1 原文作者
Wanzheng Zhu(University of Illinois at Urbana-Champaign)
Hongyu Gong(Facebook)
Rohan Bansal(Carnegie Mellon University)
Zachary Weinberg(Carnegie Mellon University)
Nicolas Christin(Carnegie Mellon University)
Giulia Fanti(Carnegie Mellon University)
Suma Bhat(University of Illinois at Urbana-Champaign)
2 论文来源
The 42nd IEEE Symposium on Security and Privacy (Oakland 2021)
3 论文地址
http://www.andrew.cmu.edu/user/nicolasc/publications/Zhu-Oakland2021.pdf
4 论文简介
边缘团体和组织长期以来一直使用委婉语—-即听起来很普通但带有秘密含义的词,来掩盖他们正在讨论的内容。如今,委婉语常用于躲避社交媒体平台强制执行的内容审核政策。现有的内容审核工具依赖于在“禁止列表”中进行关键字搜索,但众所周知,这些工具并不精确:即使仅限于脏话,它们仍然会导致令人尴尬的误报。当一个常用的普通词用于委婉的含义时,将其添加到基于关键字的禁止列表中是无效的:例如“锅”(存储容器或大麻)或“加热器”(家用电器或枪支),其真实含义难以判断。社交媒体公司转而聘请员工手动检查帖子,但这是昂贵的、不人道的,而且效率也不高。人类审查员通常能轻易发现委婉语,但他们可能不知道秘密含义是什么,因此不知道该消息是否违反政策。此外,当一个委婉语被禁止时,使用它的组织只需要发明另一个委婉语就能继续躲避审查。
这篇论文将展示一种无监督算法,该算法通过分析句子级上下文中的单词,既可以检测委婉使用的单词,又可以识别每个单词的秘密含义。与使用上下文无关词嵌入的现有技术相比,本文用于检测委婉语的算法在文本语料库中对未标记委婉语的检测准确度提高了30-400%,同时本文第一个提出了揭示单词委婉含义的算法。本文提出的方法可以帮助社交媒体更好的进行内容审核。
5 解决问题
本文主要试图解决委婉语检测与委婉语识别两大问题。
委婉语检测问题最大的挑战在于从委婉语无害的表面含义中找寻其隐藏含义。如“For all vendors of ice, it seems pretty obvious that it is not as pure as they market it” 中,“ice” 一词可以理解为“冰”。然而通常人们购买时并不关心“冰”的纯度,这里的 “ice” 实际上是毒品冰毒的意思。已有工作中尝试使用静态词嵌入(如Word2Vec)解决此问题,但这类技术无法区分同一词的不同含义,所以在委婉语检测中效果不佳。比如在“冰”这个例子中,使用冰水这个含义的句子远超过使用冰毒这个含义的句子,使得检测其委婉含义十分困难。
委婉语识别问题主要是映射一个现有的委婉语到特定的目标关键词。该问题的主要挑战有以下四点:
- 目标关键词的语义区别通常很小,比如“可卡因”和“大麻”,很难从纯文本语料单独学习到;
- 委婉语可以用于普通含义或秘密含义,使得语义区别更难捕获;
- 没有公开的列表可以用于准确映射目标关键词与委婉语;
- 不清楚解决此任务需要哪些语言和本体论资源;
就作者所知,目前并没有能准确捕获委婉语真实含义的工作,仅有一些边缘工作能识别委婉语的大致范围,如在毒品类中能够确定其为镇静剂、兴奋剂或致幻剂,而无法确定其为某种毒品。
