背景介绍
Deepfakes是数字操纵的结果,目的是伪造看起来十分逼真的虚假图像。随着深度生成模型的快速发展,例如现今最为先进的使用变分自动编码器(VAE)以及生成对抗网络(GAN)来获得伪造的图像及视频。按照传统视频深度伪造检测的手段,一般选择卷积神经网络(CNN)进行相关的训练,在这篇论文中,作者使用各种类型的Vision Transformer与用作特征提取器的卷积神经网络EfficientNet B0结合使用,与一些最新使用Vision Transformer的模型相比,在各种性能上都有一定的提高,是目前比较好的Deepfake检测手段。
技术详解
首先,Deepfake中最重要的部分就是提取人脸部分,在本论文中,首先使用最先进的人脸检测器MTCNN进行预提取,这在很多Deepfake检测类的实验中均有用到。作者提出了两种混合 convolutional-transformer架构,用来将预提取的人脸作为输入并输出人脸被篡改的概率,这两种架构经过严格的监督训练用以区分真实视频和虚假视频,因此,作者采取分而治之的方式,将整个问题分为两个问题,具体来说,是Efficient ViT和Convolutional Cross ViT,如下图所示:
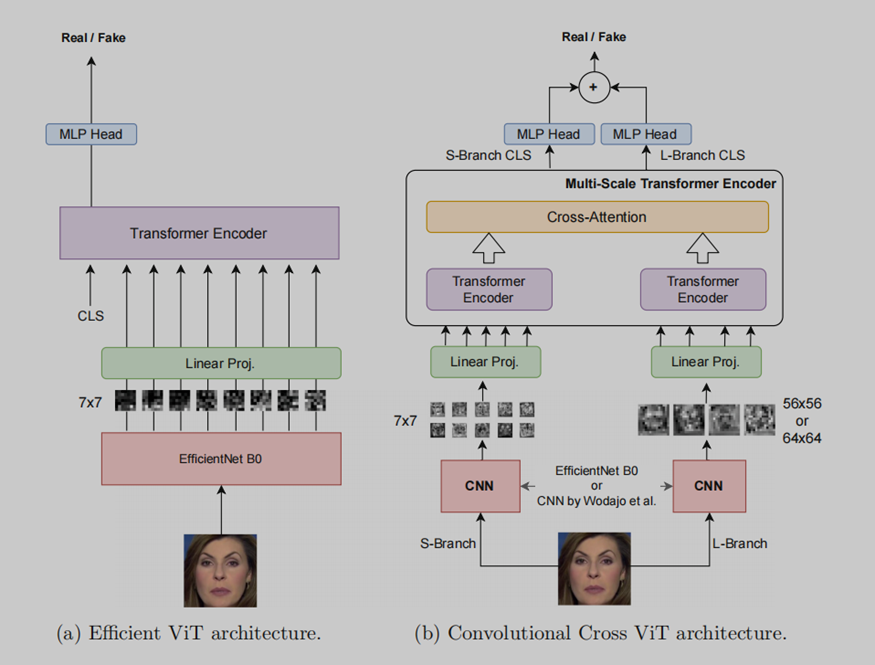
The Efficient ViT
由两个模块组成,一个用作特征提取器的卷积模块,一个是Transformer编码器模块,其设置与ViT非常相似,作者使用EfficientNet B0,EfficientNet网络中最小的一个,作为卷积提取器来处理输入的人脸,具体而言,EfficientNet为每个输入人脸的块生成一个视觉特征,每个块为7×7像素,经过线性投影后,每个空间位置的每个特征都会被Vision Transformer进一步处理。CLS标记用于生成二元分类分数。EfficientNet B0特征提取器使用预训练权重进行初始化,并进行微调,以使网络的最后几层能够对这个特定的下游任务执行更一致和合适的特征提取。从EfficientNet B0卷积网络中提取的特征简化了Vision Transformer的训练,因为CNN特征已经包含了图像中重要的低级和局部化信息。
The Convolutional Cross ViT
因为深度伪造生成方法引入的伪影可能会在局部和全局同时出现,所以仅仅采用小块作为Efficient ViT不是理想的选择,对此作者引入了Convolutional Cross ViT架构,Convolutional Cross ViT建立在Efficient ViT和多尺度Transformer架构的基础上。更详细地说,Convolutional Cross ViT使用两个不同的分支:处理较小块的S分支和处理较大块以拥有更广泛感受野的L分支。来自两个分支的Transformer编码器输出的视觉标记通过交叉注意力结合在一起,允许两个路径之间的直接交互。最后,对应于两个分支输出的CLS标记用于产生两个单独的逻辑值。这些逻辑值相加,最后通过sigmoid产生最终的概率。