0x00 诞生背景
软件复杂性的增加,给软件安全性带来极大的挑战.随着软件规模的不断增大以及漏洞形态多样化,传统漏洞挖掘方法由于存在高误报率和高漏报率的问题,已无法满足复杂软件的安全性分析需求.近年来,随着人工智能产业的兴起,大量机器学习方法被尝试用于解决软件漏洞挖掘问题.
首先,通过梳理基于机器学习的软件漏洞挖掘的现有研究工作,归纳了其技术特征与工作流程;接着,从其中核心的原始数据特征提取切入,以代码表征形式作为分类依据,对现有研究工作进行分类阐述,并系统地进行了对比分析;最后,依据对现有研究工作的整理总结,探讨了基于机器学习的软件漏洞挖掘领域面临的挑战,并展望了该领域的发展趋势
0x01 Why there is CPG?
由于许多漏洞只有通过同时考虑代码的结构、控制流和依赖关系才能充分发现,Yamaguchi 等人于 2014年提出了一种新的代码表示方法,即将经典程序分析中 AST、CFG 和程序依赖图的概念合并成一个联合数据结构,称为代码属性图,从而提升对漏洞上下文的表征能力.
其中,属性图是带属性和边标记的多重图,图中所有节点和边都可以指定属性,并依据属性进行赋值.AST 表示程序结构如何嵌套,CFG 表示语句的执行顺序,程序依赖图则明确数据流和控制依赖.系统首先通过对给定代码库中的每个函数进行解析和分析,生成 AST、CFG和程序依赖图,并将这 3 种图表示为属性图;再将 3 种属性图以语句节点为融合点进行融合,得到代码属性图;最后,基于明确的调用与被调用关系将所有函数的图链接在一起,从而将整个代码库表示为一个大型代码属性图.通过图遍历为常见类型的漏洞创建有效的检测模板来发现漏洞.
0x02 图生成
利用开源的静态分析工具 Joern等工具对源代码进行分析,并生成代码属性图,将其存储在 Neo4J 图数据库中,以便后续通过图中包含的信息进行查询,从而编码成为张量形式的数据。
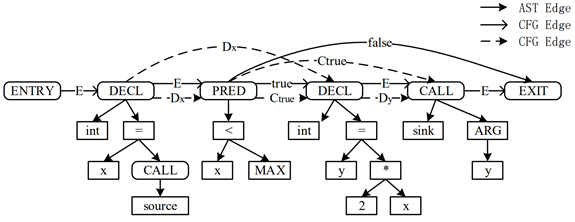
图一 代码属性图示例
0x03 图的切片
(1) 查找敏感语句
通过正则匹配等词法分析技术查找函数中的敏感操作语句,其在代码属性图中体现为控制流图节点.将该节点进行记录,并作为后续对程序进行切片的切片准则(slicing criterion).此外,由于敏感操作与漏洞具有密切关联,本方法会输出敏感操作所在的位置,辅助开发人员进行漏洞定位.
(2) 对函数代码进行静态切片
静态切片以程序的静态信息为依据,通过语句之间的数据和控制依赖对代码进行裁剪,从而保留与特定语句具有依赖关系的代码,并剔除无关代码.目前,程序静态切片方法可分为两类:一类是基于数据流方程的程序切片技术,另一类是基于图可达性分析的程序切片技术.本文所使用的是基于程序依赖图进行图可达性分析的程序切片技术.其在程序依赖图上使用图可达性算法,计算可能影响切片准则处语句的语句和谓词,进而获得程序切片.由于代码属性图是抽象语法树、控制流图和程序依赖图组成的联合数据结构,因此本文根据代码属性图中的程序依赖图进行切片,在上一步获得与敏感操作语句对应的节点后,根据程序依赖图中的控制依赖边和数据依赖边,找到与该敏感语句节点具有依赖关系的节点集,并删除该节点集之外的节点,将剩余节点所构成的生成子图作为切片后的代码属性图.
0x04 图的特征编码
深度学习中的神经网络模型要求输入为固定形状的张量形式数据,因此需要实现一种对代码进行表示及编码的算法作为程序抽象图结构和神经网络之间的桥梁.
图二 特征张量空间分布
如下是关于特征张量的一系列定义:



0x05 LSTM神经网络
LSTM的结构图如图三所示。LSTM是在RNN神经网络基础上的变形,改变了RNN内部计算结构网络,增加了记忆单元c,用c来存储之前序列的有用内容并应用到之后的序列中,解决了RNN无法实现长序列记忆的问题。LSTM的基本单位是三个不同的门结构:
1)遗忘门:作用于上一个单元传递下来的记忆细胞状态c-1,目的是选择性遗忘记忆细胞中的信息以实现选择相关的信息,丢弃无关的内容;
2)输入门:记忆细胞状态,目的是将新的信息选择性地记录到记忆细胞中,传向下一级;
3)输出门:作用于输入和隐层输出,目的是使得最后输出既包含细胞状态又包括输入,将其结果传到下一个层。通过这三个门,LSTM能自动决定哪些信息被遗忘,哪些信息被保留;通过LSTM的前向传递使得一个记忆细胞可以很容易传递到很远的距离来影响输出,所以LSTM可以解决远距离信息的学习问题。

图三 LSTM神经网络结构
Bi-LSTM继承了LSTM的特性,但区别在于Bi-LSTM是由两个相反方向的LSTM组成;向前的LSTM可以根据前序信息影响后序信息,而向后的LSTM可以通过后序信息影响前序信息;因此该结构可以有效地处理存在双向上下文依赖的任务。
0x06 总结
由于基于图的表征形式能够反映代码中更丰富的语法和语义特征,相较于其他表征形式更加抽象,可蕴含代码中更深层次的特征.但是,由于图的生成过程复杂、开销大,且处理基于图的表征形式需要使用到图匹配算法,这类算法的时间复杂度和空间复杂度往往非常高,甚至会达到 NP 难.因此,基于图的表征形式的研究检测速度慢,不适用于大型软件程序的检测.