注意:本方法下的漏洞数据需要自己获取,这里只是描述对漏洞数据的处理环节
1.关于CNN(卷积神经网络)
1.1 卷积神经网络的基本概述
CNN由纽约大学的Yann Lecun于1998年提出,其本质是一个多层感知机,成功的原因在于其所采用的局部连接和权值共享的方式:一方面减少了权值的数量使得网络易于优化,另一方面降低了模型的复杂度,也就是减小了过拟合的风险。该优点在网络的输入是图像时表现的更为明显,使得图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建的过程,在二维图像的处理过程中有很大的优势,如网络能够自行抽取图像的特征包括颜色、纹理、形状及图像的拓扑结构,在处理二维图像的问题上,特别是识别位移、缩放及其他形式扭曲不变性的应用上具有良好的鲁棒性和运算效率等。
1.2 卷积神经网络的结构
卷积神经网络(CNN)有5种结构:输入层(Input Layer)、卷积层(Convolutional Layer)、池化层(Pooling Layer)、全连接层(Fully Connected Layers, FC)、Softmax层。
输入层(Input Layer):由于输入的数据种类繁多且十分复杂,如果数据不经过一定的处理而直接递交给神经网络,可能会导致神经网络收敛速度慢,训练时间长,甚至导致实验误差过大。因此需要在输入层对数据进行一系列预处理。
卷积层(Convolutional Layer):卷积神经网络中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更深层的网络能从低级特征中迭代提取更复杂的特征。卷积层结构如图1所示。
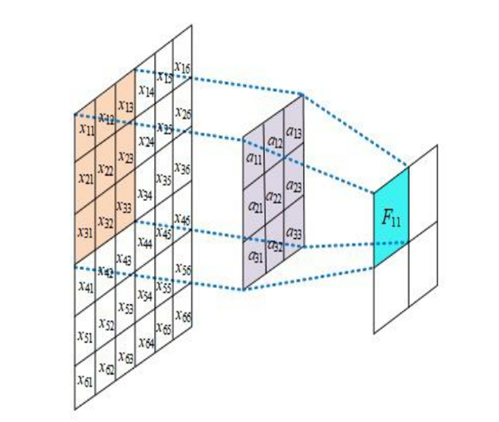
图1 卷积神经 层结构
池化层(Pooling Layer):池化层是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。
全连接层(Fully Connected Layers, FC):全连接层在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在经过多轮卷积层和池化层的处理之后,在CNN的最后一般会由1到2个全连接层来给出最后的分类结果。经过几轮卷积层和池化层的处理之后,可以认为数据信息已经被抽象成了信息含量更高的特征。我们可以将卷积层和池化层看成自动特征提取的过程。在提取完成之后,仍然需要使用全连接层来完成分类任务。
Softmax层:通过Softmax层,可以得到当前样例属于不同种类的概率分布问题。
2.CNN模型的搭建
2.1 基于CNN的漏洞分类流程简介
结合CNN和文本语义的漏洞分类流程图如图2所示。
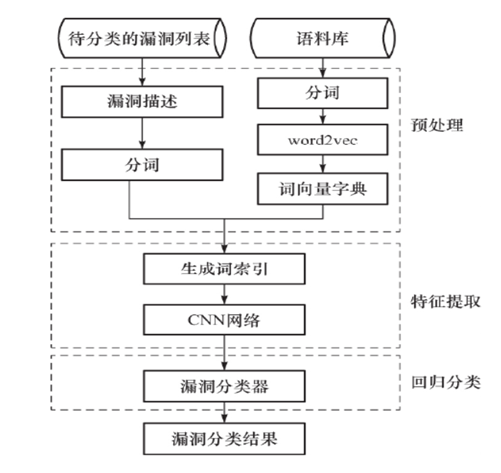
图2 基于CNN的漏洞分类流程
2.2文本数据预处理
由于从各大漏洞库中获取的漏洞描述是计算机无法直接识别和计算的文本数据,不能直接放进CNN卷积神经网络内进行学习,需要对其进行数据的预处理,包括分词和去除停用词。
- 分词
分词是指将连贯的漏洞描述的文本信息切分为单个词,将整个漏洞描述的文本信息转化为可以由统计信息计算的最小语义单位。这个过程是漏洞文本预处理的第一步也是最重要的一步。对于用英文单词描述的漏洞信息,单词细分是很简单的。只需要识别整段漏洞描述文本间的空格或标点来划分单词。例如CVE-2016-6045 漏洞的描述为:”IBM Tivoli Storage Manager Operations Center is vulnerable to cross-site request forgery which could allow an attacker to execute malicious and unauthorized…”分词之后变为:[“IBM”,”Tivoli”,”Storage”,”Manager”,”Operations”,”Center”,”is”,”vuln-erable”,”to”,”cross”,”site”,”request”,”forgery”,”which”,”would”,”allow”,”an”,”attacker”,”to”,”execute”,”malicious”,”and”,”unauthorized”, …]
