1 原文作者
Piotr Przybyła(Institute of Computer Science, Polish Academy of Sciences)
2 论文来源
AAAI Conference on Artificial Intelligence(2020)
3 论文地址
https://sci-hub.se/10.1609/aaai.v34i01.5386
4 论文简介
(1)研究背景:假新闻的问题和网络媒体中更广泛的可信度问题吸引着大量的关注。社会媒体网站的反应之一是对某些内容发出不可信的信号。但是,其所涉及的人工事实核查过于费力,无法适用于在这些平台和其他地方发表的每一篇文章。因此,许多研究采用文本分析技术来自动评估在线发布的文件的可信度然而,这项任务面临很多挑战,主要包括文本理解方法的水平不够,以及知识库的覆盖面和时效性有限。
(2)研究内容:网络媒体中的假新闻自动化检测问题。
(3)研究结论:开展了基于风格的假新闻检测研究,构建了一个假新闻语料库,并提出了两个假新闻分类器,取得了很好的效果。
5 解决问题
(1)试图解决的问题:构建具备可解释性和强泛化能力的假新闻分类器。
(2)在关于可信度评估的研究工作中,主要存在三点不足:
- 已有的机器学习方法大多使用了具有通用目的的文本分类器算法。但是这样的方法不能让人明白可信度评估具体是基于哪些特征开展的。由于某些在训练或测试数据上提供良好性能的特征在实际应用场景中可能并不理想,因此在大多数情况下仅知道分类器做出正确决策是不够的,作者希望分类器有可解释性。
- 现有的机器学习方法往往聚焦于新闻的内容特征,主要包括来源和话题。但是假新闻的来源网站的存活时间一般很短,因此当新的来源代替它们的时候模型会失灵。并且,新闻的话题也具备很强的时效性,旧话题的热度会随着时间降低,同时也会出现一些新的话题,这也将影响模型的效果。因此基于内容的分类器其泛化能力较差。
- 现有的研究受到严格的数据量的限制,一般在几百–几千的量级,这将导致模型对训练过程中使用的主题和来源信息过拟合。
6 本文贡献
(1)提供了一个包含103,219个文档的文本语料库,涵盖了广泛的主题,来自223个已标记的来源,这是构建无偏分类器的有用资源。
(2)使用语料库构建了不同的评估场景,将其应用于训练时不具备来源和主题信息的文档。
(3)提出了两个分类器:基于风格的分类器和神经网络分类器BiLSTMAvg。
7 论文方法
详细描述本文提出的技术路线(包括但不限于方法、算法、模型等)。
- 基于风格的分类器
- 风格特征:句子数,平均句子长度(以字为单位)和平均单词长度(以字符为单位);匹配不同字母方案的单词数(全部小写、全部大写、仅第一个字母大写、其他);词性unigrams,bigrams和trigrams的频率;在扩展的 GI 词典中属于 182 个类别的词的频率。
- 分类器:过滤标签和特征的相关度低于0.05的特征,并构造逻辑回归模型,得到文档属于不可信类别的概率。
(2)神经网络分类器BiLSTMAvg:添加了一个额外的平均层,通过对文档中所有句子的类别概率得分求平均,以得到整个文档的得分。
8 实验结果
详细描述本文实验及相关结论。
- 实验场景
- 基于普通文档的 CV:每一折包含来自语料库的随机文档。
- 基于主题的 CV:每个 LDA 主题及其所属文档都被分配到某一折。此场景模拟测试文档属于全新主题的情况。
- 基于来源的 CV:每个文档源及其所属文档都被分配到某一折。此场景模拟测试具备全新来源的文章的情况。
- 实验结果1
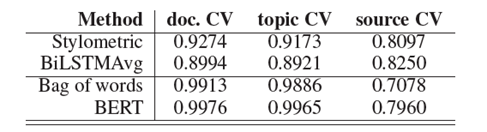
结论:
- 对比doc. CV和source CV,词袋和BERT的表现急剧下降,说明模型来源特征产生了过拟合。
- 在source CV中,BiLSTMAvg表现最佳,说明其能避免过拟合问题。
- 对比doc. CV和source CV,基于风格的分类器性能下降,原因为:未捕获到假新闻的一般风格;文本提取机制不完善。
- 对比doc. CV和topic CV,各个模型性能仅有小幅下降,说明主题CV不是挑战。
- 实验结果2
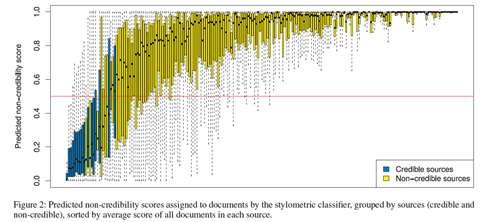
结论:
- 大部分的数据预测效果很好。
- 出现错误分类的原因:不可信来源混合了真实和虚构的报导,且文章都是从信誉良好的来源复制过来的,导致分类器将其错误分类;可信来源的写作风格类似不可信来源,导致分类器将其错误分类。
- 实验结果3

结论:黄色的突出显示为可信度较低的一些重点词汇,可以看到这些词包含了强烈的情感倾向,例如白痴,愤怒,耻辱。
- 本文不足
- 本文不足:
- 该研究最重要的局限性来自作者对可信度所做的基本假设。首先,它在源级别的评估被其中的所有文档继承。事实上,并非来自不可信来源的每份文件都包含虚假信息,就像并非来自受信任媒体的每条新闻都完全准确一样。这种对可信度的理解是否反映了假新闻的概念将取决于应用的定义——而有些依赖于所提供信息的真实性,而另一些则强调设计具有误导性。
- 其次,文档的写作风格与其在数据集中观察到的可信度之间的依赖性可能不是普遍的或永久的。可能存在一些(未来可能更多)在质量和风格方面与真实新闻媒体相当,但提供误导性内容的网站。
(2)可改进方面:
- 考虑将风格信息和社交网络上下文的信息相结合。
- 本文中的风格主要体现在词级别上,未来可以考虑更粗粒度的级别、更抽象的方面。
10 代码和数据集地址