6 本文贡献
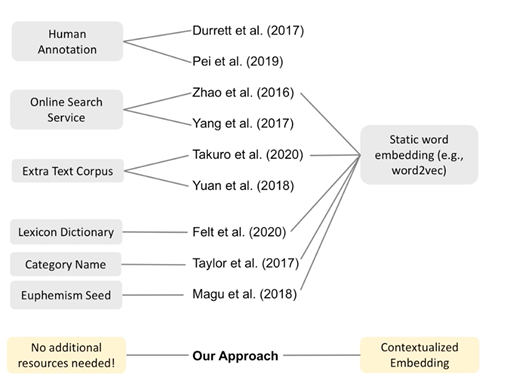
本文主要贡献及创新点在于:
- 检测与识别委婉语仅需语料数据及目标管检测,无需额外资源;
- 将NLP领域新研究“上下文相关词嵌入”与委婉语检测结合;
7 论文方法
委婉语检测:作者将委婉语检测问题视做无监督填表问题,并使用遮蔽语言模型结合自监督学习来解决。提出的方法主要分为3个步骤:
- 提取上下文语义信息;
- 过滤信息不足的语境信息;
- 生成委婉语候选词;
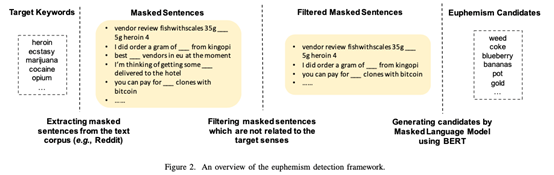
具体而言,在委婉语的检测模块中,作者首先 MASK 掉包含目标关键词的句子作为上下文信息语料,然后通过判断 MLM 生成的前5个候选词中是否包含任一目标关键词作为遮蔽语言模型的学习任务,以此来降低上下文信息语料中的噪声。最后再次使用在语料上调优好的遮蔽语言模型生成词表中每个词在 Masked 句子中出现的概率,生成委婉语候选词。
委婉语识别:在委婉语含义识别部分,作者分别通过一个粗粒度的分类器和细粒度的分类器来对黑话的隐含意义进行理解。首先提取所有包含某个委婉语的所有遮蔽掉目标词句子,然后通过使用粗粒度的分类器筛选掉句子中与目标类别无关的句子。之后使用细粒度分类器对剩下的句子进行多分类,分类标签是每个遮蔽掉的目标词。最后根据这些句子的每个目标词分类标签数量计算概率分布,最多的目标词则为该委婉语的隐含义。在粗粒度分类器的训练过程中,作者采用了负采样的策略,即随机在语料中选取一个句子并随机遮蔽一个字符。由于语料庞大且种类丰富,随机选择的句子有很大的可能与目标词无关联,以此形成粗粒度分类器的训练数据集。而在细粒度分类器中,遮蔽掉目标词的句子自身构成训练集。作者最后选用 LSTM 循环神经网络作为粗粒度分类器模型,选用多类逻辑回归作为细粒度分类器模型。

8 实验结果
实验准备:
环境:20个2.9GHz Intel Core i7 CPUs以及1个GeForce GTX 1080 Ti GPU
数据集:
- 毒品:从46个与毒品以及暗网市场相关的不同的reddit子论坛提取了1,271,907个帖子。事实基础选用DEA缉毒局发布的毒品与委婉语对应列表。
- 武器:前人收集的数据集,共包含310,898个帖子。事实基础选用The Online Slang Dictionary、Slangpedia、The Urban Thesaurus俚语词典作为对照。
- 色情:从gab social networking services获取的2,894,869个帖子,事实基础选用The Online Slang Dictionary俚语词典。
委婉语检测:
评估指标:P@K
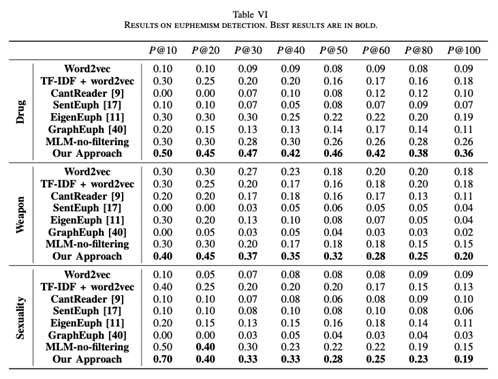
实验结果:作者对比了Word2vec、Cantreader等基准模型,以P@K数值作为度量标准。结果显示作者提出的方法最终在毒品、武器以及色情类委婉语中均有最佳效果。
委婉语识别:
评估指标:Acc@K
实验结果:
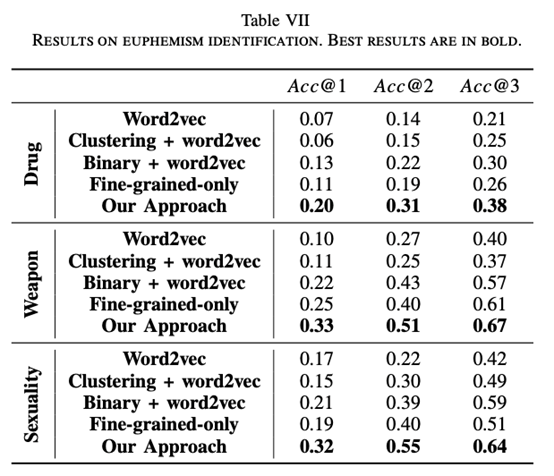
作者最后选用LSTM循环神经网络作为粗粒度分类器模型,选用多类逻辑回归作为细粒度分类器模型,最终在测试集上达到了24%的委婉语含义识别准确率。
9 本文不足
- 只能解决目标关键词的委婉语问题,且仅限于毒品、武器、色情三个领域;
- 没有说明目标关键词(Target Keywords)的来源及数量;
- 对比实验效果不算特别好;
- 不能直接应用到其他语言的委婉语问题;
10 代码和数据集地址