- 去除停用词
停用词是指在信息检索中,为节省存储和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为 Stop words(停用词)但对与我们的分类工作来说,停用词基本上是一些完全没有用或者没有意义的词,例如助词、语气词等。如果不将停用词去除,那么CNN的学习效率会在一定程度上降低。例如,原句子为:“万里长城是中国古代劳动人民血汗的结晶和中国古代文化的象征和中华民族的骄傲”。分词后:“万里长城/ 是/ 中国/ 古代/ 劳动/ 人民/ 血汗/ 的/ 结晶/ 和/ 中国/ 古代/ 文化/ 的/ 象征/ 和/ 中华民族/ 的/ 骄傲”。去除停用词后:“万里长城/ 中国/ 古代/ 劳动/ 血汗/ 结晶/ 中国/ 古代/ 文化/ 象征/ 中华民族/ 骄傲/”。
2.3 特征提取
CNN模型的第二部分是特征提取模块,将矢量层得到固定维度词向量输入到特征提取模块,经卷积层后送入ReLU激活层、池化层和全连接层。为防止模型过拟合并在测试集上达到很好的泛化效果,在每层卷积后增加batchnorm层,通过 batchnorm 层对数据做归一化操作去除数据相关性,减小数据的绝对差异,突出其相对差异,使模型更稳定的同时加快收敛速度。
2.4 回归分类
第三部分是回归分类模块,本项目采用具有类间抑制作用的Softmax层对漏洞文本特征进行分类预测。训练时采用交叉熵函数计算漏洞分类损失,公式如下所示:
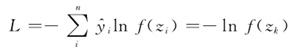
式中:y(y回归)为标签值;k为输入文本标签所对应的神经元;f(z)为Softmax回归函数,其中m为输出的最大值,即漏洞分类输出概率。
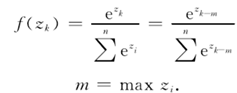
具体实例:
以漏洞描述“远程攻击者可通过提交特制的URL利用该漏洞绕过身份验证,访问重要的服务。”为例,其安全漏洞类型判定示意图如图3所示。
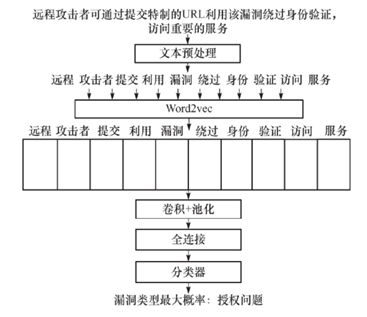
图3基于CNN的漏洞分类模型结构
步骤简介如下:
步骤1,对该段描述进行预处理,输出“远程 攻击者 提交 利用 漏洞 绕过 身份 验证访问 服务”,并将其进行矢量化;
步骤2,通过CNN网络的卷积层、池化层、全连接层,对该矢量层进行特征提取;
步骤3,通过回归分类计算,根据漏洞类型最大概率,该漏洞类型为授权问题。
注意:上述方法只是一个概述,部分计算公式没有列出,感兴趣的同学可以自己翻阅更多资料
参考文献:
Conneau A, Schwenk H, Barrault L,et al.Very deep convolutional networks for text classification[J].Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistuicss,2017,1:1107-1116
Lai Siwei, Xu Liheng, Liu Kang, et al.Recurrent convolutional neural networks for text classification[C] //29th AAAI Conference on Artifical Intelligence. Texas,Austin:AAAI,2015:2267-2273
廖晓锋,王永吉,范修斌,等.基于 LDA 主题模型的安全漏洞分类[J].清华大学学报(自然科学版),2012(10):1351-1355