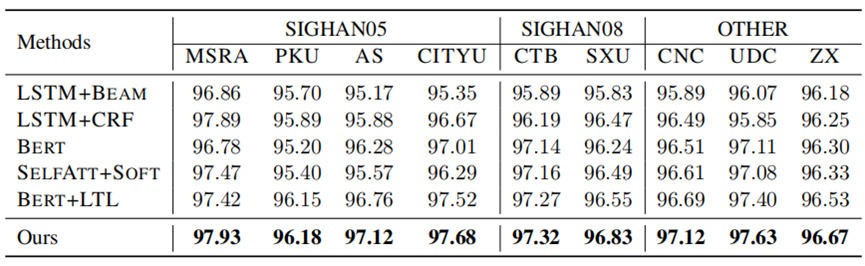
实验结果:为了分析提出的方法相对于修订后的MLM的稳健性,利用噪声标记数据集,其中包含90%的真实数据和10%的随机打乱数据的噪声标记数据集。在本实验中,作者利用了对有噪声标记数据的单准则训练,而不是使用多准则训练。在相同的噪声标记数据集上运行所有模型。显然,所有的结果几乎都低于单标准训练的结果。然而,作者提出的方法仍然比有噪声标记数据集的SOTA基线获得更好的结果。作者不仅使用单标准训练和多标准训练,而且使用噪声标记数据训练,以不断获得比高度相似的以前的工作的改进。
5.实验四
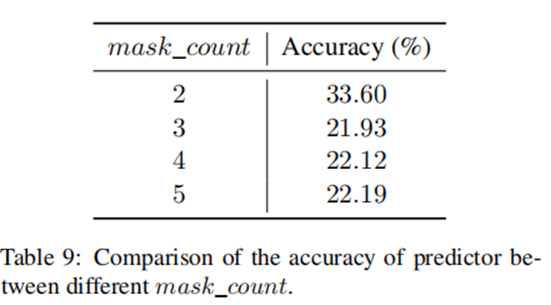
为了探讨mask_count值对MLM质量的影响,作者用不同的mask_count值训练MLM。实验发现,当预测器的准确性达到了最高的分数时mask_count = 2.需要注意的是,如果是mask_count=1,则只能屏蔽一个字符。在这种情况下,屏蔽任何字符都是合法的,无论分割结果如何。因此,作者分析了mask_count大于或等于2的情况,并选择了使MLM的精度最高的mask_count数。
6.实验五
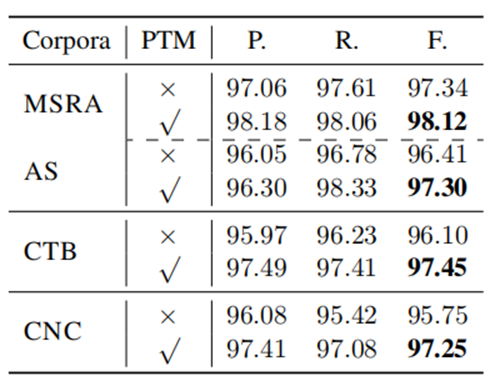
作者探讨了PTM对单准则训练的分割模型的影响。以BERT为PTM,探讨了PTM对不同分割标准的不同数据集(即MSRA、AS、CTB、CNC)上的分词模型质量的影响。直观地说,使用PTM的分割方法的性能比不使用PTM获得了明显更好的结果。
7.实验六
作者认为改进的MRT是我们自我监督分词结构的关键部分。为了选择超参数的最佳值,探索了CTB、CNC和UDC数据集上α、λ和S(x)大小的不同值。
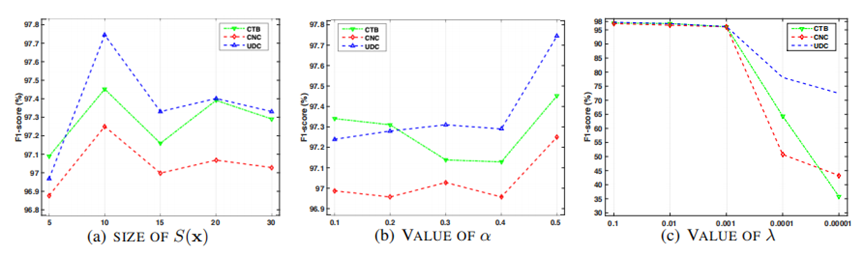
实验结果:S(x)是对应于句子x的所有单词分割结果Y(x)的一个子集。如图6(a)所示,当S(x)=10的大小时,改进的MRT在不同的语料库上明显优于其他值,提高了分割模型的质量。如图6(b)所示,当α=0.5改进了MRT时分割模型的质量。λ是MRT的正则化项参数,如图6(c)所示,当λ=0.1时,模型F1-分数与其他值相比获得了最好的分割性能。
9 本文不足
在本工作中,作责提出了一种CWS的自监督方法。首先根据分割结果生成掩蔽序列,然后使用修正后的MLM来评估分割的质量,并通过改进的MRT来增强分割。实验结果表明,该方法在流行的和跨域CWS数据集上都优于以往的方法,并且对噪声标记数据具有更好的鲁棒性。
优点:
- 利用自监督学习进行中文分词
- 模型的鲁棒性得到提高
- 模型的泛化性能得到了提高
缺点:
- 模型的提升效果不够显著
- 模型对算力需求依然较高